 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveLaW:Unifying Planning and Video Generation in a Latent Driving World
Dec 31, 2025World models have become crucial for autonomous driving, as they learn how scenarios evolve over time to address the long-tail challenges of the real world. However, current approaches relegate world models to limited roles: they operate within ostensibly unified architectures that still keep world prediction and motion planning as decoupled processes. To bridge this gap, we propose DriveLaW, a novel paradigm that unifies video generation and motion planning. By directly injecting the latent representation from its video generator into the planner, DriveLaW ensures inherent consistency between high-fidelity future generation and reliable trajectory planning. Specifically, DriveLaW consists of two core components: DriveLaW-Video, our powerful world model that generates high-fidelity forecasting with expressive latent representations, and DriveLaW-Act, a diffusion planner that generates consistent and reliable trajectories from the latent of DriveLaW-Video, with both components optimized by a three-stage progressive training strategy. The power of our unified paradigm is demonstrated by new state-of-the-art results across both tasks. DriveLaW not only advances video prediction significantly, surpassing best-performing work by 33.3% in FID and 1.8% in FVD, but also achieves a new record on the NAVSIM planning benchmark.
CorrectAD: A Self-Correcting Agentic System to Improve End-to-end Planning in Autonomous Driving
Nov 17, 2025End-to-end planning methods are the de facto standard of the current autonomous driving system, while the robustness of the data-driven approaches suffers due to the notorious long-tail problem (i.e., rare but safety-critical failure cases). In this work, we explore whether recent diffusion-based video generation methods (a.k.a. world models), paired with structured 3D layouts, can enable a fully automated pipeline to self-correct such failure cases. We first introduce an agent to simulate the role of product manager, dubbed PM-Agent, which formulates data requirements to collect data similar to the failure cases. Then, we use a generative model that can simulate both data collection and annotation. However, existing generative models struggle to generate high-fidelity data conditioned on 3D layouts. To address this, we propose DriveSora, which can generate spatiotemporally consistent videos aligned with the 3D annotations requested by PM-Agent. We integrate these components into our self-correcting agentic system, CorrectAD. Importantly, our pipeline is an end-to-end model-agnostic and can be applied to improve any end-to-end planner. Evaluated on both nuScenes and a more challenging in-house dataset across multiple end-to-end planners, CorrectAD corrects 62.5% and 49.8% of failure cases, reducing collision rates by 39% and 27%, respectively.
Rethinking Driving World Model as Synthetic Data Generator for Perception Tasks
Oct 22, 2025Recent advancements in driving world models enable controllable generation of high-quality RGB videos or multimodal videos. Existing methods primarily focus on metrics related to generation quality and controllability. However, they often overlook the evaluation of downstream perception tasks, which are $\mathbf{really\ crucial}$ for the performance of autonomous driving. Existing methods usually leverage a training strategy that first pretrains on synthetic data and finetunes on real data, resulting in twice the epochs compared to the baseline (real data only). When we double the epochs in the baseline, the benefit of synthetic data becomes negligible. To thoroughly demonstrate the benefit of synthetic data, we introduce Dream4Drive, a novel synthetic data generation framework designed for enhancing the downstream perception tasks. Dream4Drive first decomposes the input video into several 3D-aware guidance maps and subsequently renders the 3D assets onto these guidance maps. Finally, the driving world model is fine-tuned to produce the edited, multi-view photorealistic videos, which can be used to train the downstream perception models. Dream4Drive enables unprecedented flexibility in generating multi-view corner cases at scale, significantly boosting corner case perception in autonomous driving. To facilitate future research, we also contribute a large-scale 3D asset dataset named DriveObj3D, covering the typical categories in driving scenarios and enabling diverse 3D-aware video editing. We conduct comprehensive experiments to show that Dream4Drive can effectively boost the performance of downstream perception models under various training epochs. Project: $\href{https://wm-research.github.io/Dream4Drive/}{this\ https\ URL}$
Genesis: Multimodal Driving Scene Generation with Spatio-Temporal and Cross-Modal Consistency
Jun 09, 2025We present Genesis, a unified framework for joint generation of multi-view driving videos and LiDAR sequences with spatio-temporal and cross-modal consistency. Genesis employs a two-stage architecture that integrates a DiT-based video diffusion model with 3D-VAE encoding, and a BEV-aware LiDAR generator with NeRF-based rendering and adaptive sampling. Both modalities are directly coupled through a shared latent space, enabling coherent evolution across visual and geometric domains. To guide the generation with structured semantics, we introduce DataCrafter, a captioning module built on vision-language models that provides scene-level and instance-level supervision. Extensive experiments on the nuScenes benchmark demonstrate that Genesis achieves state-of-the-art performance across video and LiDAR metrics (FVD 16.95, FID 4.24, Chamfer 0.611), and benefits downstream tasks including segmentation and 3D detection, validating the semantic fidelity and practical utility of the generated data.
