 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSqueeze Out Tokens from Sample for Finer-Grained Data Governance
Mar 18, 2025Widely observed data scaling laws, in which error falls off as a power of the training size, demonstrate the diminishing returns of unselective data expansion. Hence, data governance is proposed to downsize datasets through pruning non-informative samples. Yet, isolating the impact of a specific sample on overall model performance is challenging, due to the vast computation required for tryout all sample combinations. Current data governors circumvent this complexity by estimating sample contributions through heuristic-derived scalar scores, thereby discarding low-value ones. Despite thorough sample sieving, retained samples contain substantial undesired tokens intrinsically, underscoring the potential for further compression and purification. In this work, we upgrade data governance from a 'sieving' approach to a 'juicing' one. Instead of scanning for least-flawed samples, our dual-branch DataJuicer applies finer-grained intra-sample governance. It squeezes out informative tokens and boosts image-text alignments. Specifically, the vision branch retains salient image patches and extracts relevant object classes, while the text branch incorporates these classes to enhance captions. Consequently, DataJuicer yields more refined datasets through finer-grained governance. Extensive experiments across datasets demonstrate that DataJuicer significantly outperforms existing DataSieve in image-text retrieval, classification, and dense visual reasoning.
Advancing Myopia To Holism: Fully Contrastive Language-Image Pre-training
Nov 30, 2024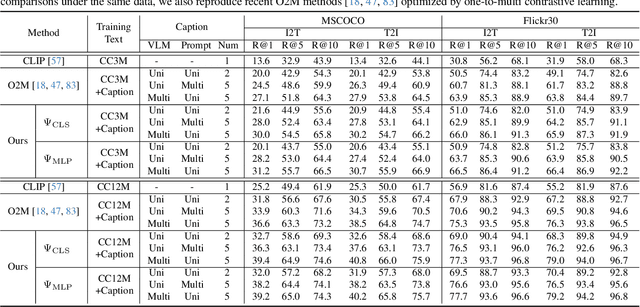
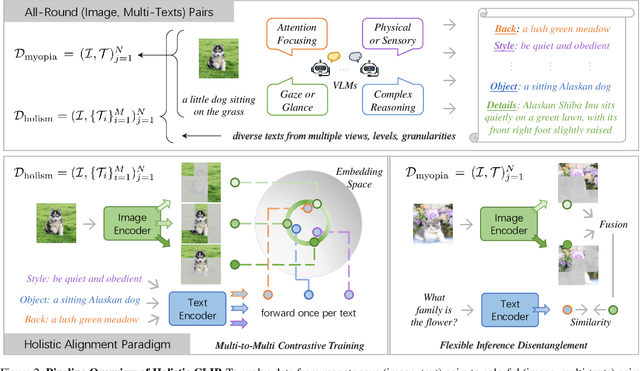
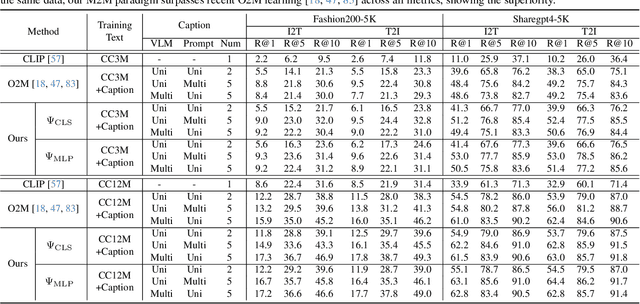
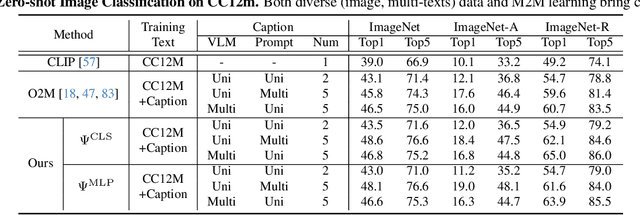
In rapidly evolving field of vision-language models (VLMs), contrastive language-image pre-training (CLIP) has made significant strides, becoming foundation for various downstream tasks. However, relying on one-to-one (image, text) contrastive paradigm to learn alignment from large-scale messy web data, CLIP faces a serious myopic dilemma, resulting in biases towards monotonous short texts and shallow visual expressivity. To overcome these issues, this paper advances CLIP into one novel holistic paradigm, by updating both diverse data and alignment optimization. To obtain colorful data with low cost, we use image-to-text captioning to generate multi-texts for each image, from multiple perspectives, granularities, and hierarchies. Two gadgets are proposed to encourage textual diversity. To match such (image, multi-texts) pairs, we modify the CLIP image encoder into multi-branch, and propose multi-to-multi contrastive optimization for image-text part-to-part matching. As a result, diverse visual embeddings are learned for each image, bringing good interpretability and generalization. Extensive experiments and ablations across over ten benchmarks indicate that our holistic CLIP significantly outperforms existing myopic CLIP, including image-text retrieval, open-vocabulary classification, and dense visual tasks.
