 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-World Dynamic Prompt and Continual Visual Representation Learning
Sep 09, 2024

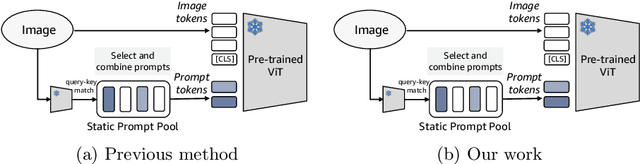

The open world is inherently dynamic, characterized by ever-evolving concepts and distributions. Continual learning (CL) in this dynamic open-world environment presents a significant challenge in effectively generalizing to unseen test-time classes. To address this challenge, we introduce a new practical CL setting tailored for open-world visual representation learning. In this setting, subsequent data streams systematically introduce novel classes that are disjoint from those seen in previous training phases, while also remaining distinct from the unseen test classes. In response, we present Dynamic Prompt and Representation Learner (DPaRL), a simple yet effective Prompt-based CL (PCL) method. Our DPaRL learns to generate dynamic prompts for inference, as opposed to relying on a static prompt pool in previous PCL methods. In addition, DPaRL jointly learns dynamic prompt generation and discriminative representation at each training stage whereas prior PCL methods only refine the prompt learning throughout the process. Our experimental results demonstrate the superiority of our approach, surpassing state-of-the-art methods on well-established open-world image retrieval benchmarks by an average of 4.7\% improvement in Recall@1 performance.
Robust Principles: Architectural Design Principles for Adversarially Robust CNNs
Sep 01, 2023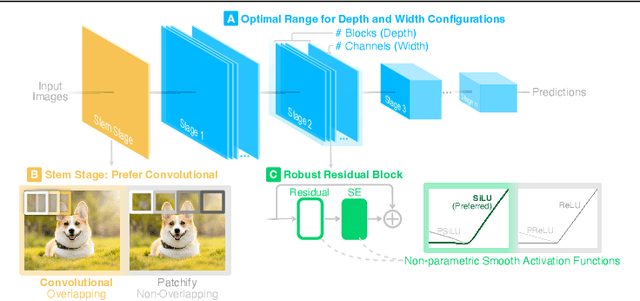
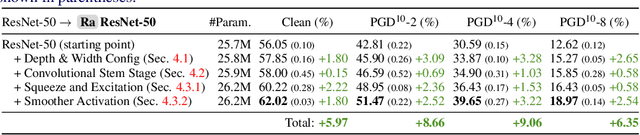
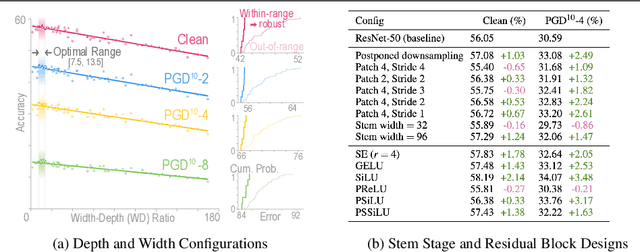

Our research aims to unify existing works' diverging opinions on how architectural components affect the adversarial robustness of CNNs. To accomplish our goal, we synthesize a suite of three generalizable robust architectural design principles: (a) optimal range for depth and width configurations, (b) preferring convolutional over patchify stem stage, and (c) robust residual block design through adopting squeeze and excitation blocks and non-parametric smooth activation functions. Through extensive experiments across a wide spectrum of dataset scales, adversarial training methods, model parameters, and network design spaces, our principles consistently and markedly improve AutoAttack accuracy: 1-3 percentage points (pp) on CIFAR-10 and CIFAR-100, and 4-9 pp on ImageNet. The code is publicly available at https://github.com/poloclub/robust-principles.
RobArch: Designing Robust Architectures against Adversarial Attacks
Jan 08, 2023



Adversarial Training is the most effective approach for improving the robustness of Deep Neural Networks (DNNs). However, compared to the large body of research in optimizing the adversarial training process, there are few investigations into how architecture components affect robustness, and they rarely constrain model capacity. Thus, it is unclear where robustness precisely comes from. In this work, we present the first large-scale systematic study on the robustness of DNN architecture components under fixed parameter budgets. Through our investigation, we distill 18 actionable robust network design guidelines that empower model developers to gain deep insights. We demonstrate these guidelines' effectiveness by introducing the novel Robust Architecture (RobArch) model that instantiates the guidelines to build a family of top-performing models across parameter capacities against strong adversarial attacks. RobArch achieves the new state-of-the-art AutoAttack accuracy on the RobustBench ImageNet leaderboard. The code is available at $\href{https://github.com/ShengYun-Peng/RobArch}{\text{this url}}$.
