 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAPO: Counterfactual Credit Assignment in Sequential Cooperative Teams
Apr 20, 2026In cooperative teams where agents act in a fixed order and share a single team reward, it is hard to know how much each agent contributed, and harder still when agents are updated one at a time because data collected earlier no longer reflects the new policies. We introduce the Sequential Aristocrat Utility (SeqAU), the unique per-agent learning signal that maximizes the individual learnability of each agent's action, extending the classical framework of Wolpert and Tumer (2002) to this sequential setting. From SeqAU we derive CAPO (Counterfactual Advantage Policy Optimization), a critic-free policy-gradient algorithm. CAPO fits a per-agent reward decomposition from group rewards and computes the per-agent advantage in closed form plus a handful of forward passes through the current policy, requiring no extra environment calls beyond the initial batch. We give analytic bias and variance bounds and validate them on a controlled sequential bandit, where CAPO's advantage over standard baselines grows with the team size. The framework is general; multi-LLM pipelines are a natural deployment target.
Stepwise Credit Assignment for GRPO on Flow-Matching Models
Mar 30, 2026Flow-GRPO successfully applies reinforcement learning to flow models, but uses uniform credit assignment across all steps. This ignores the temporal structure of diffusion generation: early steps determine composition and content (low-frequency structure), while late steps resolve details and textures (high-frequency details). Moreover, assigning uniform credit based solely on the final image can inadvertently reward suboptimal intermediate steps, especially when errors are corrected later in the diffusion trajectory. We propose Stepwise-Flow-GRPO, which assigns credit based on each step's reward improvement. By leveraging Tweedie's formula to obtain intermediate reward estimates and introducing gain-based advantages, our method achieves superior sample efficiency and faster convergence. We also introduce a DDIM-inspired SDE that improves reward quality while preserving stochasticity for policy gradients.
Voice Evaluation of Reasoning Ability: Diagnosing the Modality-Induced Performance Gap
Sep 30, 2025We present Voice Evaluation of Reasoning Ability (VERA), a benchmark for evaluating reasoning ability in voice-interactive systems under real-time conversational constraints. VERA comprises 2,931 voice-native episodes derived from established text benchmarks and organized into five tracks (Math, Web, Science, Long-Context, Factual). Each item is adapted for speech interaction while preserving reasoning difficulty. VERA enables direct text-voice comparison within model families and supports analysis of how architectural choices affect reliability. We assess 12 contemporary voice systems alongside strong text baselines and observe large, consistent modality gaps: on competition mathematics a leading text model attains 74.8% accuracy while its voice counterpart reaches 6.1%; macro-averaged across tracks the best text models achieve 54.0% versus 11.3% for voice. Latency-accuracy analyses reveal a low-latency plateau, where fast voice systems cluster around ~10% accuracy, while approaching text performance requires sacrificing real-time interaction. Diagnostic experiments indicate that common mitigations are insufficient. Increasing "thinking time" yields negligible gains; a decoupled cascade that separates reasoning from narration improves accuracy but still falls well short of text and introduces characteristic grounding/consistency errors. Failure analyses further show distinct error signatures across native streaming, end-to-end, and cascade designs. VERA provides a reproducible testbed and targeted diagnostics for architectures that decouple thinking from speaking, offering a principled way to measure progress toward real-time voice assistants that are both fluent and reliably reasoned.
Distributional Off-Policy Evaluation for Slate Recommendations
Aug 27, 2023Recommendation strategies are typically evaluated by using previously logged data, employing off-policy evaluation methods to estimate their expected performance. However, for strategies that present users with slates of multiple items, the resulting combinatorial action space renders many of these methods impractical. Prior work has developed estimators that leverage the structure in slates to estimate the expected off-policy performance, but the estimation of the entire performance distribution remains elusive. Estimating the complete distribution allows for a more comprehensive evaluation of recommendation strategies, particularly along the axes of risk and fairness that employ metrics computable from the distribution. In this paper, we propose an estimator for the complete off-policy performance distribution for slates and establish conditions under which the estimator is unbiased and consistent. This builds upon prior work on off-policy evaluation for slates and off-policy distribution estimation in reinforcement learning. We validate the efficacy of our method empirically on synthetic data as well as on a slate recommendation simulator constructed from real-world data (MovieLens-20M). Our results show a significant reduction in estimation variance and improved sample efficiency over prior work across a range of slate structures.
