 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFC-Track: Overlap-Aware Post-Association Correction for Online Multi-Object Tracking
Mar 13, 2026Reliable multi-object tracking (MOT) is essential for robotic systems operating in complex and dynamic environments. Despite recent advances in detection and association, online MOT methods remain vulnerable to identity switches caused by frequent occlusions and object overlap, where incorrect associations can propagate over time and degrade tracking reliability. We present a lightweight post-association correction framework (FC-Track) for online MOT that explicitly targets overlap-induced mismatches during inference. The proposed method suppresses unreliable appearance updates under high-overlap conditions using an Intersection over Area (IoA)-based filtering strategy, and locally corrects detection-to-tracklet mismatches through appearance similarity comparison within overlapped tracklet pairs. By preventing short-term mismatches from propagating, our framework effectively mitigates long-term identity switches without resorting to global optimization or re-identification. The framework operates online without global optimization or re-identification, making it suitable for real-time robotic applications. We achieve 81.73 MOTA, 82.81 IDF1, and 66.95 HOTA on the MOT17 test set with a running speed of 5.7 FPS, and 77.52 MOTA, 80.90 IDF1, and 65.67 HOTA on the MOT20 test set with a running speed of 0.6 FPS. Specifically, our framework FC-Track produces only 29.55% long-term identity switches, which is substantially lower than existing online trackers. Meanwhile, our framework maintains state-of-the-art performance on the MOT20 benchmark.
The FM Agent
Oct 30, 2025Large language models (LLMs) are catalyzing the development of autonomous AI research agents for scientific and engineering discovery. We present FM Agent, a novel and general-purpose multi-agent framework that leverages a synergistic combination of LLM-based reasoning and large-scale evolutionary search to address complex real-world challenges. The core of FM Agent integrates several key innovations: 1) a cold-start initialization phase incorporating expert guidance, 2) a novel evolutionary sampling strategy for iterative optimization, 3) domain-specific evaluators that combine correctness, effectiveness, and LLM-supervised feedback, and 4) a distributed, asynchronous execution infrastructure built on Ray. Demonstrating broad applicability, our system has been evaluated across diverse domains, including operations research, machine learning, GPU kernel optimization, and classical mathematical problems. FM Agent reaches state-of-the-art results autonomously, without human interpretation or tuning -- 1976.3 on ALE-Bench (+5.2\%), 43.56\% on