 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlume Segmentation from MethaneSAT with Cross-Sensor Transfer Learning and Physics-Informed Postprocessing
May 22, 2026Automated detection and masking of individual methane plumes from satellite imagery is important for operational emission attribution and quantification. We present a machine learning framework for plume detection from MethaneSAT retrieved column-averaged dry-air mole fractions of methane. We address two core challenges: the scarcity of labeled MethaneSAT data and the need for inference reliability across diverse atmospheric and surface conditions. We first demonstrate that Mask R-CNN with a ResNet-50 backbone outperforms U-Net semantic segmentation on both MethaneAIR (an airborne version of MethaneSAT) and MethaneSAT data, with pixel-level F1 score gains of 10.49 and 5.48 respectively. To address MethaneSAT data scarcity, we evaluate three cross-sensor transfer strategies leveraging MethaneAIR flights and synthetic plumes. Mask R-CNN with ResNet-50 fine-tuned from MethaneAIR pre-trained weights is the most effective strategy, achieving instance-level precision of 0.60 and a near-perfect recall of 0.98 at the baseline operating point. A physics-informed post-processing pipeline converts detections into two operationally distinct modes. The first is a high-sensitivity mode that applies morphological filtering and proximity-based merging for comprehensive emission screening, achieving precision of 0.71 and recall of 0.94. The second is a high-precision mode that additionally applies a distribution-based classifier for confident source attribution, achieving precision of 0.92 and recall of 0.70. Manual review of detections classified as false positives against our wavelet-based ground truth labels reveals that a meaningful fraction of cases correspond to real methane enhancements excluded by conservative labeling criteria, indicating that precision values reported are lower bounds on true detection performance... Our data and code are available at: https://doi.org/10.7910/DVN/FR959H
Thermodynamic Focusing for Inference-Time Search: Practical Methods for Target-Conditioned Sampling and Prompted Inference
Dec 16, 2025Finding rare but useful solutions in very large candidate spaces is a recurring practical challenge across language generation, planning, and reinforcement learning. We present a practical framework, \emph{Inverted Causality Focusing Algorithm} (ICFA), that treats search as a target-conditioned reweighting process. ICFA reuses an available proposal sampler and a task-specific similarity function to form a focused sampling distribution, while adaptively controlling focusing strength to avoid degeneracy. We provide a clear recipe, a stability diagnostic based on effective sample size, a compact theoretical sketch explaining when ICFA can reduce sample needs, and two reproducible experiments: constrained language generation and sparse-reward navigation. We further show how structured prompts instantiate an approximate, language-level form of ICFA and describe a hybrid architecture combining prompted inference with algorithmic reweighting.
CorrectAD: A Self-Correcting Agentic System to Improve End-to-end Planning in Autonomous Driving
Nov 17, 2025End-to-end planning methods are the de facto standard of the current autonomous driving system, while the robustness of the data-driven approaches suffers due to the notorious long-tail problem (i.e., rare but safety-critical failure cases). In this work, we explore whether recent diffusion-based video generation methods (a.k.a. world models), paired with structured 3D layouts, can enable a fully automated pipeline to self-correct such failure cases. We first introduce an agent to simulate the role of product manager, dubbed PM-Agent, which formulates data requirements to collect data similar to the failure cases. Then, we use a generative model that can simulate both data collection and annotation. However, existing generative models struggle to generate high-fidelity data conditioned on 3D layouts. To address this, we propose DriveSora, which can generate spatiotemporally consistent videos aligned with the 3D annotations requested by PM-Agent. We integrate these components into our self-correcting agentic system, CorrectAD. Importantly, our pipeline is an end-to-end model-agnostic and can be applied to improve any end-to-end planner. Evaluated on both nuScenes and a more challenging in-house dataset across multiple end-to-end planners, CorrectAD corrects 62.5% and 49.8% of failure cases, reducing collision rates by 39% and 27%, respectively.
