 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explicit Acoustic Evidence Perception in Audio LLMs for Speech Deepfake Detection
Jan 30, 2026Speech deepfake detection (SDD) focuses on identifying whether a given speech signal is genuine or has been synthetically generated. Existing audio large language model (LLM)-based methods excel in content understanding; however, their predictions are often biased toward semantically correlated cues, which results in fine-grained acoustic artifacts being overlooked during the decisionmaking process. Consequently, fake speech with natural semantics can bypass detectors despite harboring subtle acoustic anomalies; this suggests that the challenge stems not from the absence of acoustic data, but from its inadequate accessibility when semantic-dominant reasoning prevails. To address this issue, we investigate SDD within the audio LLM paradigm and introduce SDD with Auditory Perception-enhanced Audio Large Language Model (SDD-APALLM), an acoustically enhanced framework designed to explicitly expose fine-grained time-frequency evidence as accessible acoustic cues. By combining raw audio with structured spectrograms, the proposed framework empowers audio LLMs to more effectively capture subtle acoustic inconsistencies without compromising their semantic understanding. Experimental results indicate consistent gains in detection accuracy and robustness, especially in cases where semantic cues are misleading. Further analysis reveals that these improvements stem from a coordinated utilization of semantic and acoustic information, as opposed to simple modality aggregation.
EnvSSLAM-FFN: Lightweight Layer-Fused System for ESDD 2026 Challenge
Dec 23, 2025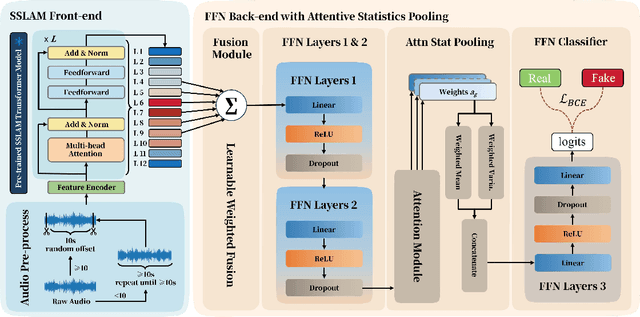
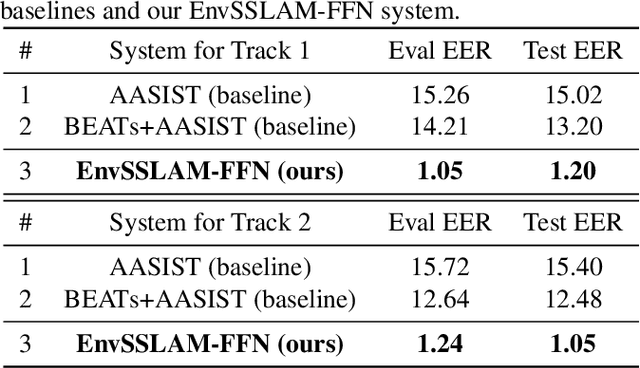
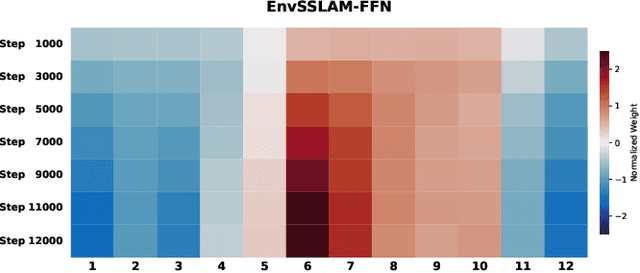
Recent advances in generative audio models have enabled high-fidelity environmental sound synthesis, raising serious concerns for audio security. The ESDD 2026 Challenge therefore addresses environmental sound deepfake detection under unseen generators (Track 1) and black-box low-resource detection (Track 2) conditions. We propose EnvSSLAM-FFN, which integrates a frozen SSLAM self-supervised encoder with a lightweight FFN back-end. To effectively capture spoofing artifacts under severe data imbalance, we fuse intermediate SSLAM representations from layers 4-9 and adopt a class-weighted training objective. Experimental results show that the proposed system consistently outperforms the official baselines on both tracks, achieving Test Equal Error Rates (EERs) of 1.20% and 1.05%, respectively.