MLE-Bench (+4.0pp), up to 20x speedups on KernelBench, and establishes new state-of-the-art(SOTA) results on several classical mathematical problems. Beyond academic benchmarks, FM Agent shows considerable promise for both large-scale enterprise R\&D workflows and fundamental scientific research, where it can accelerate innovation, automate complex discovery processes, and deliver substantial engineering and scientific advances with broader societal impact.
DENOISER: Rethinking the Robustness for Open-Vocabulary Action Recognition
Apr 23, 2024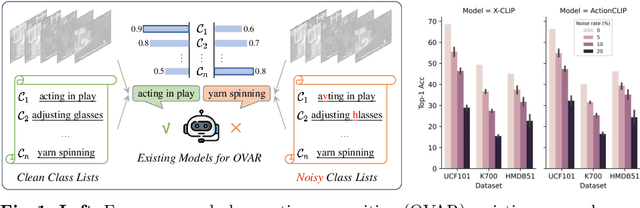
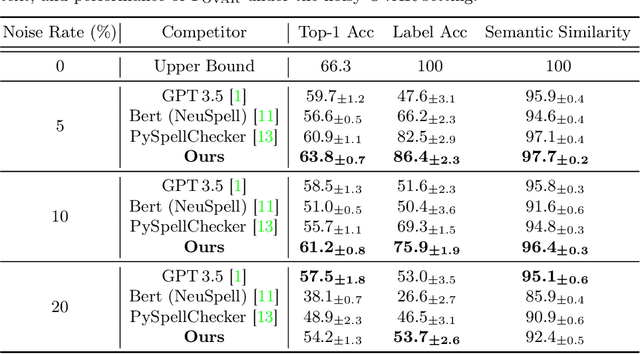
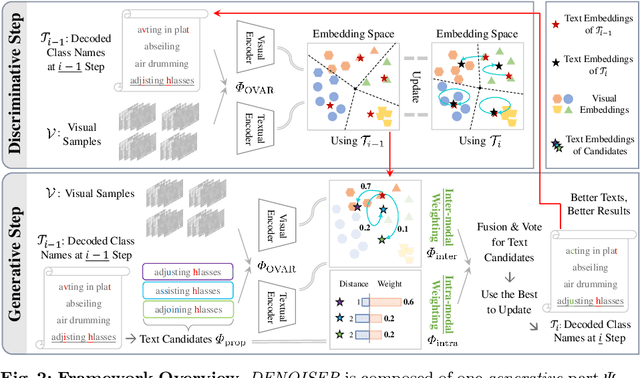
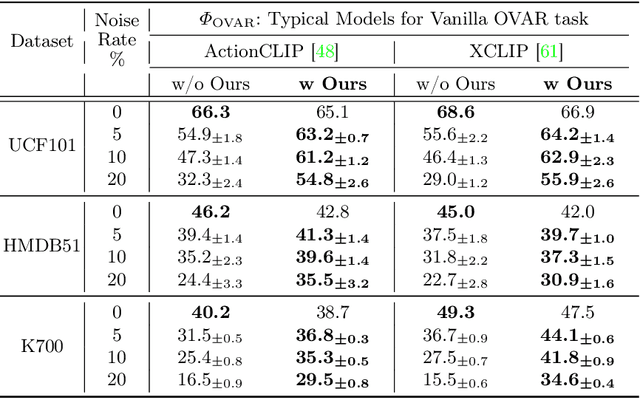
As one of the fundamental video tasks in computer vision, Open-Vocabulary Action Recognition (OVAR) recently gains increasing attention, with the development of vision-language pre-trainings. To enable generalization of arbitrary classes, existing methods treat class labels as text descriptions, then formulate OVAR as evaluating embedding similarity between visual samples and textual classes. However, one crucial issue is completely ignored: the class descriptions given by users may be noisy, e.g., misspellings and typos, limiting the real-world practicality of vanilla OVAR. To fill the research gap, this paper pioneers to evaluate existing methods by simulating multi-level noises of various types, and reveals their poor robustness. To tackle the noisy OVAR task, we further propose one novel DENOISER framework, covering two parts: generation and discrimination. Concretely, the generative part denoises noisy class-text names via one decoding process, i.e., propose text candidates, then utilize inter-modal and intra-modal information to vote for the best. At the discriminative part, we use vanilla OVAR models to assign visual samples to class-text names, thus obtaining more semantics. For optimization, we alternately iterate between generative and discriminative parts for progressive refinements. The denoised text classes help OVAR models classify visual samples more accurately; in return, classified visual samples help better denoising. On three datasets, we carry out extensive experiments to show our superior robustness, and thorough ablations to dissect the effectiveness of each component.
Extending iLQR method with control delay
Feb 16, 2020Iterative linear quadradic regulator(iLQR) has become a benchmark method to deal with nonlinear stochastic optimal control problem. However, it does not apply to delay system. In this paper, we extend the iLQR theory and prove new theorem in case of input signal with fixed delay. Which could be beneficial for machine learning or optimal control application to real time robot or human assistive device.