Methodology and Real-World Applications of Dynamic Uncertain Causality Graph for Clinical Diagnosis with Explainability and Invariance
Jun 09, 2024AI-aided clinical diagnosis is desired in medical care. Existing deep learning models lack explainability and mainly focus on image analysis. The recently developed Dynamic Uncertain Causality Graph (DUCG) approach is causality-driven, explainable, and invariant across different application scenarios, without problems of data collection, labeling, fitting, privacy, bias, generalization, high cost and high energy consumption. Through close collaboration between clinical experts and DUCG technicians, 46 DUCG models covering 54 chief complaints were constructed. Over 1,000 diseases can be diagnosed without triage. Before being applied in real-world, the 46 DUCG models were retrospectively verified by third-party hospitals. The verified diagnostic precisions were no less than 95%, in which the diagnostic precision for every disease including uncommon ones was no less than 80%. After verifications, the 46 DUCG models were applied in the real-world in China. Over one million real diagnosis cases have been performed, with only 17 incorrect diagnoses identified. Due to DUCG's transparency, the mistakes causing the incorrect diagnoses were found and corrected. The diagnostic abilities of the clinicians who applied DUCG frequently were improved significantly. Following the introduction to the earlier presented DUCG methodology, the recommendation algorithm for potential medical checks is presented and the key idea of DUCG is extracted.
Unleashing Generalization of End-to-End Autonomous Driving with Controllable Long Video Generation
Jun 03, 2024Using generative models to synthesize new data has become a de-facto standard in autonomous driving to address the data scarcity issue. Though existing approaches are able to boost perception models, we discover that these approaches fail to improve the performance of planning of end-to-end autonomous driving models as the generated videos are usually less than 8 frames and the spatial and temporal inconsistencies are not negligible. To this end, we propose Delphi, a novel diffusion-based long video generation method with a shared noise modeling mechanism across the multi-views to increase spatial consistency, and a feature-aligned module to achieves both precise controllability and temporal consistency. Our method can generate up to 40 frames of video without loss of consistency which is about 5 times longer compared with state-of-the-art methods. Instead of randomly generating new data, we further design a sampling policy to let Delphi generate new data that are similar to those failure cases to improve the sample efficiency. This is achieved by building a failure-case driven framework with the help of pre-trained visual language models. Our extensive experiment demonstrates that our Delphi generates a higher quality of long videos surpassing previous state-of-the-art methods. Consequentially, with only generating 4% of the training dataset size, our framework is able to go beyond perception and prediction tasks, for the first time to the best of our knowledge, boost the planning performance of the end-to-end autonomous driving model by a margin of 25%.
LuoJiaHOG: A Hierarchy Oriented Geo-aware Image Caption Dataset for Remote Sensing Image-Text Retrival
Mar 16, 2024Image-text retrieval (ITR) plays a significant role in making informed decisions for various remote sensing (RS) applications. Nonetheless, creating ITR datasets containing vision and language modalities not only requires significant geo-spatial sampling area but also varing categories and detailed descriptions. To this end, we introduce an image caption dataset LuojiaHOG, which is geospatial-aware, label-extension-friendly and comprehensive-captioned. LuojiaHOG involves the hierarchical spatial sampling, extensible classification system to Open Geospatial Consortium (OGC) standards, and detailed caption generation. In addition, we propose a CLIP-based Image Semantic Enhancement Network (CISEN) to promote sophisticated ITR. CISEN consists of two components, namely dual-path knowledge transfer and progressive cross-modal feature fusion. Comprehensive statistics on LuojiaHOG reveal the richness in sampling diversity, labels quantity and descriptions granularity. The evaluation on LuojiaHOG is conducted across various state-of-the-art ITR models, including ALBEF, ALIGN, CLIP, FILIP, Wukong, GeoRSCLIP and CISEN. We use second- and third-level labels to evaluate these vision-language models through adapter-tuning and CISEN demonstrates superior performance. For instance, it achieves the highest scores with WMAP@5 of 88.47\% and 87.28\% on third-level ITR tasks, respectively. In particular, CISEN exhibits an improvement of approximately 1.3\% and 0.9\% in terms of WMAP@5 compared to its baseline. These findings highlight CISEN advancements accurately retrieving pertinent information across image and text. LuojiaHOG and CISEN can serve as a foundational resource for future RS image-text alignment research, facilitating a wide range of vision-language applications.