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Jun 09, 2025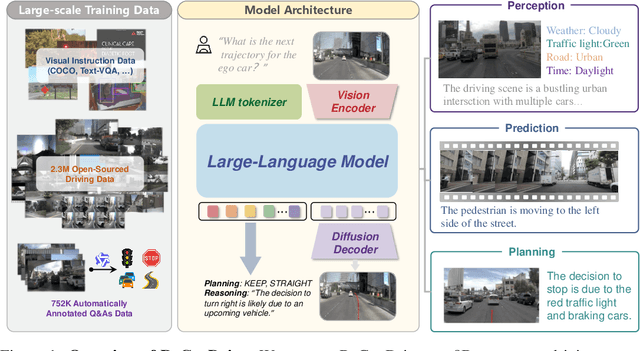
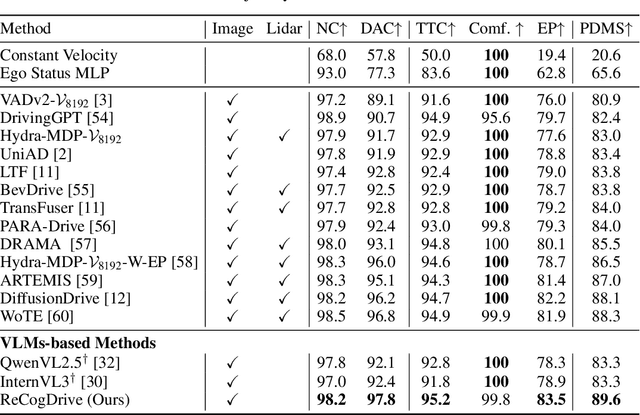
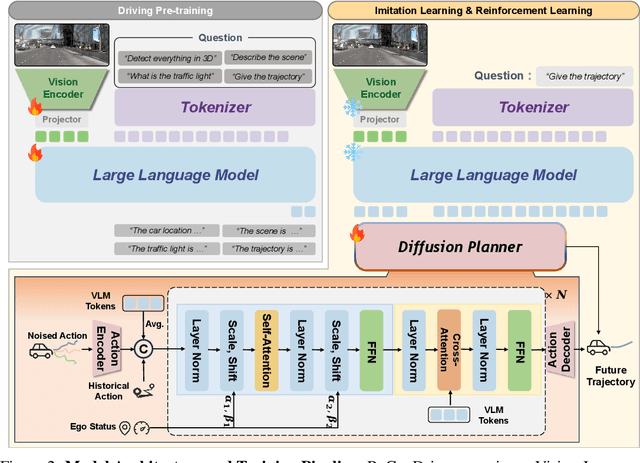
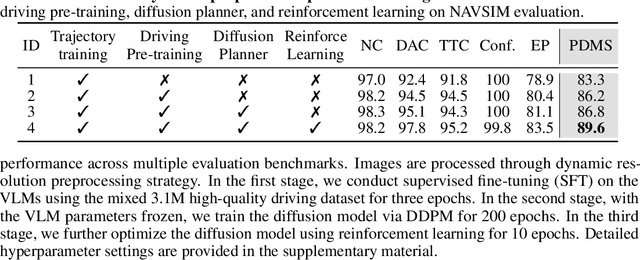
Although end-to-end autonomous driving has made remarkable progress, its performance degrades significantly in rare and long-tail scenarios. Recent approaches attempt to address this challenge by leveraging the rich world knowledge of Vision-Language Models (VLMs), but these methods suffer from several limitations: (1) a significant domain gap between the pre-training data of VLMs and real-world driving data, (2) a dimensionality mismatch between the discrete language space and the continuous action space, and (3) imitation learning tends to capture the average behavior present in the dataset, which may be suboptimal even dangerous. In this paper, we propose ReCogDrive, an autonomous driving system that integrates VLMs with diffusion planner, which adopts a three-stage paradigm for training. In the first stage, we use a large-scale driving question-answering datasets to train the VLMs, mitigating the domain discrepancy between generic content and real-world driving scenarios. In the second stage, we employ a diffusion-based planner to perform imitation learning, mapping representations from the latent language space to continuous driving actions. Finally, we fine-tune the diffusion planner using reinforcement learning with NAVSIM non-reactive simulator, enabling the model to generate safer, more human-like driving trajectories. We evaluate our approach on the planning-oriented NAVSIM benchmark, achieving a PDMS of 89.6 and setting a new state-of-the-art that surpasses the previous vision-only SOTA by 5.6 PDMS.