Semisupervised Learning on Heterogeneous Graphs and its Applications to Facebook News Feed
Jul 05, 2018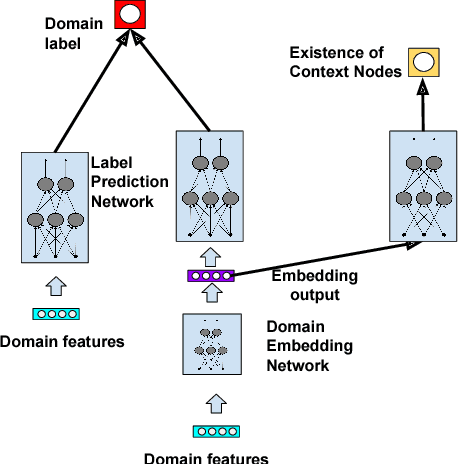
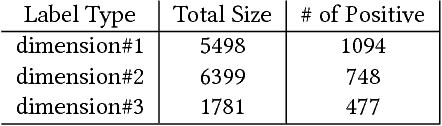
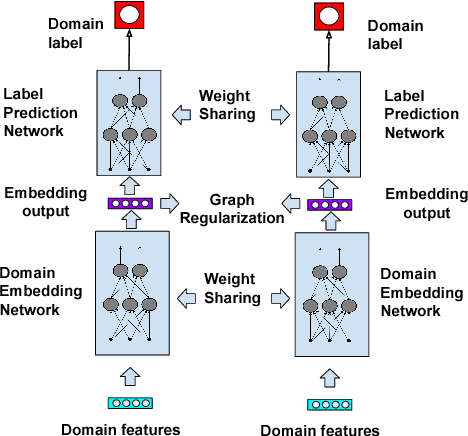
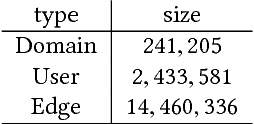
Graph-based semi-supervised learning is a fundamental machine learning problem, and has been well studied. Most studies focus on homogeneous networks (e.g. citation network, friend network). In the present paper, we propose the Heterogeneous Embedding Label Propagation (HELP) algorithm, a graph-based semi-supervised deep learning algorithm, for graphs that are characterized by heterogeneous node types. Empirically, we demonstrate the effectiveness of this method in domain classification tasks with Facebook user-domain interaction graph, and compare the performance of the proposed HELP algorithm with the state of the art algorithms. We show that the HELP algorithm improves the predictive performance across multiple tasks, together with semantically meaningful embedding that are discriminative for downstream classification or regression tasks.
Flexible Collaborative Estimation of the Average Causal Effect of a Treatment using the Outcome-Highly-Adaptive Lasso
Jun 20, 2018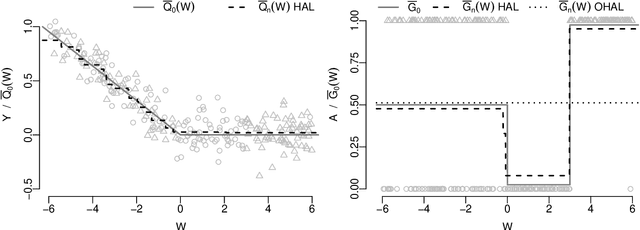
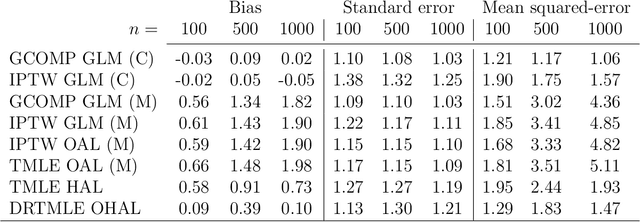
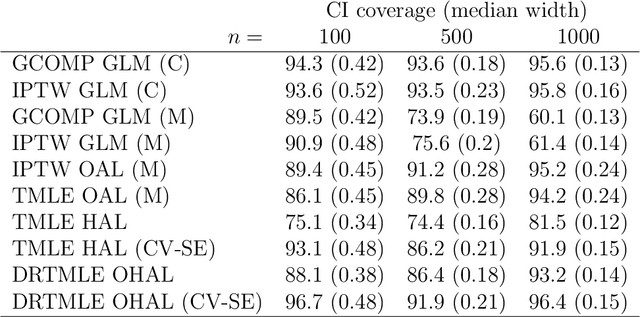
Many estimators of the average causal effect of an intervention require estimation of the propensity score, the outcome regression, or both. For these estimators, we must carefully con- sider how to estimate the relevant regressions. It is often beneficial to utilize flexible techniques such as semiparametric regression or machine learning. However, optimal estimation of the regression function does not necessarily lead to optimal estimation of the average causal effect. Therefore, it is important to consider criteria for evaluating regression estimators and selecting hyper-parameters. A recent proposal addressed these issues via the outcome-adaptive lasso, a penalized regression technique for estimating the propensity score. We build on this proposal and offer a method that is simultaneously more flexible and more efficient than the previous pro- posal. We propose the outcome-highly-adaptive LASSO, a semi-parametric regression estimator designed to down-weight regions of the confounder space that do not contribute variation to the outcome regression. We show that tuning this method using collaborative targeted learning leads to superior finite-sample performance relative to competing estimators.