AuthGuard: Generalizable Deepfake Detection via Language Guidance
Jun 04, 2025Existing deepfake detection techniques struggle to keep-up with the ever-evolving novel, unseen forgeries methods. This limitation stems from their reliance on statistical artifacts learned during training, which are often tied to specific generation processes that may not be representative of samples from new, unseen deepfake generation methods encountered at test time. We propose that incorporating language guidance can improve deepfake detection generalization by integrating human-like commonsense reasoning -- such as recognizing logical inconsistencies and perceptual anomalies -- alongside statistical cues. To achieve this, we train an expert deepfake vision encoder by combining discriminative classification with image-text contrastive learning, where the text is generated by generalist MLLMs using few-shot prompting. This allows the encoder to extract both language-describable, commonsense deepfake artifacts and statistical forgery artifacts from pixel-level distributions. To further enhance robustness, we integrate data uncertainty learning into vision-language contrastive learning, mitigating noise in image-text supervision. Our expert vision encoder seamlessly interfaces with an LLM, further enabling more generalized and interpretable deepfake detection while also boosting accuracy. The resulting framework, AuthGuard, achieves state-of-the-art deepfake detection accuracy in both in-distribution and out-of-distribution settings, achieving AUC gains of 6.15% on the DFDC dataset and 16.68% on the DF40 dataset. Additionally, AuthGuard significantly enhances deepfake reasoning, improving performance by 24.69% on the DDVQA dataset.
Ground-V: Teaching VLMs to Ground Complex Instructions in Pixels
May 20, 2025This work presents a simple yet effective workflow for automatically scaling instruction-following data to elicit pixel-level grounding capabilities of VLMs under complex instructions. In particular, we address five critical real-world challenges in text-instruction-based grounding: hallucinated references, multi-object scenarios, reasoning, multi-granularity, and part-level references. By leveraging knowledge distillation from a pre-trained teacher model, our approach generates high-quality instruction-response pairs linked to existing pixel-level annotations, minimizing the need for costly human annotation. The resulting dataset, Ground-V, captures rich object localization knowledge and nuanced pixel-level referring expressions. Experiment results show that models trained on Ground-V exhibit substantial improvements across diverse grounding tasks. Specifically, incorporating Ground-V during training directly achieves an average accuracy boost of 4.4% for LISA and a 7.9% for PSALM across six benchmarks on the gIoU metric. It also sets new state-of-the-art results on standard benchmarks such as RefCOCO/+/g. Notably, on gRefCOCO, we achieve an N-Acc of 83.3%, exceeding the previous state-of-the-art by more than 20%.
Optimal Transport-Guided Source-Free Adaptation for Face Anti-Spoofing
Mar 29, 2025Developing a face anti-spoofing model that meets the security requirements of clients worldwide is challenging due to the domain gap between training datasets and diverse end-user test data. Moreover, for security and privacy reasons, it is undesirable for clients to share a large amount of their face data with service providers. In this work, we introduce a novel method in which the face anti-spoofing model can be adapted by the client itself to a target domain at test time using only a small sample of data while keeping model parameters and training data inaccessible to the client. Specifically, we develop a prototype-based base model and an optimal transport-guided adaptor that enables adaptation in either a lightweight training or training-free fashion, without updating base model's parameters. Furthermore, we propose geodesic mixup, an optimal transport-based synthesis method that generates augmented training data along the geodesic path between source prototypes and target data distribution. This allows training a lightweight classifier to effectively adapt to target-specific characteristics while retaining essential knowledge learned from the source domain. In cross-domain and cross-attack settings, compared with recent methods, our method achieves average relative improvements of 19.17% in HTER and 8.58% in AUC, respectively.
Breaking the $\log(1/Δ_2)$ Barrier: Better Batched Best Arm Identification with Adaptive Grids
Jan 29, 2025

We investigate the problem of batched best arm identification in multi-armed bandits, where we aim to identify the best arm from a set of $n$ arms while minimizing both the number of samples and batches. We introduce an algorithm that achieves near-optimal sample complexity and features an instance-sensitive batch complexity, which breaks the $\log(1/\Delta_2)$ barrier. The main contribution of our algorithm is a novel sample allocation scheme that effectively balances exploration and exploitation for batch sizes. Experimental results indicate that our approach is more batch-efficient across various setups. We also extend this framework to the problem of batched best arm identification in linear bandits and achieve similar improvements.
Computing Approximate Graph Edit Distance via Optimal Transport
Dec 25, 2024Given a graph pair $(G^1, G^2)$, graph edit distance (GED) is defined as the minimum number of edit operations converting $G^1$ to $G^2$. GED is a fundamental operation widely used in many applications, but its exact computation is NP-hard, so the approximation of GED has gained a lot of attention. Data-driven learning-based methods have been found to provide superior results compared to classical approximate algorithms, but they directly fit the coupling relationship between a pair of vertices from their vertex features. We argue that while pairwise vertex features can capture the coupling cost (discrepancy) of a pair of vertices, the vertex coupling matrix should be derived from the vertex-pair cost matrix through a more well-established method that is aware of the global context of the graph pair, such as optimal transport. In this paper, we propose an ensemble approach that integrates a supervised learning-based method and an unsupervised method, both based on optimal transport. Our learning method, GEDIOT, is based on inverse optimal transport that leverages a learnable Sinkhorn algorithm to generate the coupling matrix. Our unsupervised method, GEDGW, models GED computation as a linear combination of optimal transport and its variant, Gromov-Wasserstein discrepancy, for node and edge operations, respectively, which can be solved efficiently without needing the ground truth. Our ensemble method, GEDHOT, combines GEDIOT and GEDGW to further boost the performance. Extensive experiments demonstrate that our methods significantly outperform the existing methods in terms of the performance of GED computation, edit path generation, and model generalizability.
