 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Detection of Cognitive Biases in Actions of Users from Their Logs: Anchoring and Recency Biases
Jul 01, 2022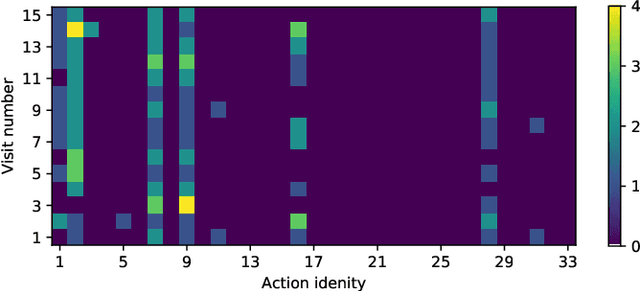

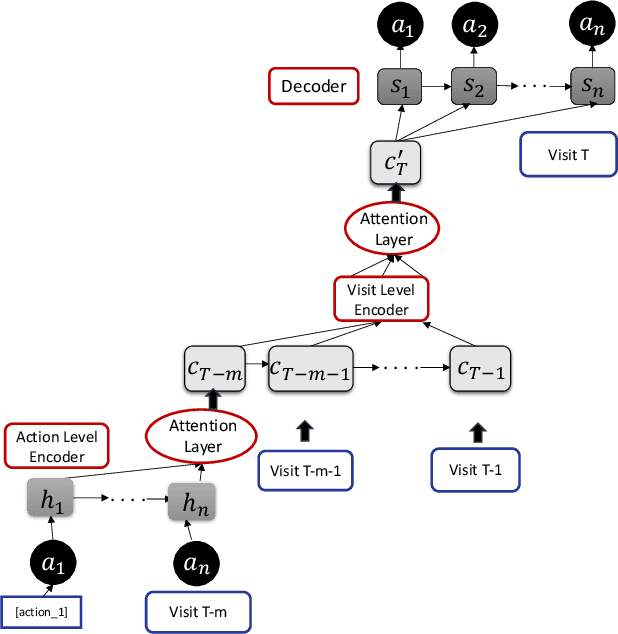
Cognitive biases are mental shortcuts humans use in dealing with information and the environment, and which result in biased actions and behaviors (or, actions), unbeknownst to themselves. Biases take many forms, with cognitive biases occupying a central role that inflicts fairness, accountability, transparency, ethics, law, medicine, and discrimination. Detection of biases is considered a necessary step toward their mitigation. Herein, we focus on two cognitive biases - anchoring and recency. The recognition of cognitive bias in computer science is largely in the domain of information retrieval, and bias is identified at an aggregate level with the help of annotated data. Proposing a different direction for bias detection, we offer a principled approach along with Machine Learning to detect these two cognitive biases from Web logs of users' actions. Our individual user level detection makes it truly personalized, and does not rely on annotated data. Instead, we start with two basic principles established in cognitive psychology, use modified training of an attention network, and interpret attention weights in a novel way according to those principles, to infer and distinguish between these two biases. The personalized approach allows detection for specific users who are susceptible to these biases when performing their tasks, and can help build awareness among them so as to undertake bias mitigation.
Botcha: Detecting Malicious Non-Human Traffic in the Wild
Mar 02, 2021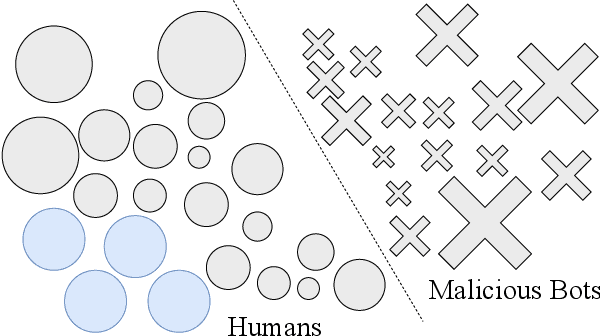
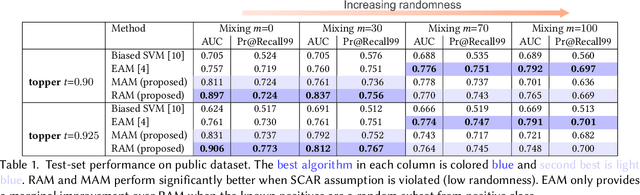
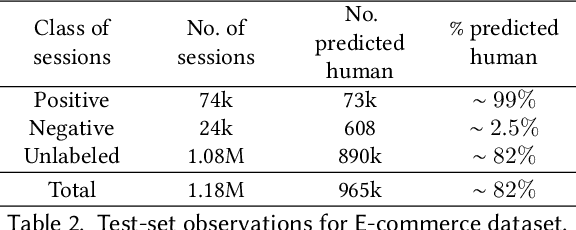
Malicious bots make up about a quarter of all traffic on the web, and degrade the performance of personalization and recommendation algorithms that operate on e-commerce sites. Positive-Unlabeled learning (PU learning) provides the ability to train a binary classifier using only positive (P) and unlabeled (U) instances. The unlabeled data comprises of both positive and negative classes. It is possible to find labels for strict subsets of non-malicious actors, e.g., the assumption that only humans purchase during web sessions, or clear CAPTCHAs. However, finding signals of malicious behavior is almost impossible due to the ever-evolving and adversarial nature of bots. Such a set-up naturally lends itself to PU learning. Unfortunately, standard PU learning approaches assume that the labeled set of positives are a random sample of all positives, this is unlikely to hold in practice. In this work, we propose two modifications to PU learning that make it more robust to violations of the selected-completely-at-random assumption, leading to a system that can filter out malicious bots. In one public and one proprietary dataset, we show that proposed approaches are better at identifying humans in web data than standard PU learning methods.
Split: Inferring Unobserved Event Probabilities for Disentangling Brand-Customer Interactions
Dec 08, 2020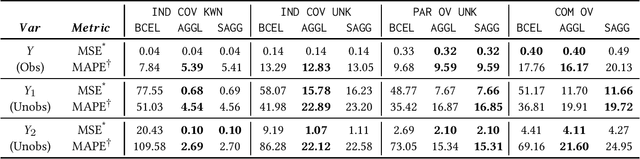
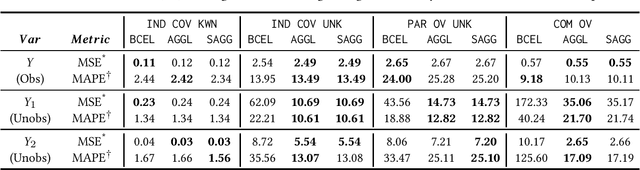

