 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and Estimating Causal Direct Effects Under Unmeasured Confounding
Apr 02, 2026Causal mediation analysis provides techniques for defining and estimating effects that may be endowed with mechanistic interpretations. With many scientific investigations seeking to address mechanistic questions, causal direct and indirect effects have garnered much attention. The natural direct and indirect effects, the most widely used among such causal mediation estimands, are limited in their practical utility due to stringent identification requirements. Accordingly, considerable effort has been invested in developing alternative direct and indirect effect decompositions with relaxed identification requirements. Such efforts often yield effect definitions with nuanced and challenging interpretations. By contrast, relatively limited attention has been paid to relaxing the identification assumptions of the natural direct and indirect effects. Motivated by a secondary aim of a recent non-randomized vaccine prospective cohort study (NCT05168813), we present a set of relaxed conditions under which the natural direct effect is identifiable in spite of unobserved baseline confounding of the exposure-mediator pathway; we use this result to investigate the effect mediated by putative immune correlates of protection. Relaxing the commonly used but restrictive cross-world counterfactual independence assumption, we discuss strategies for evaluating the natural direct effect in non-randomized settings that arise in the analysis of vaccine studies. We revisit prior studies of semi-parametric efficiency theory to demonstrate the construction of flexible, multiply robust estimators of the natural direct effect and discuss efficient estimation strategies that do not place restrictive modeling assumptions on nuisance functions.
Efficient Targeted Maximum Likelihood Estimators for Two-Phase Design Problems
Feb 27, 2026In a typical two-phase design, a random sample is drawn from the target population in phase 1, during which only a subset of variables is collected. In phase 2, a subsample of the phase-1 cohort is selected, and additional variables are measured. This setting induces a coarsened data structure on the data from the second phase. We assume coarsening at random, that is, the phase-2 sampling mechanism depends only on variables fully observed. We review existing estimators, including the generalized raking estimator and the inverse probability of censoring weighted targeted maximum likelihood estimation (IPCW-TMLE) along with its extensions that also target the phase-2 sampling mechanism to improve efficiency. We further introduce a new class of estimators constructed within the TMLE framework that are asymptotically equivalent.
Machine learning to optimize precision in the analysis of randomized trials: A journey in pre-specified, yet data-adaptive learning
Dec 15, 2025Covariate adjustment is an approach to improve the precision of trial analyses by adjusting for baseline variables that are prognostic of the primary endpoint. Motivated by the SEARCH Universal HIV Test-and-Treat Trial (2013-2017), we tell our story of developing, evaluating, and implementing a machine learning-based approach for covariate adjustment. We provide the rationale for as well as the practical concerns with such an approach for estimating marginal effects. Using schematics, we illustrate our procedure: targeted machine learning estimation (TMLE) with Adaptive Pre-specification. Briefly, sample-splitting is used to data-adaptively select the combination of estimators of the outcome regression (i.e., the conditional expectation of the outcome given the trial arm and covariates) and known propensity score (i.e., the conditional probability of being randomized to the intervention given the covariates) that minimizes the cross-validated variance estimate and, thereby, maximizes empirical efficiency. We discuss our approach for evaluating finite sample performance with parametric and plasmode simulations, pre-specifying the Statistical Analysis Plan, and unblinding in real-time on video conference with our colleagues from around the world. We present the results from applying our approach in the primary, pre-specified analysis of 8 recently published trials (2022-2024). We conclude with practical recommendations and an invitation to implement our approach in the primary analysis of your next trial.