Mispronunciation Detection and Correction via Discrete Acoustic Units
Aug 12, 2021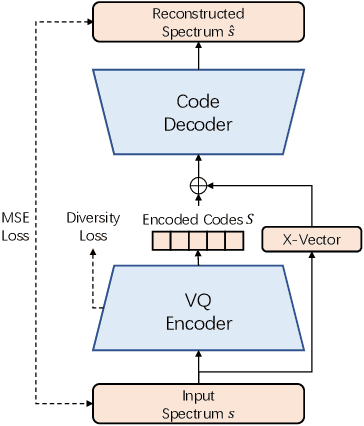

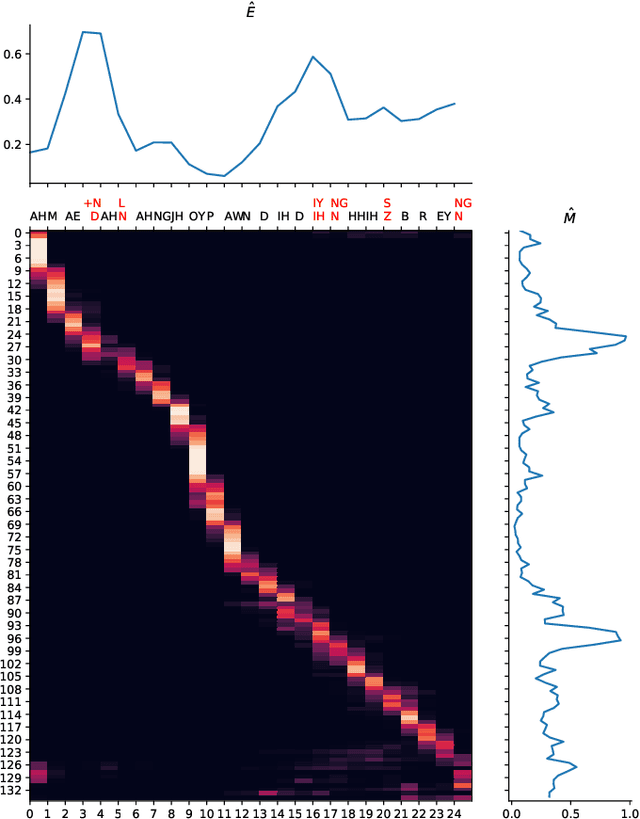
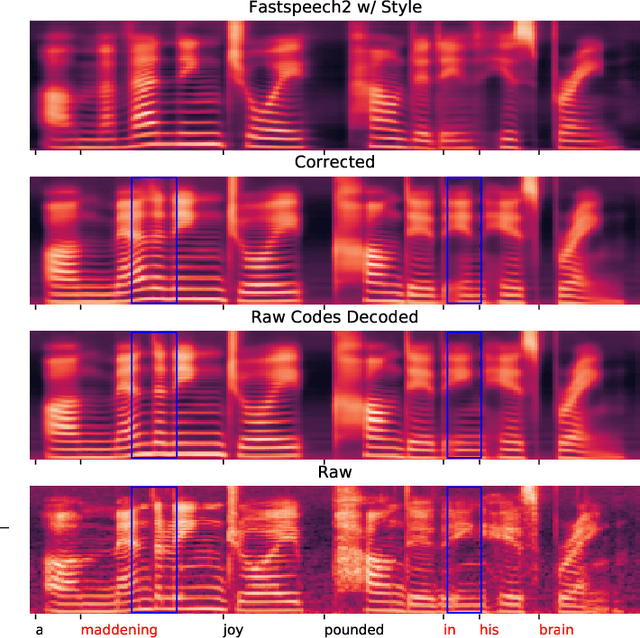
Computer-Assisted Pronunciation Training (CAPT) plays an important role in language learning. However, conventional CAPT methods cannot effectively use non-native utterances for supervised training because the ground truth pronunciation needs expensive annotation. Meanwhile, certain undefined nonnative phonemes cannot be correctly classified into standard phonemes. To solve these problems, we use the vector-quantized variational autoencoder (VQ-VAE) to encode the speech into discrete acoustic units in a self-supervised manner. Based on these units, we propose a novel method that integrates both discriminative and generative models. The proposed method can detect mispronunciation and generate the correct pronunciation at the same time. Experiments on the L2-Arctic dataset show that the detection F1 score is improved by 9.58% relatively compared with recognition-based methods. The proposed method also achieves a comparable word error rate (WER) and the best style preservation for mispronunciation correction compared with text-to-speech (TTS) methods.