Collaborative targeted inference from continuously indexed nuisance parameter estimators
Apr 05, 2018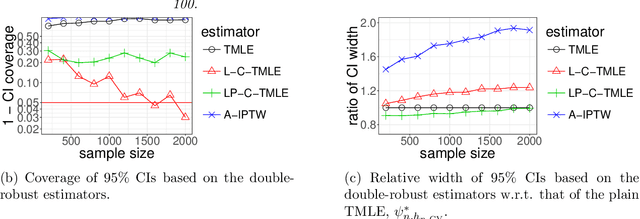
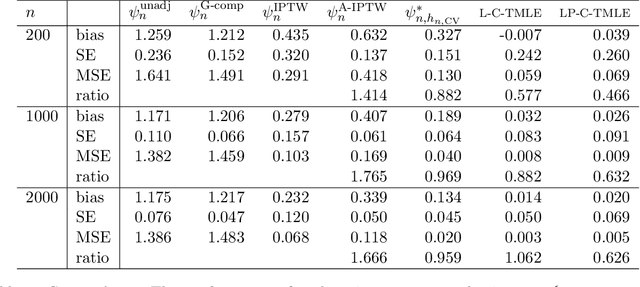
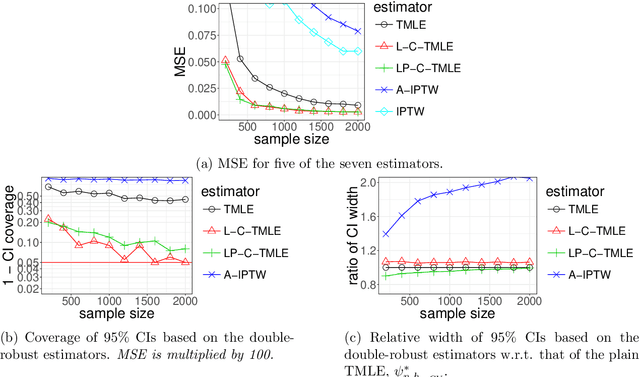
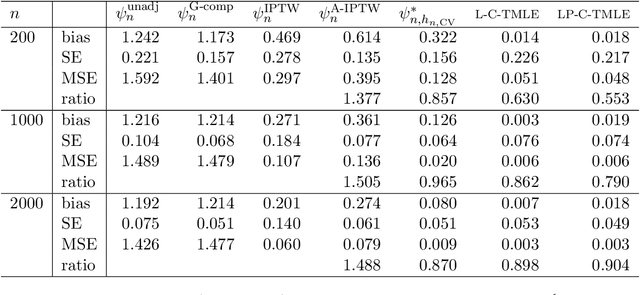
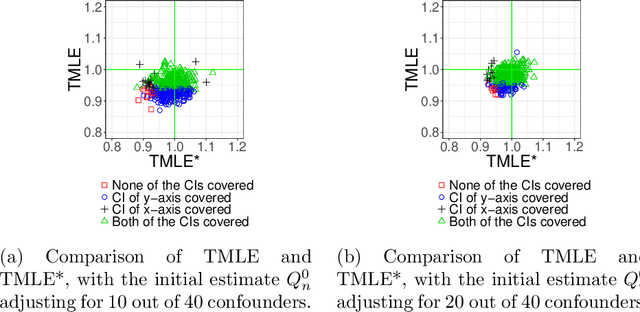
We wish to infer the value of a parameter at a law from which we sample independent observations. The parameter is smooth and we can define two variation-independent features of the law, its $Q$- and $G$-components, such that estimating them consistently at a fast enough product of rates allows to build a confidence interval (CI) with a given asymptotic level from a plain targeted minimum loss estimator (TMLE). Say that the above product is not fast enough and the algorithm for the $G$-component is fine-tuned by a real-valued $h$. A plain TMLE with an $h$ chosen by cross-validation would typically not yield a CI. We construct a collaborative TMLE (C-TMLE) and show under mild conditions that, if there exists an oracle $h$ that makes a bulky remainder term asymptotically Gaussian, then the C-TMLE yields a CI. We illustrate our findings with the inference of the average treatment effect. We conduct a simulation study where the $G$-component is estimated by the LASSO and $h$ is the bound on the coefficients' norms. It sheds light on small sample properties, in the face of low- to high-dimensional baseline covariates, and possibly positivity violation.
