 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributional Off-Policy Evaluation for Slate Recommendations
Aug 27, 2023Recommendation strategies are typically evaluated by using previously logged data, employing off-policy evaluation methods to estimate their expected performance. However, for strategies that present users with slates of multiple items, the resulting combinatorial action space renders many of these methods impractical. Prior work has developed estimators that leverage the structure in slates to estimate the expected off-policy performance, but the estimation of the entire performance distribution remains elusive. Estimating the complete distribution allows for a more comprehensive evaluation of recommendation strategies, particularly along the axes of risk and fairness that employ metrics computable from the distribution. In this paper, we propose an estimator for the complete off-policy performance distribution for slates and establish conditions under which the estimator is unbiased and consistent. This builds upon prior work on off-policy evaluation for slates and off-policy distribution estimation in reinforcement learning. We validate the efficacy of our method empirically on synthetic data as well as on a slate recommendation simulator constructed from real-world data (MovieLens-20M). Our results show a significant reduction in estimation variance and improved sample efficiency over prior work across a range of slate structures.
Coagent Networks: Generalized and Scaled
May 16, 2023

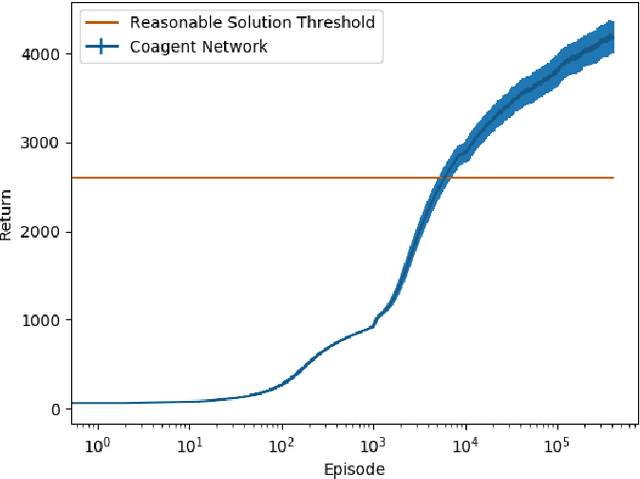
Coagent networks for reinforcement learning (RL) [Thomas and Barto, 2011] provide a powerful and flexible framework for deriving principled learning rules for arbitrary stochastic neural networks. The coagent framework offers an alternative to backpropagation-based deep learning (BDL) that overcomes some of backpropagation's main limitations. For example, coagent networks can compute different parts of the network \emph{asynchronously} (at different rates or at different times), can incorporate non-differentiable components that cannot be used with backpropagation, and can explore at levels higher than their action spaces (that is, they can be designed as hierarchical networks for exploration and/or temporal abstraction). However, the coagent framework is not just an alternative to BDL; the two approaches can be blended: BDL can be combined with coagent learning rules to create architectures with the advantages of both approaches. This work generalizes the coagent theory and learning rules provided by previous works; this generalization provides more flexibility for network architecture design within the coagent framework. This work also studies one of the chief disadvantages of coagent networks: high variance updates for networks that have many coagents and do not use backpropagation. We show that a coagent algorithm with a policy network that does not use backpropagation can scale to a challenging RL domain with a high-dimensional state and action space (the MuJoCo Ant environment), learning reasonable (although not state-of-the-art) policies. These contributions motivate and provide a more general theoretical foundation for future work that studies coagent networks.
Explaining RL Decisions with Trajectories
May 06, 2023



Explanation is a key component for the adoption of reinforcement learning (RL) in many real-world decision-making problems. In the literature, the explanation is often provided by saliency attribution to the features of the RL agent's state. In this work, we propose a complementary approach to these explanations, particularly for offline RL, where we attribute the policy decisions of a trained RL agent to the trajectories encountered by it during training. To do so, we encode trajectories in offline training data individually as well as collectively (encoding a set of trajectories). We then attribute policy decisions to a set of trajectories in this encoded space by estimating the sensitivity of the decision with respect to that set. Further, we demonstrate the effectiveness of the proposed approach in terms of quality of attributions as well as practical scalability in diverse environments that involve both discrete and continuous state and action spaces such as grid-worlds, video games (Atari) and continuous control (MuJoCo). We also conduct a human study on a simple navigation task to observe how their understanding of the task compares with data attributed for a trained RL policy. Keywords -- Explainable AI, Verifiability of AI Decisions, Explainable RL.