Zero-shot Image Editing with Reference Imitation
Jun 11, 2024



Image editing serves as a practical yet challenging task considering the diverse demands from users, where one of the hardest parts is to precisely describe how the edited image should look like. In this work, we present a new form of editing, termed imitative editing, to help users exercise their creativity more conveniently. Concretely, to edit an image region of interest, users are free to directly draw inspiration from some in-the-wild references (e.g., some relative pictures come across online), without having to cope with the fit between the reference and the source. Such a design requires the system to automatically figure out what to expect from the reference to perform the editing. For this purpose, we propose a generative training framework, dubbed MimicBrush, which randomly selects two frames from a video clip, masks some regions of one frame, and learns to recover the masked regions using the information from the other frame. That way, our model, developed from a diffusion prior, is able to capture the semantic correspondence between separate images in a self-supervised manner. We experimentally show the effectiveness of our method under various test cases as well as its superiority over existing alternatives. We also construct a benchmark to facilitate further research.
Tunnel Try-on: Excavating Spatial-temporal Tunnels for High-quality Virtual Try-on in Videos
Apr 26, 2024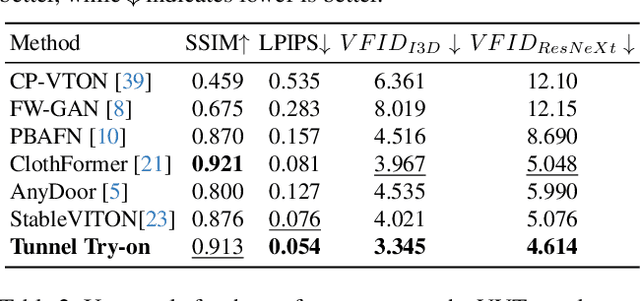
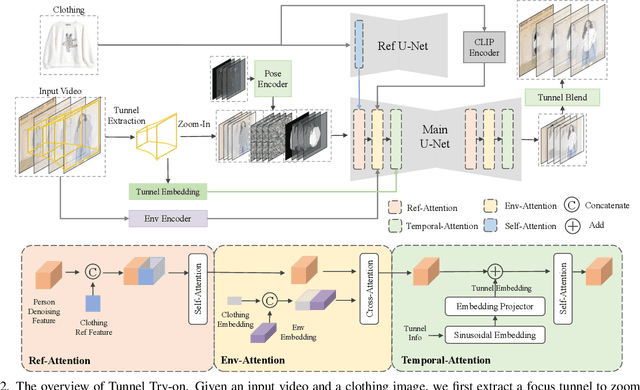
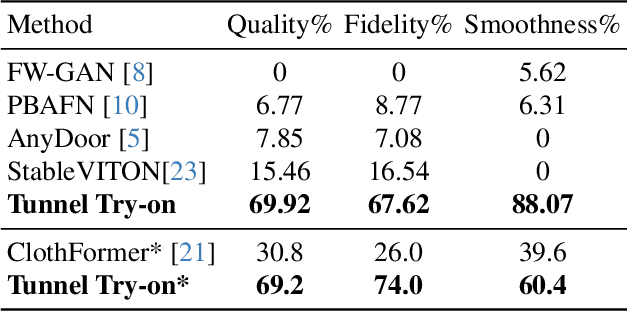

Video try-on is a challenging task and has not been well tackled in previous works. The main obstacle lies in preserving the details of the clothing and modeling the coherent motions simultaneously. Faced with those difficulties, we address video try-on by proposing a diffusion-based framework named "Tunnel Try-on." The core idea is excavating a "focus tunnel" in the input video that gives close-up shots around the clothing regions. We zoom in on the region in the tunnel to better preserve the fine details of the clothing. To generate coherent motions, we first leverage the Kalman filter to construct smooth crops in the focus tunnel and inject the position embedding of the tunnel into attention layers to improve the continuity of the generated videos. In addition, we develop an environment encoder to extract the context information outside the tunnels as supplementary cues. Equipped with these techniques, Tunnel Try-on keeps the fine details of the clothing and synthesizes stable and smooth videos. Demonstrating significant advancements, Tunnel Try-on could be regarded as the first attempt toward the commercial-level application of virtual try-on in videos.