FigCaps-HF: A Figure-to-Caption Generative Framework and Benchmark with Human Feedback
Jul 20, 2023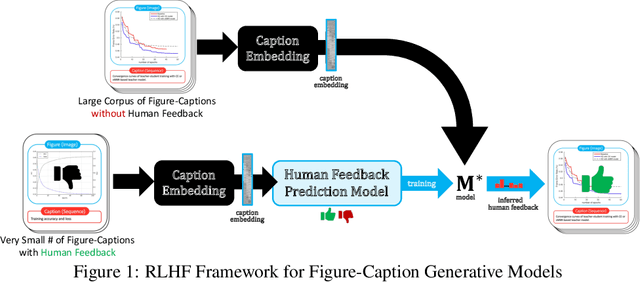
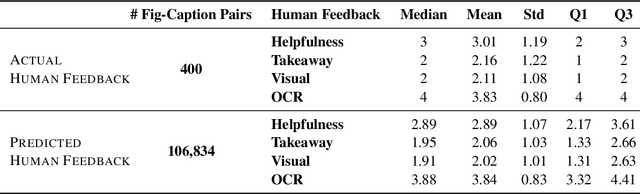
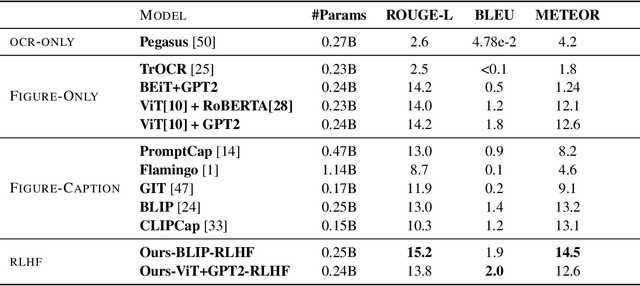
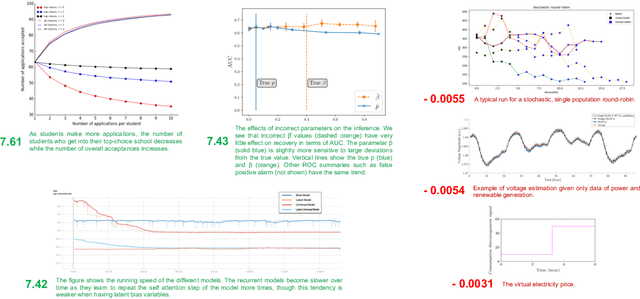
Captions are crucial for understanding scientific visualizations and documents. Existing captioning methods for scientific figures rely on figure-caption pairs extracted from documents for training, many of which fall short with respect to metrics like helpfulness, explainability, and visual-descriptiveness [15] leading to generated captions being misaligned with reader preferences. To enable the generation of high-quality figure captions, we introduce FigCaps-HF a new framework for figure-caption generation that can incorporate domain expert feedback in generating captions optimized for reader preferences. Our framework comprises of 1) an automatic method for evaluating quality of figure-caption pairs, 2) a novel reinforcement learning with human feedback (RLHF) method to optimize a generative figure-to-caption model for reader preferences. We demonstrate the effectiveness of our simple learning framework by improving performance over standard fine-tuning across different types of models. In particular, when using BLIP as the base model, our RLHF framework achieves a mean gain of 35.7%, 16.9%, and 9% in ROUGE, BLEU, and Meteor, respectively. Finally, we release a large-scale benchmark dataset with human feedback on figure-caption pairs to enable further evaluation and development of RLHF techniques for this problem.