CoGen: 3D Consistent Video Generation via Adaptive Conditioning for Autonomous Driving
Mar 28, 2025Recent progress in driving video generation has shown significant potential for enhancing self-driving systems by providing scalable and controllable training data. Although pretrained state-of-the-art generation models, guided by 2D layout conditions (e.g., HD maps and bounding boxes), can produce photorealistic driving videos, achieving controllable multi-view videos with high 3D consistency remains a major challenge. To tackle this, we introduce a novel spatial adaptive generation framework, CoGen, which leverages advances in 3D generation to improve performance in two key aspects: (i) To ensure 3D consistency, we first generate high-quality, controllable 3D conditions that capture the geometry of driving scenes. By replacing coarse 2D conditions with these fine-grained 3D representations, our approach significantly enhances the spatial consistency of the generated videos. (ii) Additionally, we introduce a consistency adapter module to strengthen the robustness of the model to multi-condition control. The results demonstrate that this method excels in preserving geometric fidelity and visual realism, offering a reliable video generation solution for autonomous driving.
DiVE: DiT-based Video Generation with Enhanced Control
Sep 03, 2024



Generating high-fidelity, temporally consistent videos in autonomous driving scenarios faces a significant challenge, e.g. problematic maneuvers in corner cases. Despite recent video generation works are proposed to tackcle the mentioned problem, i.e. models built on top of Diffusion Transformers (DiT), works are still missing which are targeted on exploring the potential for multi-view videos generation scenarios. Noticeably, we propose the first DiT-based framework specifically designed for generating temporally and multi-view consistent videos which precisely match the given bird's-eye view layouts control. Specifically, the proposed framework leverages a parameter-free spatial view-inflated attention mechanism to guarantee the cross-view consistency, where joint cross-attention modules and ControlNet-Transformer are integrated to further improve the precision of control. To demonstrate our advantages, we extensively investigate the qualitative comparisons on nuScenes dataset, particularly in some most challenging corner cases. In summary, the effectiveness of our proposed method in producing long, controllable, and highly consistent videos under difficult conditions is proven to be effective.