DENOISER: Rethinking the Robustness for Open-Vocabulary Action Recognition
Apr 23, 2024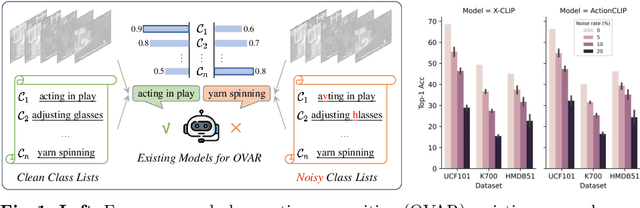
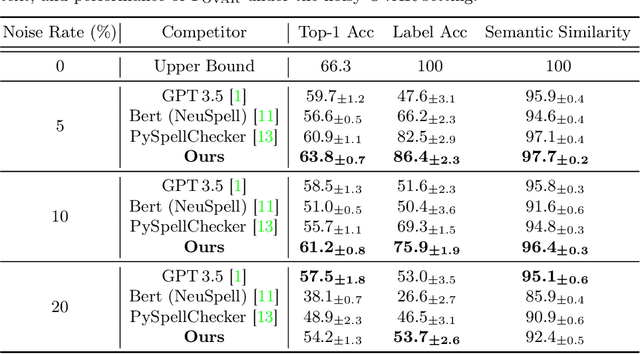
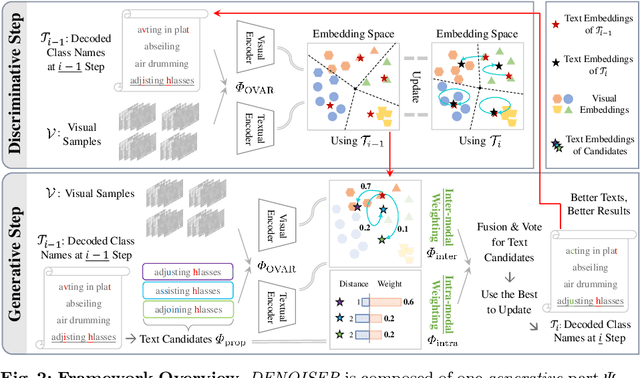
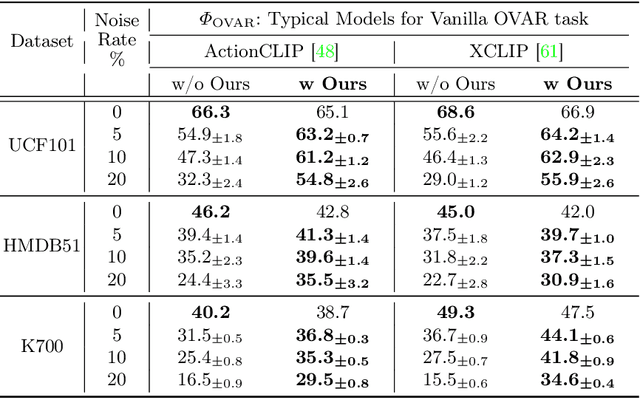
As one of the fundamental video tasks in computer vision, Open-Vocabulary Action Recognition (OVAR) recently gains increasing attention, with the development of vision-language pre-trainings. To enable generalization of arbitrary classes, existing methods treat class labels as text descriptions, then formulate OVAR as evaluating embedding similarity between visual samples and textual classes. However, one crucial issue is completely ignored: the class descriptions given by users may be noisy, e.g., misspellings and typos, limiting the real-world practicality of vanilla OVAR. To fill the research gap, this paper pioneers to evaluate existing methods by simulating multi-level noises of various types, and reveals their poor robustness. To tackle the noisy OVAR task, we further propose one novel DENOISER framework, covering two parts: generation and discrimination. Concretely, the generative part denoises noisy class-text names via one decoding process, i.e., propose text candidates, then utilize inter-modal and intra-modal information to vote for the best. At the discriminative part, we use vanilla OVAR models to assign visual samples to class-text names, thus obtaining more semantics. For optimization, we alternately iterate between generative and discriminative parts for progressive refinements. The denoised text classes help OVAR models classify visual samples more accurately; in return, classified visual samples help better denoising. On three datasets, we carry out extensive experiments to show our superior robustness, and thorough ablations to dissect the effectiveness of each component.