Gaze-Contingent Retinal Speckle Suppression for Perceptually-Matched Foveated Holographic Displays
Aug 10, 2021



Computer-generated holographic (CGH) displays show great potential and are emerging as the next-generation displays for augmented and virtual reality, and automotive heads-up displays. One of the critical problems harming the wide adoption of such displays is the presence of speckle noise inherent to holography, that compromises its quality by introducing perceptible artifacts. Although speckle noise suppression has been an active research area, the previous works have not considered the perceptual characteristics of the Human Visual System (HVS), which receives the final displayed imagery. However, it is well studied that the sensitivity of the HVS is not uniform across the visual field, which has led to gaze-contingent rendering schemes for maximizing the perceptual quality in various computer-generated imagery. Inspired by this, we present the first method that reduces the "perceived speckle noise" by integrating foveal and peripheral vision characteristics of the HVS, along with the retinal point spread function, into the phase hologram computation. Specifically, we introduce the anatomical and statistical retinal receptor distribution into our computational hologram optimization, which places a higher priority on reducing the perceived foveal speckle noise while being adaptable to any individual's optical aberration on the retina. Our method demonstrates superior perceptual quality on our emulated holographic display. Our evaluations with objective measurements and subjective studies demonstrate a significant reduction of the human perceived noise.
Accent Recognition with Hybrid Phonetic Features
May 05, 2021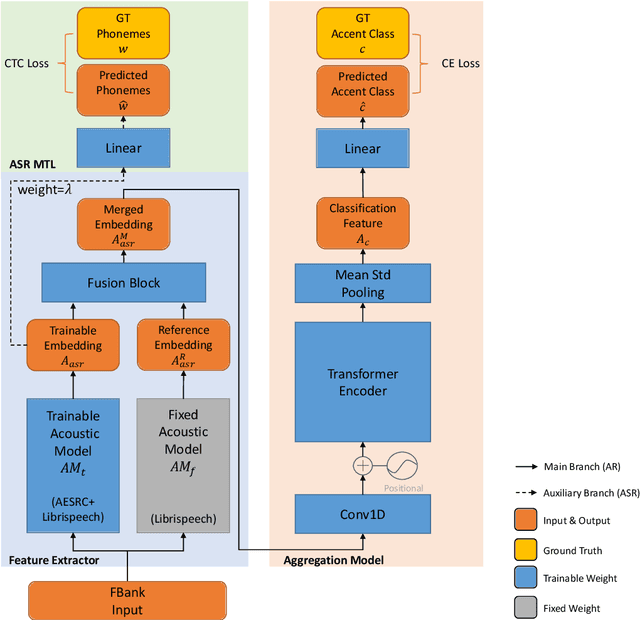

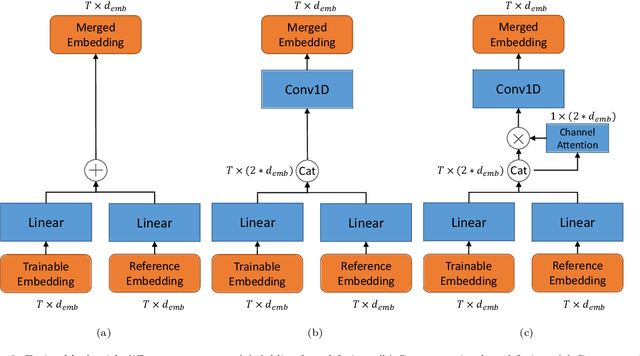
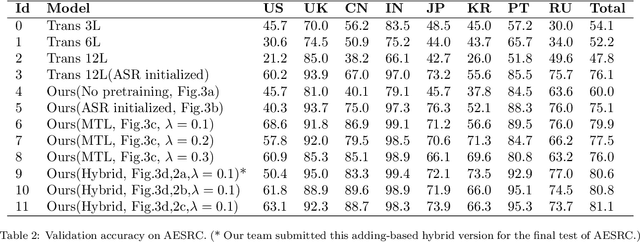
The performance of voice-controlled systems is usually influenced by accented speech. To make these systems more robust, the frontend accent recognition (AR) technologies have received increased attention in recent years. As accent is a high-level abstract feature that has a profound relationship with the language knowledge, AR is more challenging than other language-agnostic audio classification tasks. In this paper, we use an auxiliary automatic speech recognition (ASR) task to extract language-related phonetic features. Furthermore, we propose a hybrid structure that incorporates the embeddings of both a fixed acoustic model and a trainable acoustic model, making the language-related acoustic feature more robust. We conduct several experiments on the Accented English Speech Recognition Challenge (AESRC) 2020 dataset. The results demonstrate that our approach can obtain a 6.57% relative improvement on the validation set. We also get a 7.28% relative improvement on the final test set for this competition, showing the merits of the proposed method.