Local Policy Improvement for Recommender Systems
Dec 22, 2022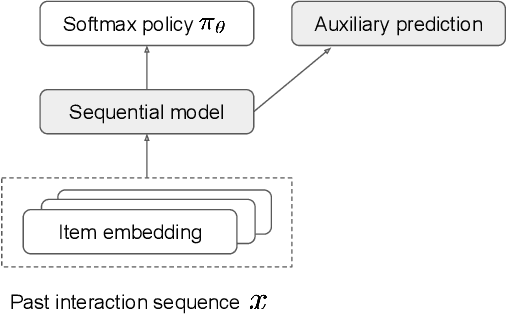
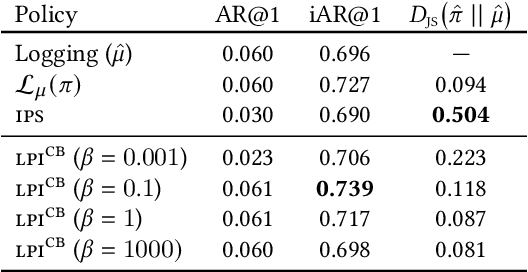
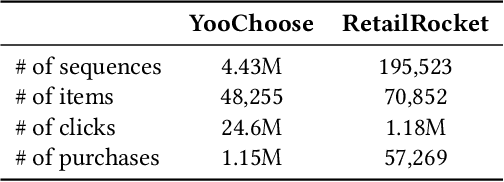
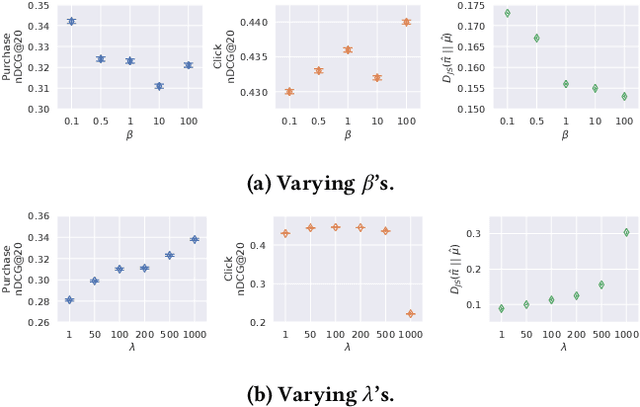
Recommender systems aim to answer the following question: given the items that a user has interacted with, what items will this user likely interact with next? Historically this problem is often framed as a predictive task via (self-)supervised learning. In recent years, we have seen more emphasis placed on approaching the recommendation problem from a policy optimization perspective: learning a policy that maximizes some reward function (e.g., user engagement). However, it is commonly the case in recommender systems that we are only able to train a new policy given data collected from a previously-deployed policy. The conventional way to address such a policy mismatch is through importance sampling correction, which unfortunately comes with its own limitations. In this paper, we suggest an alternative approach, which involves the use of local policy improvement without off-policy correction. Drawing from a number of related results in the fields of causal inference, bandits, and reinforcement learning, we present a suite of methods that compute and optimize a lower bound of the expected reward of the target policy. Crucially, this lower bound is a function that is easy to estimate from data, and which does not involve density ratios (such as those appearing in importance sampling correction). We argue that this local policy improvement paradigm is particularly well suited for recommender systems, given that in practice the previously-deployed policy is typically of reasonably high quality, and furthermore it tends to be re-trained frequently and gets continuously updated. We discuss some practical recipes on how to apply some of the proposed techniques in a sequential recommendation setting.