On Adaptive Propensity Score Truncation in Causal Inference
Jul 18, 2017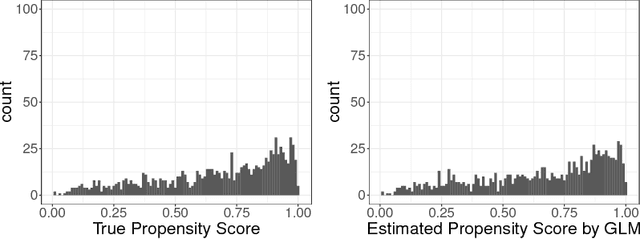
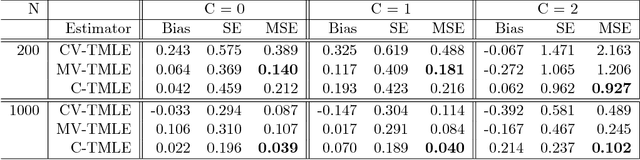
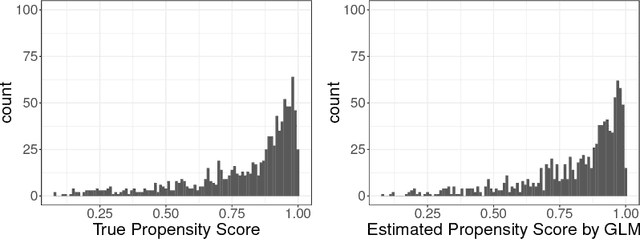
The positivity assumption, or the experimental treatment assignment (ETA) assumption, is important for identifiability in causal inference. Even if the positivity assumption holds, practical violations of this assumption may jeopardize the finite sample performance of the causal estimator. One of the consequences of practical violations of the positivity assumption is extreme values in the estimated propensity score (PS). A common practice to address this issue is truncating the PS estimate when constructing PS-based estimators. In this study, we propose a novel adaptive truncation method, Positivity-C-TMLE, based on the collaborative targeted maximum likelihood estimation (C-TMLE) methodology. We demonstrate the outstanding performance of our novel approach in a variety of simulations by comparing it with other commonly studied estimators. Results show that by adaptively truncating the estimated PS with a more targeted objective function, the Positivity-C-TMLE estimator achieves the best performance for both point estimation and confidence interval coverage among all estimators considered.