IMB-NAS: Neural Architecture Search for Imbalanced Datasets
Sep 30, 2022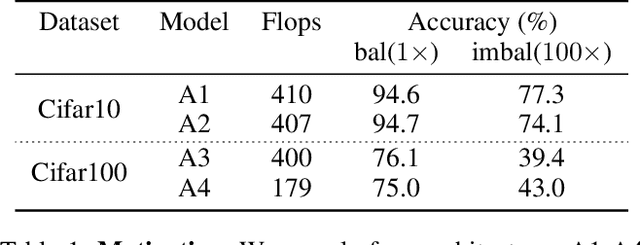
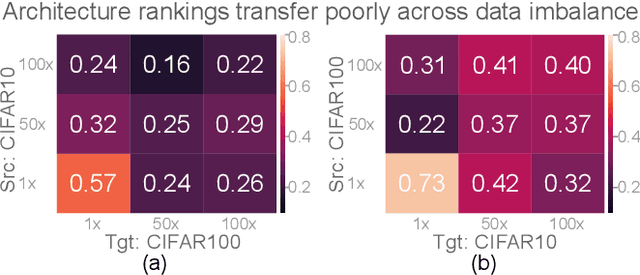

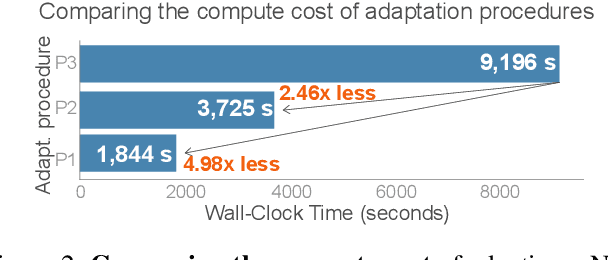
Class imbalance is a ubiquitous phenomenon occurring in real world data distributions. To overcome its detrimental effect on training accurate classifiers, existing work follows three major directions: class re-balancing, information transfer, and representation learning. In this paper, we propose a new and complementary direction for improving performance on long tailed datasets - optimizing the backbone architecture through neural architecture search (NAS). We find that an architecture's accuracy obtained on a balanced dataset is not indicative of good performance on imbalanced ones. This poses the need for a full NAS run on long tailed datasets which can quickly become prohibitively compute intensive. To alleviate this compute burden, we aim to efficiently adapt a NAS super-network from a balanced source dataset to an imbalanced target one. Among several adaptation strategies, we find that the most effective one is to retrain the linear classification head with reweighted loss, while freezing the backbone NAS super-network trained on a balanced source dataset. We perform extensive experiments on multiple datasets and provide concrete insights to optimize architectures for long tailed datasets.