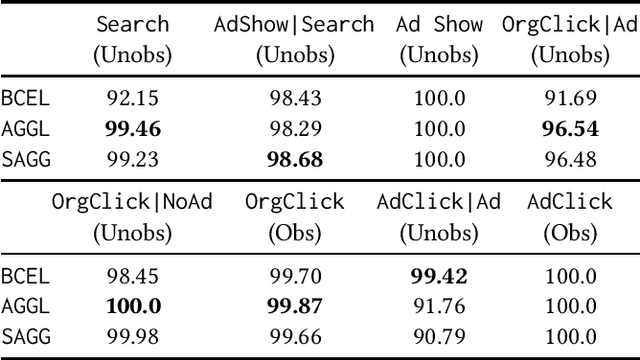
Often, data contains only composite events composed of multiple events, some observed and some unobserved. For example, search ad click is observed by a brand, whereas which customers were shown a search ad - an actionable variable - is often not observed. In such cases, inference is not possible on unobserved event. This occurs when a marketing action is taken over earned and paid digital channels. Similar setting arises in numerous datasets where multiple actors interact. One approach is to use the composite event as a proxy for the unobserved event of interest. However, this leads to invalid inference. This paper takes a direct approach whereby an event of interest is identified based on information on the composite event and aggregate data on composite events (e.g. total number of search ads shown). This work contributes to the literature by proving identification of the unobserved events' probabilities up to a scalar factor under mild condition. We propose an approach to identify the scalar factor by using aggregate data that is usually available from earned and paid channels. The factor is identified by adding a loss term to the usual cross-entropy loss. We validate the approach on three synthetic datasets. In addition, the approach is validated on a real marketing problem where some observed events are hidden from the algorithm for validation. The proposed modification to the cross-entropy loss function improves the average performance by 46%.
ELF: An Early-Exiting Framework for Long-Tailed Classification
Jun 22, 2020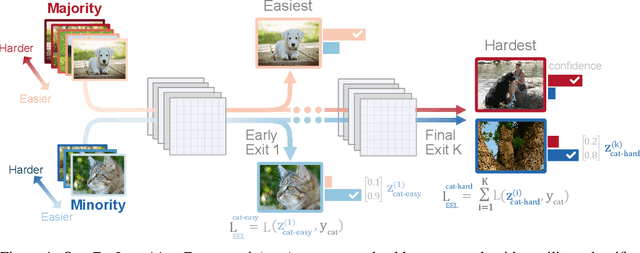
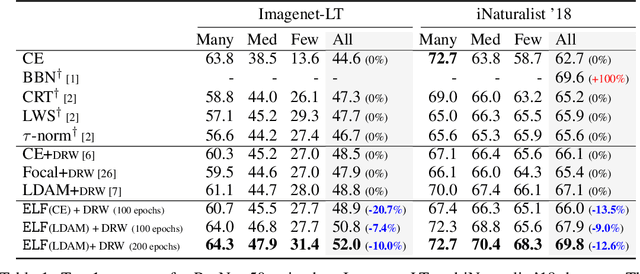

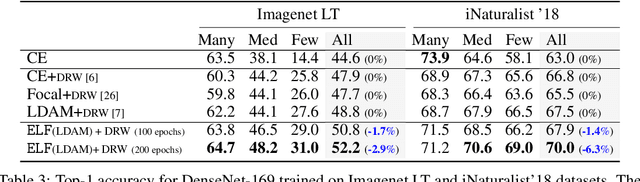
The natural world often follows a long-tailed data distribution where only a few classes account for most of the examples. This long-tail causes classifiers to overfit to the majority class. To mitigate this, prior solutions commonly adopt class rebalancing strategies such as data resampling and loss reshaping. However, by treating each example within a class equally, these methods fail to account for the important notion of example hardness, i.e., within each class some examples are easier to classify than others. To incorporate this notion of hardness into the learning process, we propose the EarLy-exiting Framework(ELF). During training, ELF learns to early-exit easy examples through auxiliary branches attached to a backbone network. This offers a dual benefit-(1) the neural network increasingly focuses on hard examples, since they contribute more to the overall network loss; and (2) it frees up additional model capacity to distinguish difficult examples. Experimental results on two large-scale datasets, ImageNet LT and iNaturalist'18, demonstrate that ELF can improve state-of-the-art accuracy by more than 3 percent. This comes with the additional benefit of reducing up to 20 percent of inference time FLOPS. ELF is complementary to prior work and can naturally integrate with a variety of existing methods to tackle the challenge of long-tailed distributions.