Personalized Detection of Cognitive Biases in Actions of Users from Their Logs: Anchoring and Recency Biases
Jul 01, 2022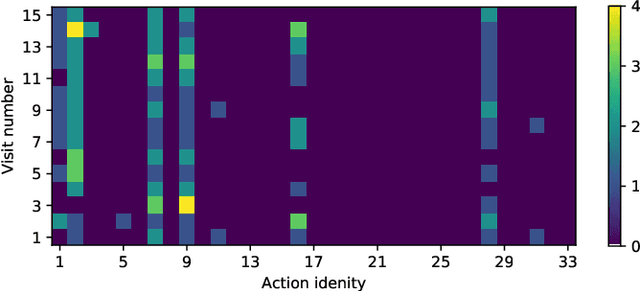

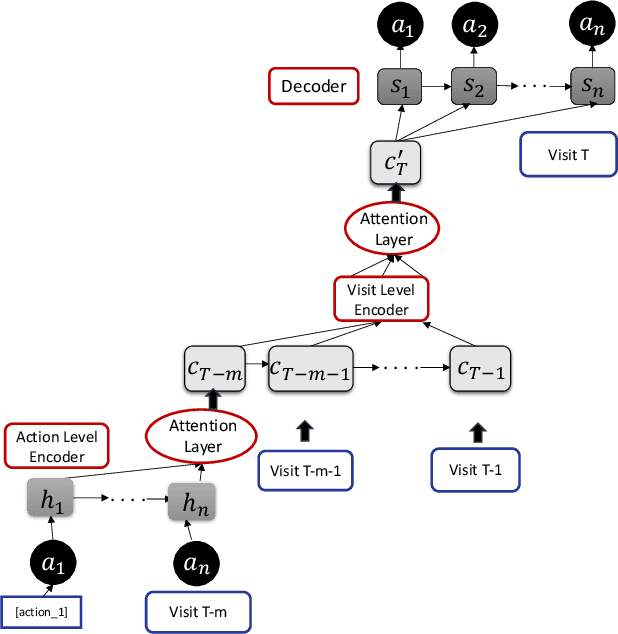
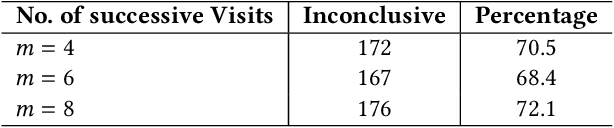
Cognitive biases are mental shortcuts humans use in dealing with information and the environment, and which result in biased actions and behaviors (or, actions), unbeknownst to themselves. Biases take many forms, with cognitive biases occupying a central role that inflicts fairness, accountability, transparency, ethics, law, medicine, and discrimination. Detection of biases is considered a necessary step toward their mitigation. Herein, we focus on two cognitive biases - anchoring and recency. The recognition of cognitive bias in computer science is largely in the domain of information retrieval, and bias is identified at an aggregate level with the help of annotated data. Proposing a different direction for bias detection, we offer a principled approach along with Machine Learning to detect these two cognitive biases from Web logs of users' actions. Our individual user level detection makes it truly personalized, and does not rely on annotated data. Instead, we start with two basic principles established in cognitive psychology, use modified training of an attention network, and interpret attention weights in a novel way according to those principles, to infer and distinguish between these two biases. The personalized approach allows detection for specific users who are susceptible to these biases when performing their tasks, and can help build awareness among them so as to undertake bias mitigation.