CASS: Towards Building a Social-Support Chatbot for Online Health Community
Feb 04, 2021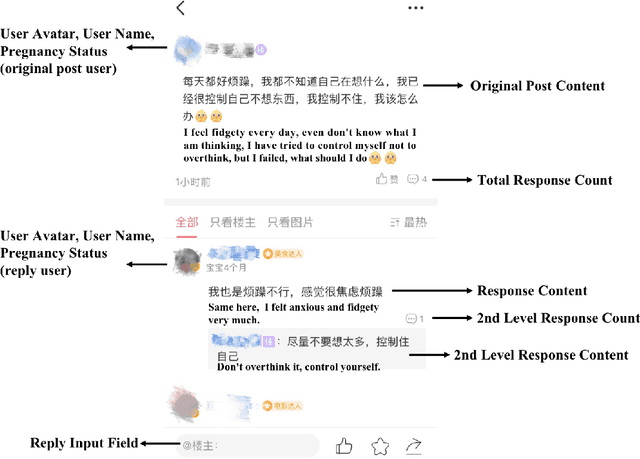
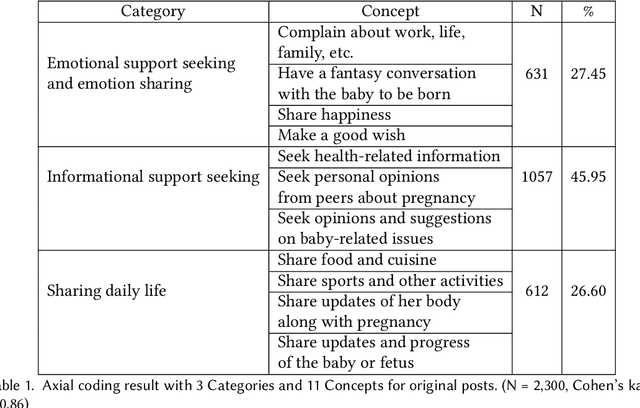
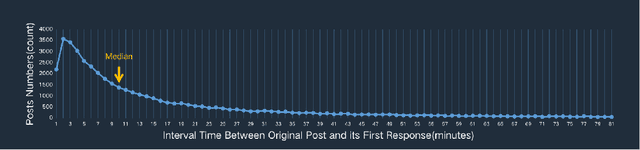
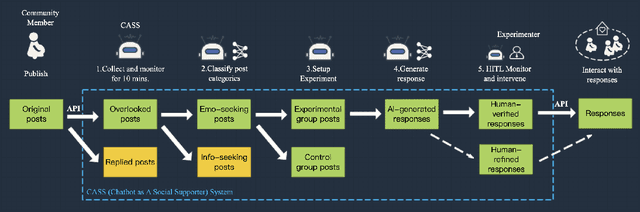
Chatbots systems, despite their popularity in today's HCI and CSCW research, fall short for one of the two reasons: 1) many of the systems use a rule-based dialog flow, thus they can only respond to a limited number of pre-defined inputs with pre-scripted responses; or 2) they are designed with a focus on single-user scenarios, thus it is unclear how these systems may affect other users or the community. In this paper, we develop a generalizable chatbot architecture (CASS) to provide social support for community members in an online health community. The CASS architecture is based on advanced neural network algorithms, thus it can handle new inputs from users and generate a variety of responses to them. CASS is also generalizable as it can be easily migrate to other online communities. With a follow-up field experiment, CASS is proven useful in supporting individual members who seek emotional support. Our work also contributes to fill the research gap on how a chatbot may influence the whole community's engagement.