Statistical learning for constrained functional parameters in infinite-dimensional models with applications in fair machine learning
Apr 15, 2024

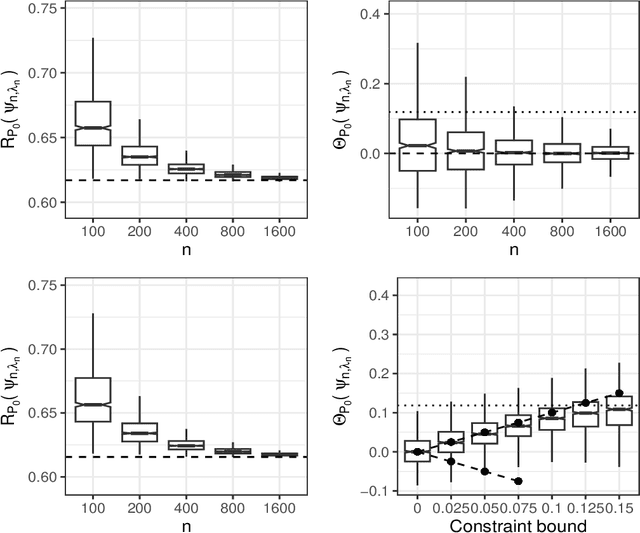
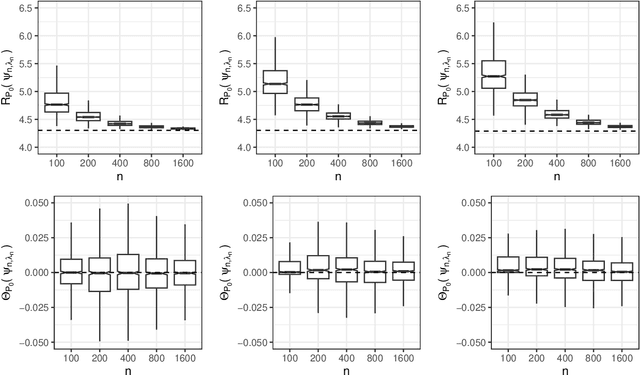
Constrained learning has become increasingly important, especially in the realm of algorithmic fairness and machine learning. In these settings, predictive models are developed specifically to satisfy pre-defined notions of fairness. Here, we study the general problem of constrained statistical machine learning through a statistical functional lens. We consider learning a function-valued parameter of interest under the constraint that one or several pre-specified real-valued functional parameters equal zero or are otherwise bounded. We characterize the constrained functional parameter as the minimizer of a penalized risk criterion using a Lagrange multiplier formulation. We show that closed-form solutions for the optimal constrained parameter are often available, providing insight into mechanisms that drive fairness in predictive models. Our results also suggest natural estimators of the constrained parameter that can be constructed by combining estimates of unconstrained parameters of the data generating distribution. Thus, our estimation procedure for constructing fair machine learning algorithms can be applied in conjunction with any statistical learning approach and off-the-shelf software. We demonstrate the generality of our method by explicitly considering a number of examples of statistical fairness constraints and implementing the approach using several popular learning approaches.
Nonparametric estimation of a covariate-adjusted counterfactual treatment regimen response curve
Sep 28, 2023Flexible estimation of the mean outcome under a treatment regimen (i.e., value function) is the key step toward personalized medicine. We define our target parameter as a conditional value function given a set of baseline covariates which we refer to as a stratum based value function. We focus on semiparametric class of decision rules and propose a sieve based nonparametric covariate adjusted regimen-response curve estimator within that class. Our work contributes in several ways. First, we propose an inverse probability weighted nonparametrically efficient estimator of the smoothed regimen-response curve function. We show that asymptotic linearity is achieved when the nuisance functions are undersmoothed sufficiently. Asymptotic and finite sample criteria for undersmoothing are proposed. Second, using Gaussian process theory, we propose simultaneous confidence intervals for the smoothed regimen-response curve function. Third, we provide consistency and convergence rate for the optimizer of the regimen-response curve estimator; this enables us to estimate an optimal semiparametric rule. The latter is important as the optimizer corresponds with the optimal dynamic treatment regimen. Some finite-sample properties are explored with simulations.