Wear-Any-Way: Manipulable Virtual Try-on via Sparse Correspondence Alignment
Mar 19, 2024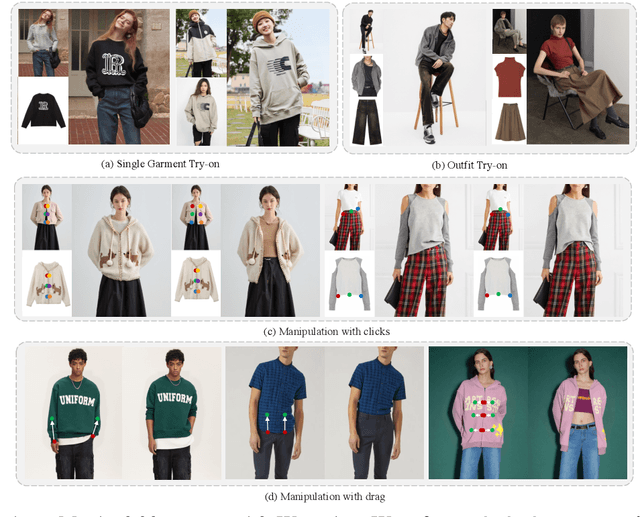

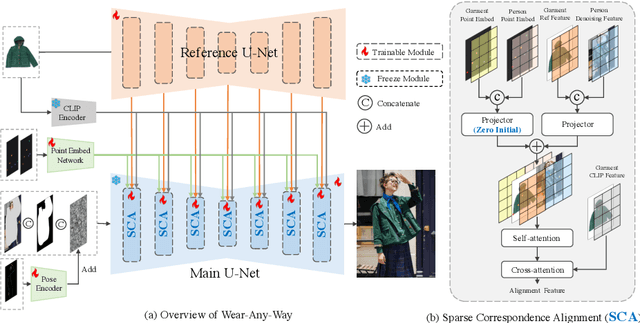
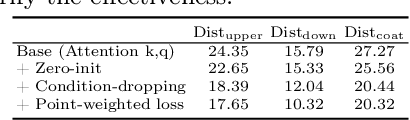
This paper introduces a novel framework for virtual try-on, termed Wear-Any-Way. Different from previous methods, Wear-Any-Way is a customizable solution. Besides generating high-fidelity results, our method supports users to precisely manipulate the wearing style. To achieve this goal, we first construct a strong pipeline for standard virtual try-on, supporting single/multiple garment try-on and model-to-model settings in complicated scenarios. To make it manipulable, we propose sparse correspondence alignment which involves point-based control to guide the generation for specific locations. With this design, Wear-Any-Way gets state-of-the-art performance for the standard setting and provides a novel interaction form for customizing the wearing style. For instance, it supports users to drag the sleeve to make it rolled up, drag the coat to make it open, and utilize clicks to control the style of tuck, etc. Wear-Any-Way enables more liberated and flexible expressions of the attires, holding profound implications in the fashion industry.
LivePhoto: Real Image Animation with Text-guided Motion Control
Dec 05, 2023



Despite the recent progress in text-to-video generation, existing studies usually overlook the issue that only spatial contents but not temporal motions in synthesized videos are under the control of text. Towards such a challenge, this work presents a practical system, named LivePhoto, which allows users to animate an image of their interest with text descriptions. We first establish a strong baseline that helps a well-learned text-to-image generator (i.e., Stable Diffusion) take an image as a further input. We then equip the improved generator with a motion module for temporal modeling and propose a carefully designed training pipeline to better link texts and motions. In particular, considering the facts that (1) text can only describe motions roughly (e.g., regardless of the moving speed) and (2) text may include both content and motion descriptions, we introduce a motion intensity estimation module as well as a text re-weighting module to reduce the ambiguity of text-to-motion mapping. Empirical evidence suggests that our approach is capable of well decoding motion-related textual instructions into videos, such as actions, camera movements, or even conjuring new contents from thin air (e.g., pouring water into an empty glass). Interestingly, thanks to the proposed intensity learning mechanism, our system offers users an additional control signal (i.e., the motion intensity) besides text for video customization.