Towards Regression-Free Neural Networks for Diverse Compute Platforms
Sep 27, 2022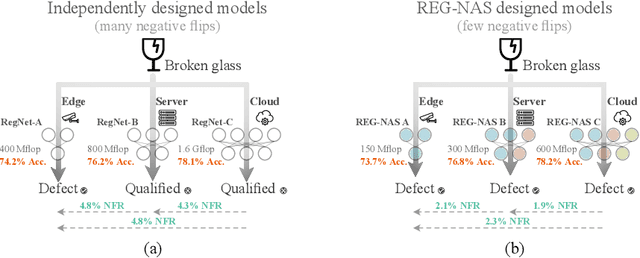
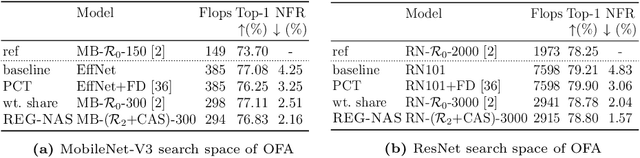
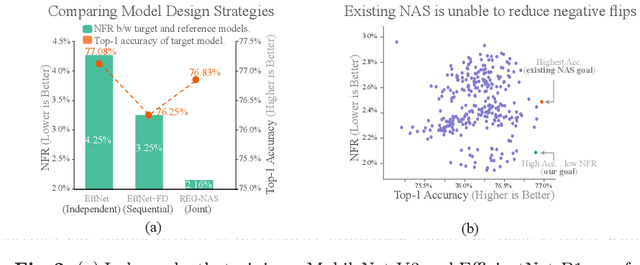
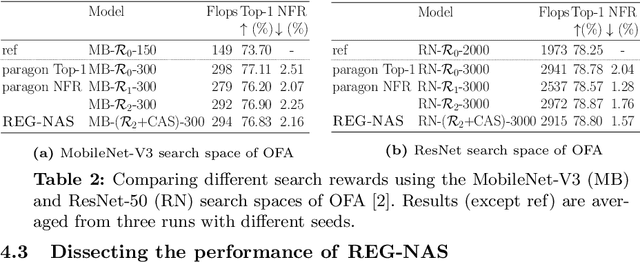
With the shift towards on-device deep learning, ensuring a consistent behavior of an AI service across diverse compute platforms becomes tremendously important. Our work tackles the emergent problem of reducing predictive inconsistencies arising as negative flips: test samples that are correctly predicted by a less accurate model, but incorrectly by a more accurate one. We introduce REGression constrained Neural Architecture Search (REG-NAS) to design a family of highly accurate models that engender fewer negative flips. REG-NAS consists of two components: (1) A novel architecture constraint that enables a larger model to contain all the weights of the smaller one thus maximizing weight sharing. This idea stems from our observation that larger weight sharing among networks leads to similar sample-wise predictions and results in fewer negative flips; (2) A novel search reward that incorporates both Top-1 accuracy and negative flips in the architecture search metric. We demonstrate that \regnas can successfully find desirable architectures with few negative flips in three popular architecture search spaces. Compared to the existing state-of-the-art approach, REG-NAS enables 33-48% relative reduction of negative flips.
ConceptEvo: Interpreting Concept Evolution in Deep Learning Training
Mar 30, 2022



Deep neural networks (DNNs) have been widely used for decision making, prompting a surge of interest in interpreting how these complex models work. Recent literature on DNN interpretation has revolved around already-trained models; however, much less research focuses on interpreting how the models evolve as they are trained. Interpreting model evolution is crucial to monitor network training and can aid proactive decisions about necessary interventions. In this work, we present ConceptEvo, a general interpretation framework for DNNs that reveals the inception and evolution of detected concepts during training. Through a large-scale human evaluation with 260 participants and quantitative experiments, we show that ConceptEvo discovers evolution across different models that are meaningful to humans, helpful for early-training intervention decisions, and crucial to the prediction for a given class.
NeuroCartography: Scalable Automatic Visual Summarization of Concepts in Deep Neural Networks
Aug 29, 2021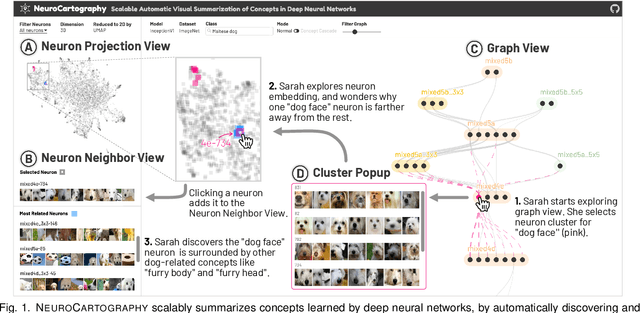


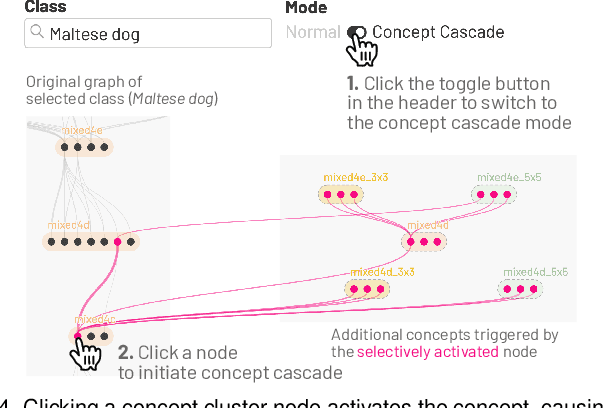