Collaborative-controlled LASSO for Constructing Propensity Score-based Estimators in High-Dimensional Data
Jun 30, 2017
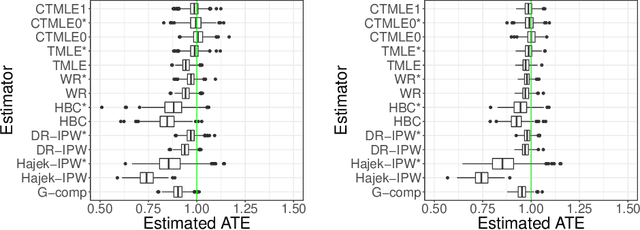
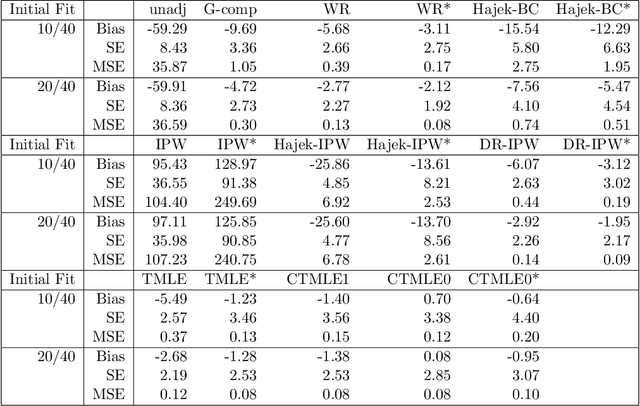
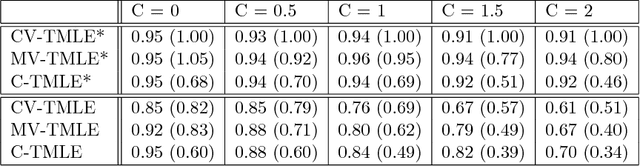
Propensity score (PS) based estimators are increasingly used for causal inference in observational studies. However, model selection for PS estimation in high-dimensional data has received little attention. In these settings, PS models have traditionally been selected based on the goodness-of-fit for the treatment mechanism itself, without consideration of the causal parameter of interest. Collaborative minimum loss-based estimation (C-TMLE) is a novel methodology for causal inference that takes into account information on the causal parameter of interest when selecting a PS model. This "collaborative learning" considers variable associations with both treatment and outcome when selecting a PS model in order to minimize a bias-variance trade off in the estimated treatment effect. In this study, we introduce a novel approach for collaborative model selection when using the LASSO estimator for PS estimation in high-dimensional covariate settings. To demonstrate the importance of selecting the PS model collaboratively, we designed quasi-experiments based on a real electronic healthcare database, where only the potential outcomes were manually generated, and the treatment and baseline covariates remained unchanged. Results showed that the C-TMLE algorithm outperformed other competing estimators for both point estimation and confidence interval coverage. In addition, the PS model selected by C-TMLE could be applied to other PS-based estimators, which also resulted in substantive improvement for both point estimation and confidence interval coverage. We illustrate the discussed concepts through an empirical example comparing the effects of non-selective nonsteroidal anti-inflammatory drugs with selective COX-2 inhibitors on gastrointestinal complications in a population of Medicare beneficiaries.
The Relative Performance of Ensemble Methods with Deep Convolutional Neural Networks for Image Classification
Apr 05, 2017

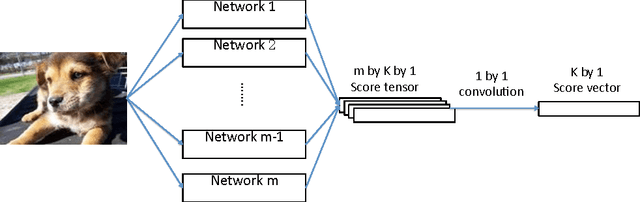
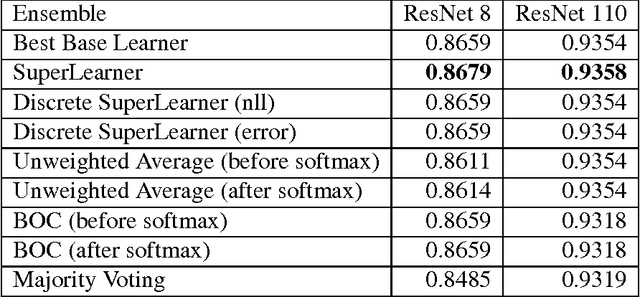
Artificial neural networks have been successfully applied to a variety of machine learning tasks, including image recognition, semantic segmentation, and machine translation. However, few studies fully investigated ensembles of artificial neural networks. In this work, we investigated multiple widely used ensemble methods, including unweighted averaging, majority voting, the Bayes Optimal Classifier, and the (discrete) Super Learner, for image recognition tasks, with deep neural networks as candidate algorithms. We designed several experiments, with the candidate algorithms being the same network structure with different model checkpoints within a single training process, networks with same structure but trained multiple times stochastically, and networks with different structure. In addition, we further studied the over-confidence phenomenon of the neural networks, as well as its impact on the ensemble methods. Across all of our experiments, the Super Learner achieved best performance among all the ensemble methods in this study.