Multi-task Highly Adaptive Lasso
Jan 27, 2023
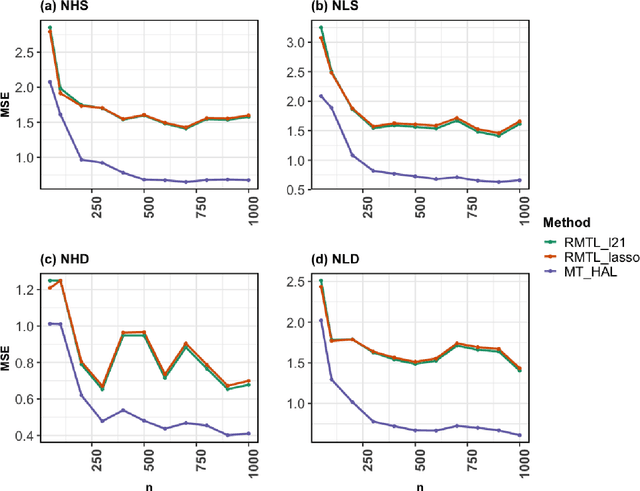


We propose a novel, fully nonparametric approach for the multi-task learning, the Multi-task Highly Adaptive Lasso (MT-HAL). MT-HAL simultaneously learns features, samples and task associations important for the common model, while imposing a shared sparse structure among similar tasks. Given multiple tasks, our approach automatically finds a sparse sharing structure. The proposed MTL algorithm attains a powerful dimension-free convergence rate of $o_p(n^{-1/4})$ or better. We show that MT-HAL outperforms sparsity-based MTL competitors across a wide range of simulation studies, including settings with nonlinear and linear relationships, varying levels of sparsity and task correlations, and different numbers of covariates and sample size.
Adaptive Sequential Surveillance with Network and Temporal Dependence
Dec 05, 2022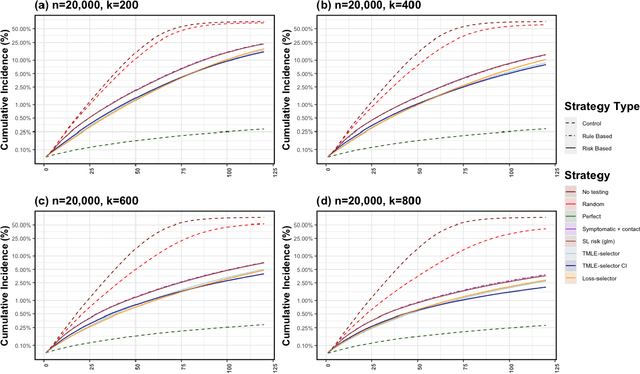

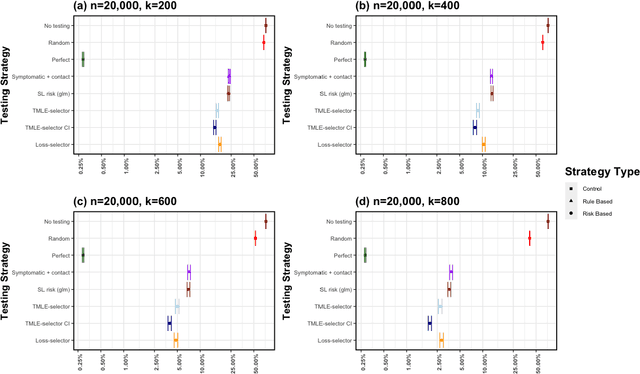
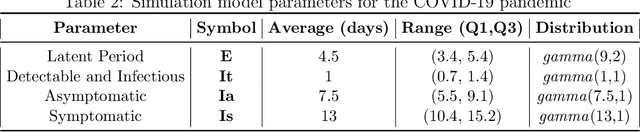
Strategic test allocation plays a major role in the control of both emerging and existing pandemics (e.g., COVID-19, HIV). Widespread testing supports effective epidemic control by (1) reducing transmission via identifying cases, and (2) tracking outbreak dynamics to inform targeted interventions. However, infectious disease surveillance presents unique statistical challenges. For instance, the true outcome of interest - one's positive infectious status, is often a latent variable. In addition, presence of both network and temporal dependence reduces the data to a single observation. As testing entire populations regularly is neither efficient nor feasible, standard approaches to testing recommend simple rule-based testing strategies (e.g., symptom based, contact tracing), without taking into account individual risk. In this work, we study an adaptive sequential design involving n individuals over a period of {\tau} time-steps, which allows for unspecified dependence among individuals and across time. Our causal target parameter is the mean latent outcome we would have obtained after one time-step, if, starting at time t given the observed past, we had carried out a stochastic intervention that maximizes the outcome under a resource constraint. We propose an Online Super Learner for adaptive sequential surveillance that learns the optimal choice of tests strategies over time while adapting to the current state of the outbreak. Relying on a series of working models, the proposed method learns across samples, through time, or both: based on the underlying (unknown) structure in the data. We present an identification result for the latent outcome in terms of the observed data, and demonstrate the superior performance of the proposed strategy in a simulation modeling a residential university environment during the COVID-19 pandemic.