Existing research on making sense of deep neural networks often focuses on neuron-level interpretation, which may not adequately capture the bigger picture of how concepts are collectively encoded by multiple neurons. We present NeuroCartography, an interactive system that scalably summarizes and visualizes concepts learned by neural networks. It automatically discovers and groups neurons that detect the same concepts, and describes how such neuron groups interact to form higher-level concepts and the subsequent predictions. NeuroCartography introduces two scalable summarization techniques: (1) neuron clustering groups neurons based on the semantic similarity of the concepts detected by neurons (e.g., neurons detecting "dog faces" of different breeds are grouped); and (2) neuron embedding encodes the associations between related concepts based on how often they co-occur (e.g., neurons detecting "dog face" and "dog tail" are placed closer in the embedding space). Key to our scalable techniques is the ability to efficiently compute all neuron pairs' relationships, in time linear to the number of neurons instead of quadratic time. NeuroCartography scales to large data, such as the ImageNet dataset with 1.2M images. The system's tightly coordinated views integrate the scalable techniques to visualize the concepts and their relationships, projecting the concept associations to a 2D space in Neuron Projection View, and summarizing neuron clusters and their relationships in Graph View. Through a large-scale human evaluation, we demonstrate that our technique discovers neuron groups that represent coherent, human-meaningful concepts. And through usage scenarios, we describe how our approaches enable interesting and surprising discoveries, such as concept cascades of related and isolated concepts. The NeuroCartography visualization runs in modern browsers and is open-sourced.
Compatibility-aware Heterogeneous Visual Search
May 13, 2021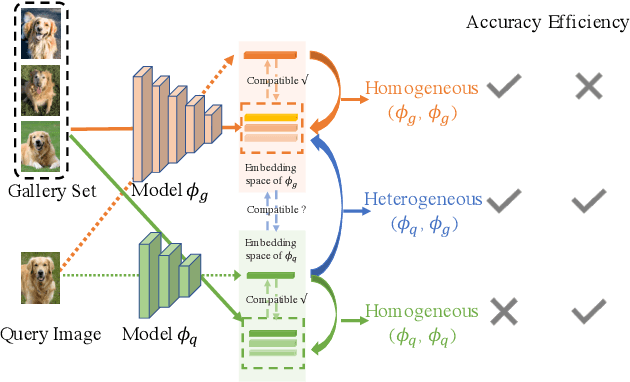

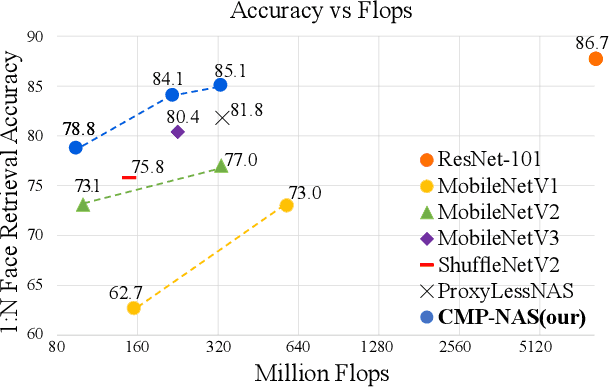
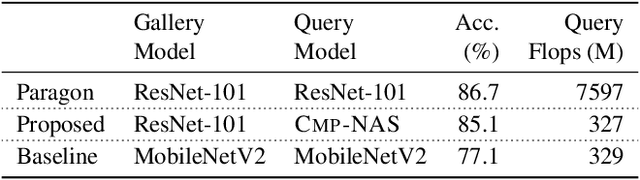
We tackle the problem of visual search under resource constraints. Existing systems use the same embedding model to compute representations (embeddings) for the query and gallery images. Such systems inherently face a hard accuracy-efficiency trade-off: the embedding model needs to be large enough to ensure high accuracy, yet small enough to enable query-embedding computation on resource-constrained platforms. This trade-off could be mitigated if gallery embeddings are generated from a large model and query embeddings are extracted using a compact model. The key to building such a system is to ensure representation compatibility between the query and gallery models. In this paper, we address two forms of compatibility: One enforced by modifying the parameters of each model that computes the embeddings. The other by modifying the architectures that compute the embeddings, leading to compatibility-aware neural architecture search (CMP-NAS). We test CMP-NAS on challenging retrieval tasks for fashion images (DeepFashion2), and face images (IJB-C). Compared to ordinary (homogeneous) visual search using the largest embedding model (paragon), CMP-NAS achieves 80-fold and 23-fold cost reduction while maintaining accuracy within 0.3% and 1.6% of the paragon on DeepFashion2 and IJB-C respectively.