Control Variates for Slate Off-Policy Evaluation
Jun 15, 2021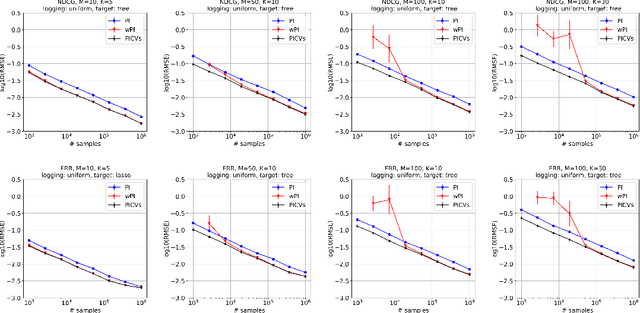
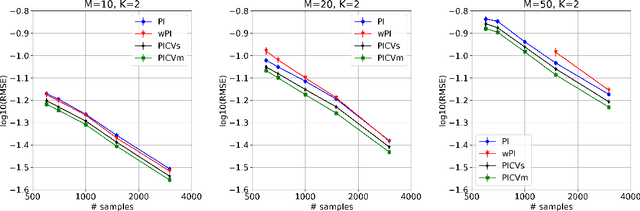
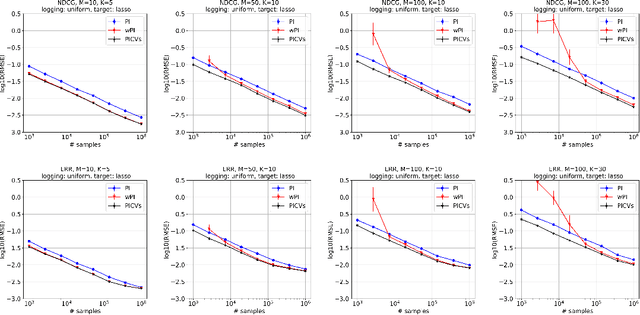
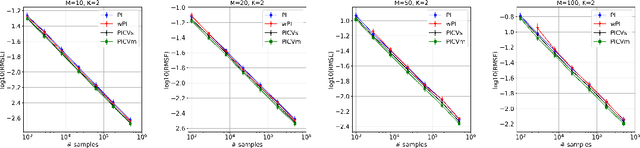
We study the problem of off-policy evaluation from batched contextual bandit data with multidimensional actions, often termed slates. The problem is common to recommender systems and user-interface optimization, and it is particularly challenging because of the combinatorially-sized action space. Swaminathan et al. (2017) have proposed the pseudoinverse (PI) estimator under the assumption that the conditional mean rewards are additive in actions. Using control variates, we consider a large class of unbiased estimators that includes as specific cases the PI estimator and (asymptotically) its self-normalized variant. By optimizing over this class, we obtain new estimators with risk improvement guarantees over both the PI and self-normalized PI estimators. Experiments with real-world recommender data as well as synthetic data validate these improvements in practice.
Off-Policy Evaluation of Slate Policies under Bayes Risk
Jan 05, 2021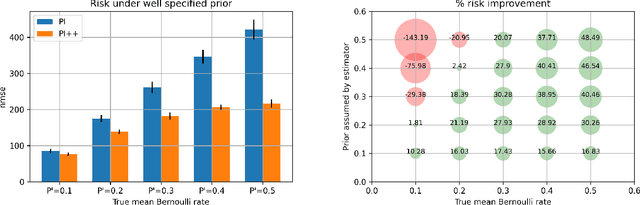
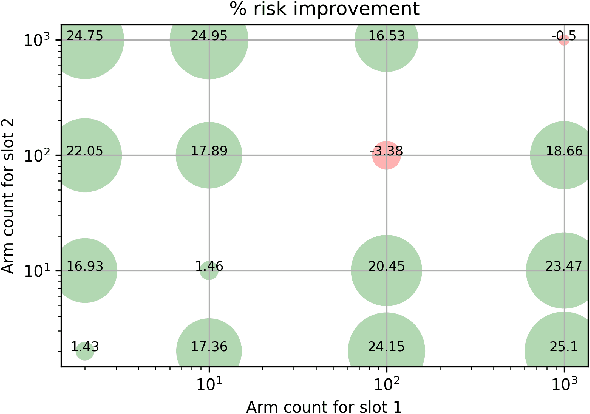
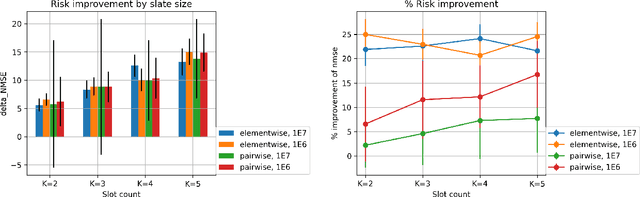
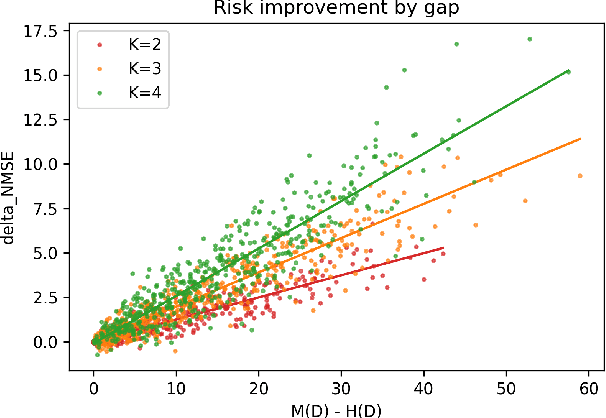
We study the problem of off-policy evaluation for slate bandits, for the typical case in which the logging policy factorizes over the slots of the slate. We slightly depart from the existing literature by taking Bayes risk as the criterion by which to evaluate estimators, and we analyze the family of 'additive' estimators that includes the pseudoinverse (PI) estimator of Swaminathan et al.\ (2017; arXiv:1605.04812). Using a control variate approach, we identify a new estimator in this family that is guaranteed to have lower risk than PI in the above class of problems. In particular, we show that the risk improvement over PI grows linearly with the number of slots, and linearly with the gap between the arithmetic and the harmonic mean of a set of slot-level divergences between the logging and the target policy. In the typical case of a uniform logging policy and a deterministic target policy, each divergence corresponds to slot size, showing that maximal gains can be obtained for slate problems with diverse numbers of actions per slot.