Why Machine Learning Cannot Ignore Maximum Likelihood Estimation
Oct 23, 2021The growth of machine learning as a field has been accelerating with increasing interest and publications across fields, including statistics, but predominantly in computer science. How can we parse this vast literature for developments that exemplify the necessary rigor? How many of these manuscripts incorporate foundational theory to allow for statistical inference? Which advances have the greatest potential for impact in practice? One could posit many answers to these queries. Here, we assert that one essential idea is for machine learning to integrate maximum likelihood for estimation of functional parameters, such as prediction functions and conditional densities.
Personalized Online Machine Learning
Sep 21, 2021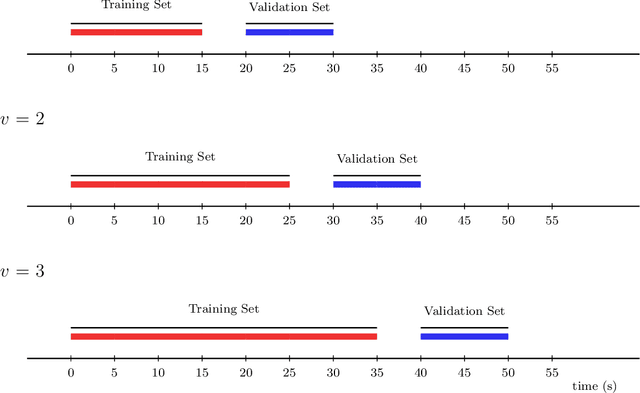
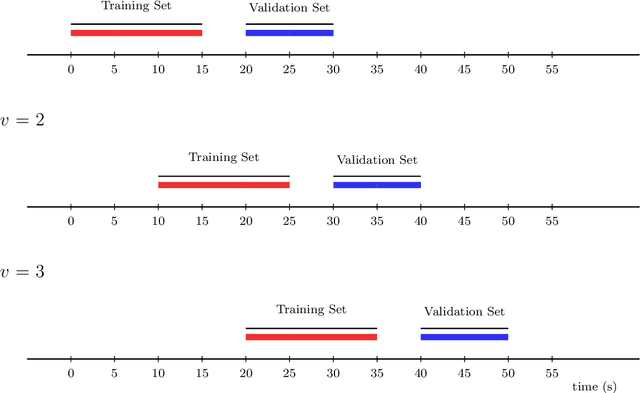
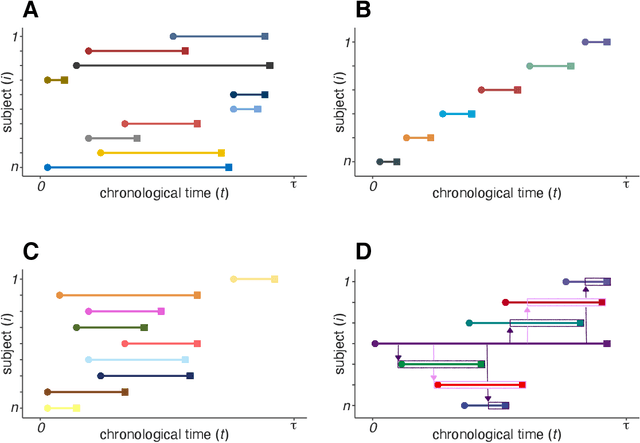
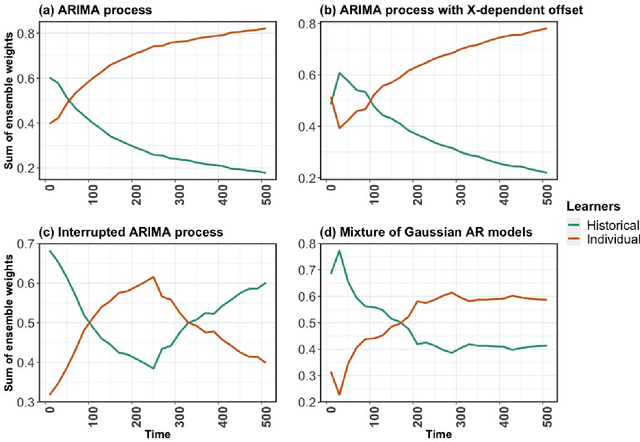
In this work, we introduce the Personalized Online Super Learner (POSL) -- an online ensembling algorithm for streaming data whose optimization procedure accommodates varying degrees of personalization. Namely, POSL optimizes predictions with respect to baseline covariates, so personalization can vary from completely individualized (i.e., optimization with respect to baseline covariate subject ID) to many individuals (i.e., optimization with respect to common baseline covariates). As an online algorithm, POSL learns in real-time. POSL can leverage a diversity of candidate algorithms, including online algorithms with different training and update times, fixed algorithms that are never updated during the procedure, pooled algorithms that learn from many individuals' time-series, and individualized algorithms that learn from within a single time-series. POSL's ensembling of this hybrid of base learning strategies depends on the amount of data collected, the stationarity of the time-series, and the mutual characteristics of a group of time-series. In essence, POSL decides whether to learn across samples, through time, or both, based on the underlying (unknown) structure in the data. For a wide range of simulations that reflect realistic forecasting scenarios, and in a medical data application, we examine the performance of POSL relative to other current ensembling and online learning methods. We show that POSL is able to provide reliable predictions for time-series data and adjust to changing data-generating environments. We further cultivate POSL's practicality by extending it to settings where time-series enter/exit dynamically over chronological time.