MalNet: A Large-Scale Cybersecurity Image Database of Malicious Software
Jan 31, 2021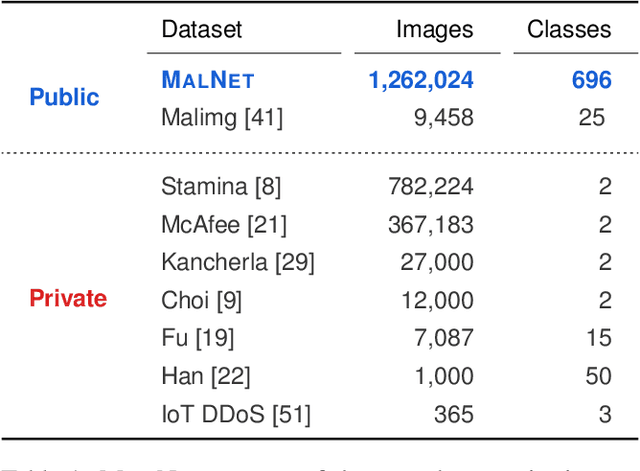
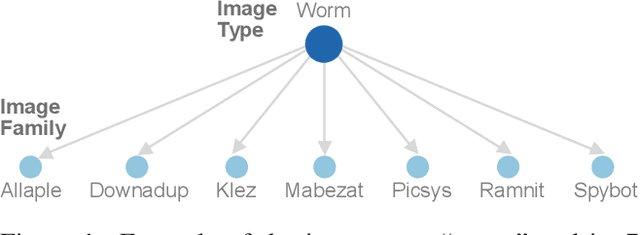
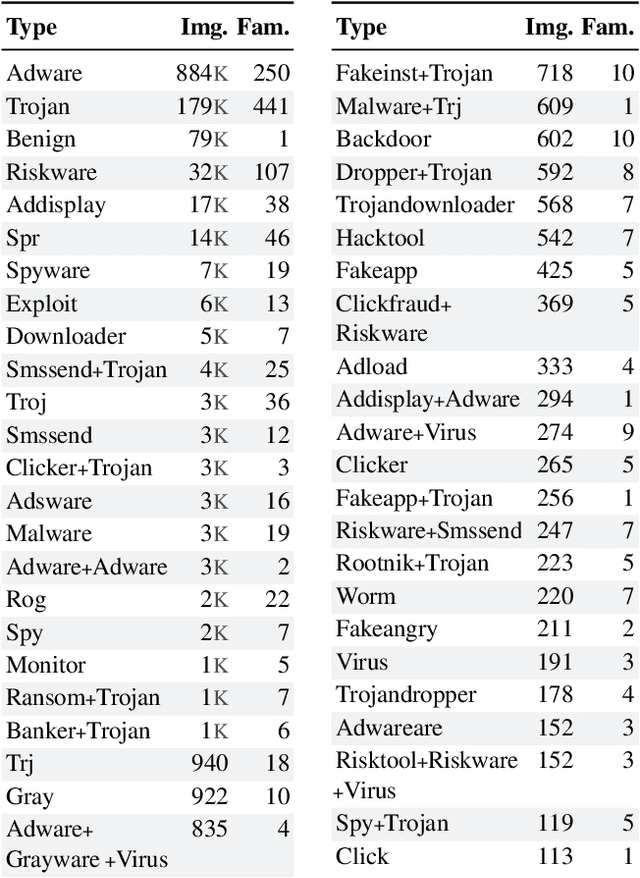
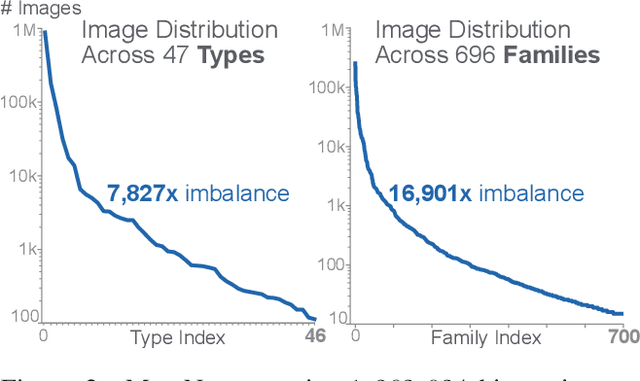
Computer vision is playing an increasingly important role in automated malware detection with to the rise of the image-based binary representation. These binary images are fast to generate, require no feature engineering, and are resilient to popular obfuscation methods. Significant research has been conducted in this area, however, it has been restricted to small-scale or private datasets that only a few industry labs and research teams have access to. This lack of availability hinders examination of existing work, development of new research, and dissemination of ideas. We introduce MalNet, the largest publicly available cybersecurity image database, offering 133x more images and 27x more classes than the only other public binary-image database. MalNet contains over 1.2 million images across a hierarchy of 47 types and 696 families. We provide extensive analysis of MalNet, discussing its properties and provenance. The scale and diversity of MalNet unlocks new and exciting cybersecurity opportunities to the computer vision community--enabling discoveries and research directions that were previously not possible. The database is publicly available at www.mal-net.org.
ELF: An Early-Exiting Framework for Long-Tailed Classification