Smoothed Online Combinatorial Optimization Using Imperfect Predictions
Apr 23, 2022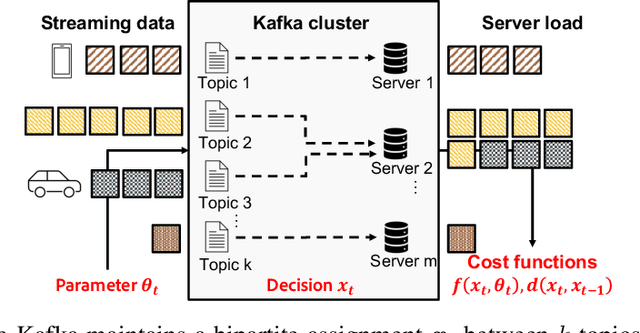


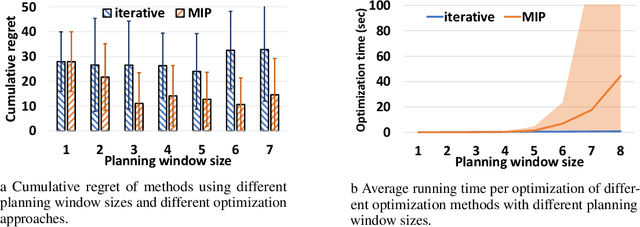
Smoothed online combinatorial optimization considers a learner who repeatedly chooses a combinatorial decision to minimize an unknown changing cost function with a penalty on switching decisions in consecutive rounds. We study smoothed online combinatorial optimization problems when an imperfect predictive model is available, where the model can forecast the future cost functions with uncertainty. We show that using predictions to plan for a finite time horizon leads to regret dependent on the total predictive uncertainty and an additional switching cost. This observation suggests choosing a suitable planning window to balance between uncertainty and switching cost, which leads to an online algorithm with guarantees on the upper and lower bounds of the cumulative regret. Lastly, we provide an iterative algorithm to approximately solve the planning problem in real-time. Empirically, our algorithm shows a significant improvement in cumulative regret compared to other baselines in synthetic online distributed streaming problems.
Off-Policy Evaluation in Embedded Spaces
Mar 05, 2022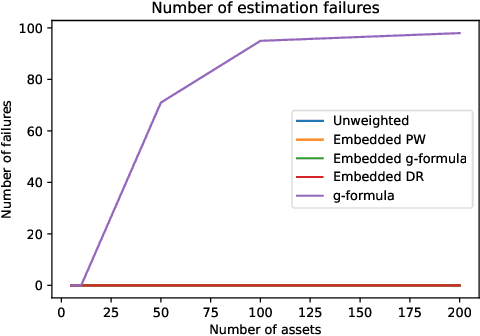
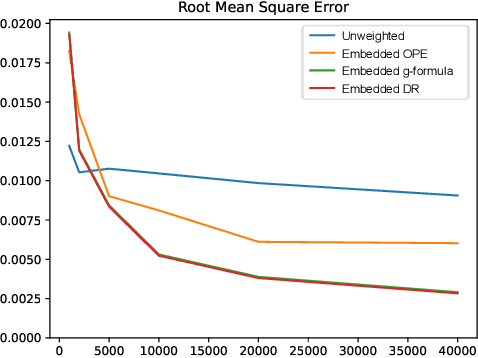
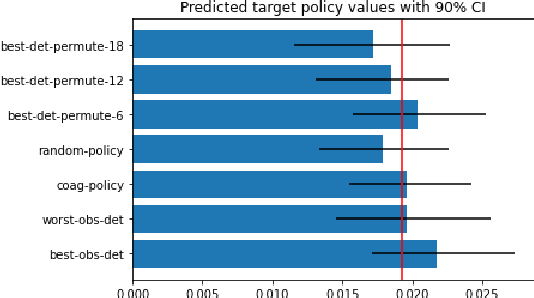
Off-policy evaluation methods are important in recommendation systems and search engines, whereby data collected under an old logging policy is used to predict the performance of a new target policy. However, in practice most systems are not observed to recommend most of the possible actions, which is an issue since existing methods require that the probability of the target policy recommending an item can only be non-zero when the probability of the logging policy is non-zero (known as absolute continuity). To circumvent this issue, we explore the use of action embeddings. By representing contexts and actions in an embedding space, we are able to share information to extrapolate behaviors for actions and contexts previously unseen.