More Efficient Off-Policy Evaluation through Regularized Targeted Learning
Dec 13, 2019We study the problem of off-policy evaluation (OPE) in Reinforcement Learning (RL), where the aim is to estimate the performance of a new policy given historical data that may have been generated by a different policy, or policies. In particular, we introduce a novel doubly-robust estimator for the OPE problem in RL, based on the Targeted Maximum Likelihood Estimation principle from the statistical causal inference literature. We also introduce several variance reduction techniques that lead to impressive performance gains in off-policy evaluation. We show empirically that our estimator uniformly wins over existing off-policy evaluation methods across multiple RL environments and various levels of model misspecification. Finally, we further the existing theoretical analysis of estimators for the RL off-policy estimation problem by showing their $O_P(1/\sqrt{n})$ rate of convergence and characterizing their asymptotic distribution.
* We are uploading the full paper with the appendix as of 12/12/2019, as we noticed that, unlike the main text, the appendix has not been made available on PMLR's website. The version of the appendix in this document is the same that we have been sending by email since June 2019 to readers who solicited it
Posterior Sampling for Large Scale Reinforcement Learning
Oct 22, 2018
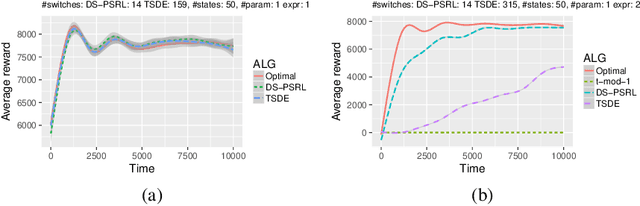
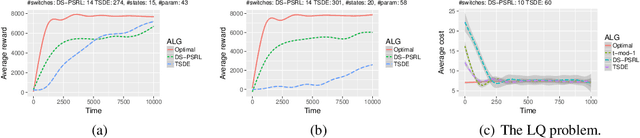
We propose a practical non-episodic PSRL algorithm that unlike recent state-of-the-art PSRL algorithms uses a deterministic, model-independent episode switching schedule. Our algorithm termed deterministic schedule PSRL (DS-PSRL) is efficient in terms of time, sample, and space complexity. We prove a Bayesian regret bound under mild assumptions. Our result is more generally applicable to multiple parameters and continuous state action problems. We compare our algorithm with state-of-the-art PSRL algorithms on standard discrete and continuous problems from the literature. Finally, we show how the assumptions of our algorithm satisfy a sensible parametrization for a large class of problems in sequential recommendations.