Jun 22, 2020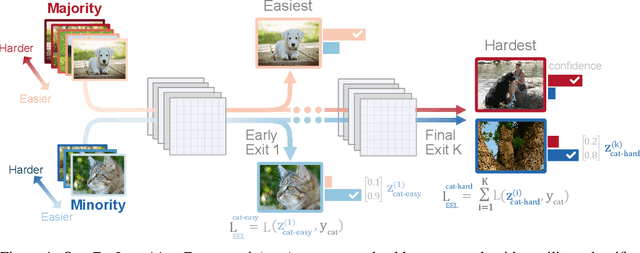
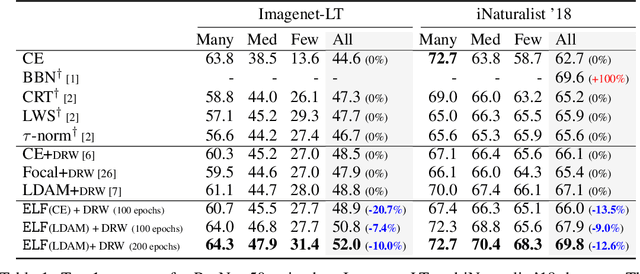

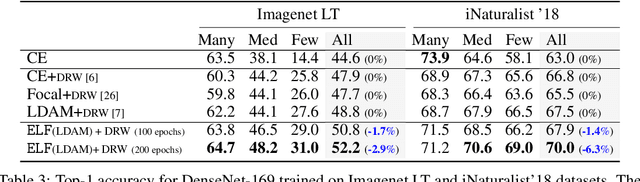
The natural world often follows a long-tailed data distribution where only a few classes account for most of the examples. This long-tail causes classifiers to overfit to the majority class. To mitigate this, prior solutions commonly adopt class rebalancing strategies such as data resampling and loss reshaping. However, by treating each example within a class equally, these methods fail to account for the important notion of example hardness, i.e., within each class some examples are easier to classify than others. To incorporate this notion of hardness into the learning process, we propose the EarLy-exiting Framework(ELF). During training, ELF learns to early-exit easy examples through auxiliary branches attached to a backbone network. This offers a dual benefit-(1) the neural network increasingly focuses on hard examples, since they contribute more to the overall network loss; and (2) it frees up additional model capacity to distinguish difficult examples. Experimental results on two large-scale datasets, ImageNet LT and iNaturalist'18, demonstrate that ELF can improve state-of-the-art accuracy by more than 3 percent. This comes with the additional benefit of reducing up to 20 percent of inference time FLOPS. ELF is complementary to prior work and can naturally integrate with a variety of existing methods to tackle the challenge of long-tailed distributions.