Constraint Sampling Reinforcement Learning: Incorporating Expertise For Faster Learning
Dec 30, 2021


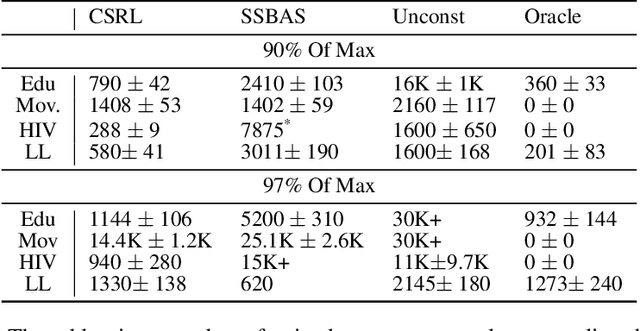
Online reinforcement learning (RL) algorithms are often difficult to deploy in complex human-facing applications as they may learn slowly and have poor early performance. To address this, we introduce a practical algorithm for incorporating human insight to speed learning. Our algorithm, Constraint Sampling Reinforcement Learning (CSRL), incorporates prior domain knowledge as constraints/restrictions on the RL policy. It takes in multiple potential policy constraints to maintain robustness to misspecification of individual constraints while leveraging helpful ones to learn quickly. Given a base RL learning algorithm (ex. UCRL, DQN, Rainbow) we propose an upper confidence with elimination scheme that leverages the relationship between the constraints, and their observed performance, to adaptively switch among them. We instantiate our algorithm with DQN-type algorithms and UCRL as base algorithms, and evaluate our algorithm in four environments, including three simulators based on real data: recommendations, educational activity sequencing, and HIV treatment sequencing. In all cases, CSRL learns a good policy faster than baselines.
Edge-Compatible Reinforcement Learning for Recommendations
Dec 10, 2021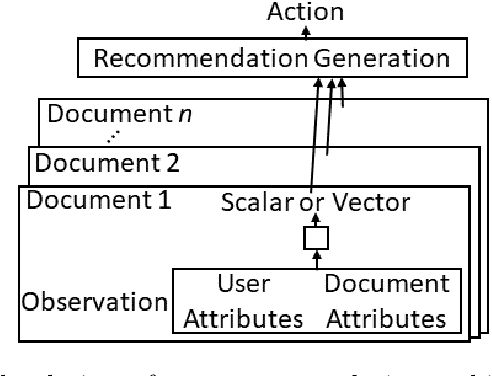
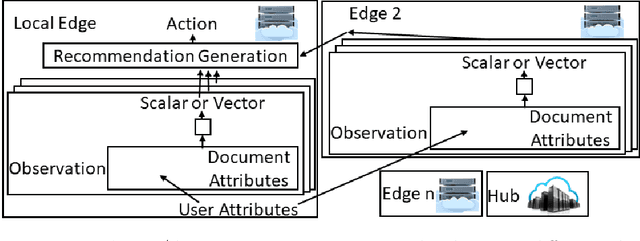
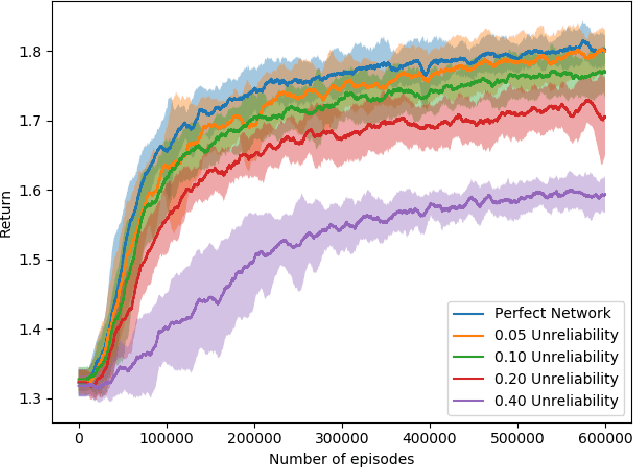
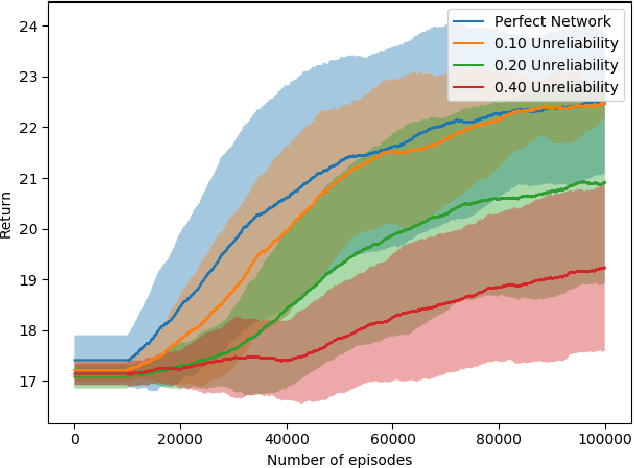
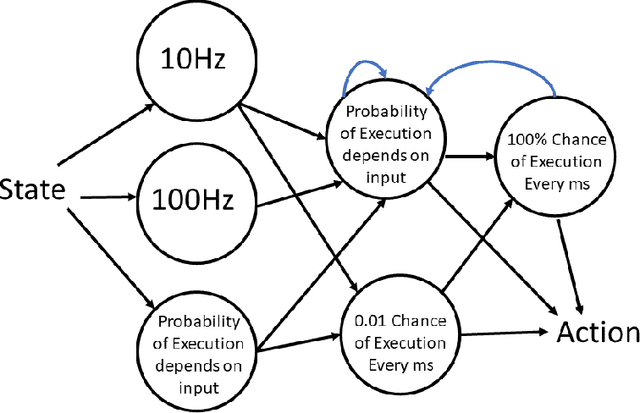
Most reinforcement learning (RL) recommendation systems designed for edge computing must either synchronize during recommendation selection or depend on an unprincipled patchwork collection of algorithms. In this work, we build on asynchronous coagent policy gradient algorithms \citep{kostas2020asynchronous} to propose a principled solution to this problem. The class of algorithms that we propose can be distributed over the internet and run asynchronously and in real-time. When a given edge fails to respond to a request for data with sufficient speed, this is not a problem; the algorithm is designed to function and learn in the edge setting, and network issues are part of this setting. The