 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRate-adaptive model selection over a collection of black-box contextual bandit algorithms
Jun 05, 2020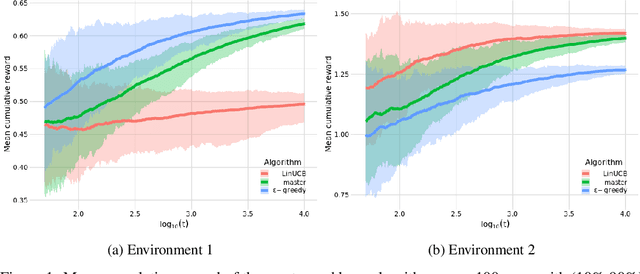
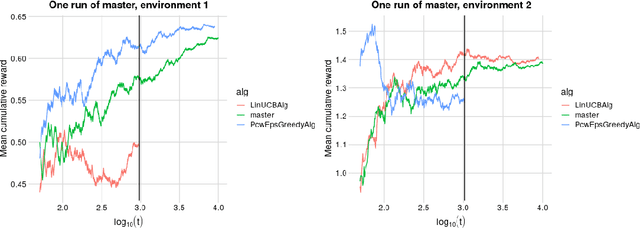
We consider the model selection task in the stochastic contextual bandit setting. Suppose we are given a collection of base contextual bandit algorithms. We provide a master algorithm that combines them and achieves the same performance, up to constants, as the best base algorithm would, if it had been run on its own. Our approach only requires that each algorithm satisfy a high probability regret bound. Our procedure is very simple and essentially does the following: for a well chosen sequence of probabilities $(p_{t})_{t\geq 1}$, at each round $t$, it either chooses at random which candidate to follow (with probability $p_{t}$) or compares, at the same internal sample size for each candidate, the cumulative reward of each, and selects the one that wins the comparison (with probability $1-p_{t}$). To the best of our knowledge, our proposal is the first one to be rate-adaptive for a collection of general black-box contextual bandit algorithms: it achieves the same regret rate as the best candidate. We demonstrate the effectiveness of our method with simulation studies.
Generalized Policy Elimination: an efficient algorithm for Nonparametric Contextual Bandits
Mar 05, 2020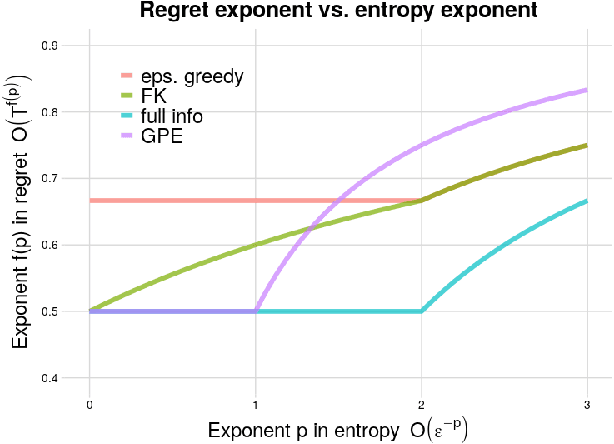
We propose the Generalized Policy Elimination (GPE) algorithm, an oracle-efficient contextual bandit (CB) algorithm inspired by the Policy Elimination algorithm of \cite{dudik2011}. We prove the first regret optimality guarantee theorem for an oracle-efficient CB algorithm competing against a nonparametric class with infinite VC-dimension. Specifically, we show that GPE is regret-optimal (up to logarithmic factors) for policy classes with integrable entropy. For classes with larger entropy, we show that the core techniques used to analyze GPE can be used to design an $\varepsilon$-greedy algorithm with regret bound matching that of the best algorithms to date. We illustrate the applicability of our algorithms and theorems with examples of large nonparametric policy classes, for which the relevant optimization oracles can be efficiently implemented.
More Efficient Off-Policy Evaluation through Regularized Targeted Learning
Dec 13, 2019We study the problem of off-policy evaluation (OPE) in Reinforcement Learning (RL), where the aim is to estimate the performance of a new policy given historical data that may have been generated by a different policy, or policies. In particular, we introduce a novel doubly-robust estimator for the OPE problem in RL, based on the Targeted Maximum Likelihood Estimation principle from the statistical causal inference literature. We also introduce several variance reduction techniques that lead to impressive performance gains in off-policy evaluation. We show empirically that our estimator uniformly wins over existing off-policy evaluation methods across multiple RL environments and various levels of model misspecification. Finally, we further the existing theoretical analysis of estimators for the RL off-policy estimation problem by showing their $O_P(1/\sqrt{n})$ rate of convergence and characterizing their asymptotic distribution.
* We are uploading the full paper with the appendix as of 12/12/2019, as we noticed that, unlike the main text, the appendix has not been made available on PMLR's website. The version of the appendix in this document is the same that we have been sending by email since June 2019 to readers who solicited it