Adaptive Sequential Design for a Single Time-Series
Jan 29, 2021
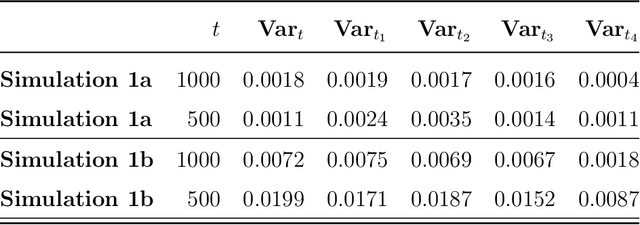
The current work is motivated by the need for robust statistical methods for precision medicine; as such, we address the need for statistical methods that provide actionable inference for a single unit at any point in time. We aim to learn an optimal, unknown choice of the controlled components of the design in order to optimize the expected outcome; with that, we adapt the randomization mechanism for future time-point experiments based on the data collected on the individual over time. Our results demonstrate that one can learn the optimal rule based on a single sample, and thereby adjust the design at any point t with valid inference for the mean target parameter. This work provides several contributions to the field of statistical precision medicine. First, we define a general class of averages of conditional causal parameters defined by the current context for the single unit time-series data. We define a nonparametric model for the probability distribution of the time-series under few assumptions, and aim to fully utilize the sequential randomization in the estimation procedure via the double robust structure of the efficient influence curve of the proposed target parameter. We present multiple exploration-exploitation strategies for assigning treatment, and methods for estimating the optimal rule. Lastly, we present the study of the data-adaptive inference on the mean under the optimal treatment rule, where the target parameter adapts over time in response to the observed context of the individual. Our target parameter is pathwise differentiable with an efficient influence function that is doubly robust - which makes it easier to estimate than previously proposed variations. We characterize the limit distribution of our estimator under a Donsker condition expressed in terms of a notion of bracketing entropy adapted to martingale settings.