result is a principled, theoretically grounded RL algorithm designed to be distributed in and learn in this asynchronous environment. In this work, we describe this algorithm and a proposed class of architectures in detail, and demonstrate that they work well in practice in the asynchronous setting, even as the network quality degrades.
Multiscale Manifold Warping
Sep 19, 2021

Many real-world applications require aligning two temporal sequences, including bioinformatics, handwriting recognition, activity recognition, and human-robot coordination. Dynamic Time Warping (DTW) is a popular alignment method, but can fail on high-dimensional real-world data where the dimensions of aligned sequences are often unequal. In this paper, we show that exploiting the multiscale manifold latent structure of real-world data can yield improved alignment. We introduce a novel framework called Warping on Wavelets (WOW) that integrates DTW with a a multi-scale manifold learning framework called Diffusion Wavelets. We present a theoretical analysis of the WOW family of algorithms and show that it outperforms previous state of the art methods, such as canonical time warping (CTW) and manifold warping, on several real-world datasets.
Towards Safe Policy Improvement for Non-Stationary MDPs
Oct 23, 2020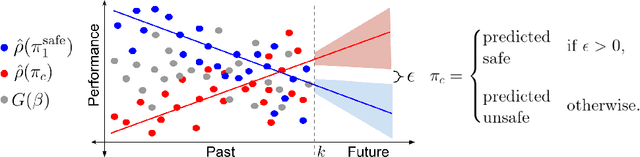
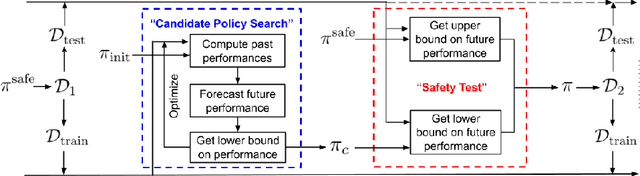

Many real-world sequential decision-making problems involve critical systems with financial risks and human-life risks. While several works in the past have proposed methods that are safe for deployment, they assume that the underlying problem is stationary. However, many real-world problems of interest exhibit non-stationarity, and when stakes are high, the cost associated with a false stationarity assumption may be unacceptable. We take the first steps towards ensuring safety, with high confidence, for smoothly-varying non-stationary decision problems. Our proposed method extends a type of safe algorithm, called a Seldonian algorithm, through a synthesis of model-free reinforcement learning with time-series analysis. Safety is ensured using sequential hypothesis testing of a policy's forecasted performance, and confidence intervals are obtained using wild bootstrap.