Learning to Focus: Cascaded Feature Matching Network for Few-shot Image Recognition
Jan 13, 2021

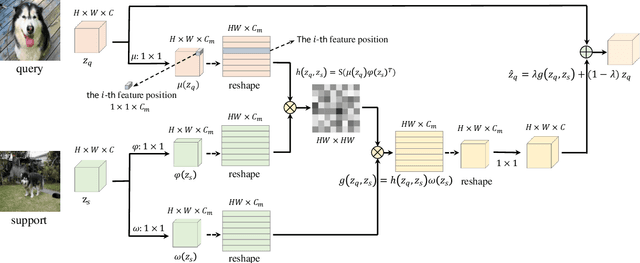

Deep networks can learn to accurately recognize objects of a category by training on a large number of annotated images. However, a meta-learning challenge known as a low-shot image recognition task comes when only a few images with annotations are available for learning a recognition model for one category. The objects in testing/query and training/support images are likely to be different in size, location, style, and so on. Our method, called Cascaded Feature Matching Network (CFMN), is proposed to solve this problem. We train the meta-learner to learn a more fine-grained and adaptive deep distance metric by focusing more on the features that have high correlations between compared images by the feature matching block which can align associated features together and naturally ignore those non-discriminative features. By applying the proposed feature matching block in different layers of the few-shot recognition network, multi-scale information among the compared images can be incorporated into the final cascaded matching feature, which boosts the recognition performance further and generalizes better by learning on relationships. The experiments for few-shot learning on two standard datasets, \emph{mini}ImageNet and Omniglot, have confirmed the effectiveness of our method. Besides, the multi-label few-shot task is first studied on a new data split of COCO which further shows the superiority of the proposed feature matching network when performing few-shot learning in complex images. The code will be made publicly available.
* 14 pages
Diversity Transfer Network for Few-Shot Learning
Dec 31, 2019

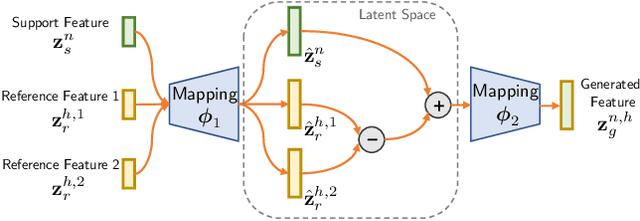
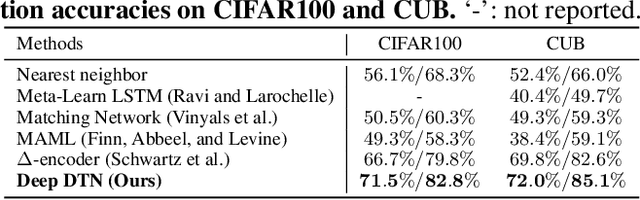
Few-shot learning is a challenging task that aims at training a classifier for unseen classes with only a few training examples. The main difficulty of few-shot learning lies in the lack of intra-class diversity within insufficient training samples. To alleviate this problem, we propose a novel generative framework, Diversity Transfer Network (DTN), that learns to transfer latent diversities from known categories and composite them with support features to generate diverse samples for novel categories in feature space. The learning problem of the sample generation (i.e., diversity transfer) is solved via minimizing an effective meta-classification loss in a single-stage network, instead of the generative loss in previous works. Besides, an organized auxiliary task co-training over known categories is proposed to stabilize the meta-training process of DTN. We perform extensive experiments and ablation studies on three datasets, i.e., \emph{mini}ImageNet, CIFAR100 and CUB. The results show that DTN, with single-stage training and faster convergence speed, obtains the state-of-the-art results among the feature generation based few-shot learning methods. Code and supplementary material are available at: \texttt{https://github.com/Yuxin-CV/DTN}