EPIC: Efficient Position-Independent Context Caching for Serving Large Language Models
Oct 20, 2024Large Language Models (LLMs) are critical for a wide range of applications, but serving them efficiently becomes increasingly challenging as inputs become more complex. Context caching improves serving performance by exploiting inter-request dependency and reusing key-value (KV) cache across requests, thus improving time-to-first-token (TTFT). However, existing prefix-based context caching requires exact token prefix matches, limiting cache reuse in few-shot learning, multi-document QA, or retrieval-augmented generation, where prefixes may vary. In this paper, we present EPIC, an LLM serving system that introduces position-independent context caching (PIC), enabling modular KV cache reuse regardless of token chunk position (or prefix). EPIC features two key designs: AttnLink, which leverages static attention sparsity to minimize recomputation for accuracy recovery, and KVSplit, a customizable chunking method that preserves semantic coherence. Our experiments demonstrate that Epic delivers up to 8x improvements in TTFT and 7x throughput over existing systems, with negligible or no accuracy loss. By addressing the limitations of traditional caching approaches, Epic enables more scalable and efficient LLM inference.
A Robotic System for Precision Pollination in Apples: Design, Development and Field Evaluation
Sep 30, 2024



Global food production depends upon successful pollination, a process that relies on natural and managed pollinators. However, natural pollinators are declining due to different factors, including climate change, habitat loss, and pesticide use. Thus, developing alternative pollination methods is essential for sustainable crop production. This paper introduces a robotic system for precision pollination in apples, which are not self-pollinating and require precise delivery of pollen to the stigmatic surfaces of the flowers. The proposed robotic system consists of a machine vision system to identify target flowers and a mechatronic system with a 6-DOF UR5e robotic manipulator and an electrostatic sprayer. Field trials of this system in 'Honeycrisp' and 'Fuji' apple orchards have shown promising results, with the ability to pollinate flower clusters at an average spray cycle time of 6.5 seconds. The robotic pollination system has achieved encouraging fruit set and quality, comparable to naturally pollinated fruits in terms of color, weight, diameter, firmness, soluble solids, and starch content. However, the results for fruit set and quality varied between different apple cultivars and pollen concentrations. This study demonstrates the potential for a robotic artificial pollination system to be an efficient and sustainable method for commercial apple production. Further research is needed to refine the system and assess its suitability across diverse orchard environments and apple cultivars.
AgRegNet: A Deep Regression Network for Flower and Fruit Density Estimation, Localization, and Counting in Orchards
Sep 25, 2024



One of the major challenges for the agricultural industry today is the uncertainty in manual labor availability and the associated cost. Automated flower and fruit density estimation, localization, and counting could help streamline harvesting, yield estimation, and crop-load management strategies such as flower and fruitlet thinning. This article proposes a deep regression-based network, AgRegNet, to estimate density, count, and location of flower and fruit in tree fruit canopies without explicit object detection or polygon annotation. Inspired by popular U-Net architecture, AgRegNet is a U-shaped network with an encoder-to-decoder skip connection and modified ConvNeXt-T as an encoder feature extractor. AgRegNet can be trained based on information from point annotation and leverages segmentation information and attention modules (spatial and channel) to highlight relevant flower and fruit features while suppressing non-relevant background features. Experimental evaluation in apple flower and fruit canopy images under an unstructured orchard environment showed that AgRegNet achieved promising accuracy as measured by Structural Similarity Index (SSIM), percentage Mean Absolute Error (pMAE) and mean Average Precision (mAP) to estimate flower and fruit density, count, and centroid location, respectively. Specifically, the SSIM, pMAE, and mAP values for flower images were 0.938, 13.7%, and 0.81, respectively. For fruit images, the corresponding values were 0.910, 5.6%, and 0.93. Since the proposed approach relies on information from point annotation, it is suitable for sparsely and densely located objects. This simplified technique will be highly applicable for growers to accurately estimate yields and decide on optimal chemical and mechanical flower thinning practices.