UA-Track: Uncertainty-Aware End-to-End 3D Multi-Object Tracking
Jun 04, 2024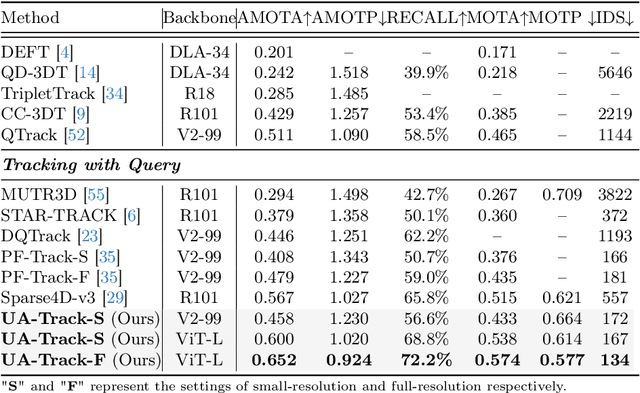
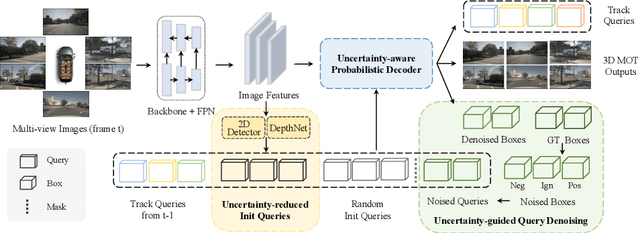
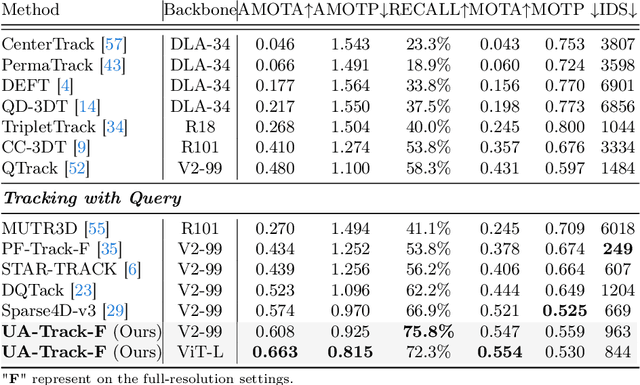

3D multiple object tracking (MOT) plays a crucial role in autonomous driving perception. Recent end-to-end query-based trackers simultaneously detect and track objects, which have shown promising potential for the 3D MOT task. However, existing methods overlook the uncertainty issue, which refers to the lack of precise confidence about the state and location of tracked objects. Uncertainty arises owing to various factors during motion observation by cameras, especially occlusions and the small size of target objects, resulting in an inaccurate estimation of the object's position, label, and identity. To this end, we propose an Uncertainty-Aware 3D MOT framework, UA-Track, which tackles the uncertainty problem from multiple aspects. Specifically, we first introduce an Uncertainty-aware Probabilistic Decoder to capture the uncertainty in object prediction with probabilistic attention. Secondly, we propose an Uncertainty-guided Query Denoising strategy to further enhance the training process. We also utilize Uncertainty-reduced Query Initialization, which leverages predicted 2D object location and depth information to reduce query uncertainty. As a result, our UA-Track achieves state-of-the-art performance on the nuScenes benchmark, i.e., 66.3% AMOTA on the test split, surpassing the previous best end-to-end solution by a significant margin of 8.9% AMOTA.
Unleashing Generalization of End-to-End Autonomous Driving with Controllable Long Video Generation
Jun 03, 2024Using generative models to synthesize new data has become a de-facto standard in autonomous driving to address the data scarcity issue. Though existing approaches are able to boost perception models, we discover that these approaches fail to improve the performance of planning of end-to-end autonomous driving models as the generated videos are usually less than 8 frames and the spatial and temporal inconsistencies are not negligible. To this end, we propose Delphi, a novel diffusion-based long video generation method with a shared noise modeling mechanism across the multi-views to increase spatial consistency, and a feature-aligned module to achieves both precise controllability and temporal consistency. Our method can generate up to 40 frames of video without loss of consistency which is about 5 times longer compared with state-of-the-art methods. Instead of randomly generating new data, we further design a sampling policy to let Delphi generate new data that are similar to those failure cases to improve the sample efficiency. This is achieved by building a failure-case driven framework with the help of pre-trained visual language models. Our extensive experiment demonstrates that our Delphi generates a higher quality of long videos surpassing previous state-of-the-art methods. Consequentially, with only generating 4% of the training dataset size, our framework is able to go beyond perception and prediction tasks, for the first time to the best of our knowledge, boost the planning performance of the end-to-end autonomous driving model by a margin of 25%.
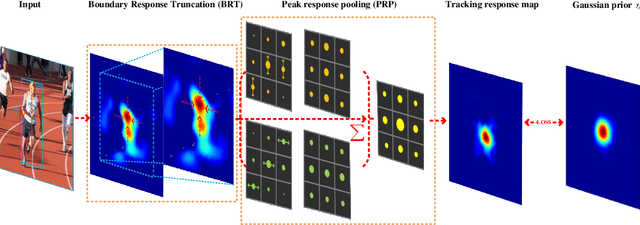
SPSTracker: Sub-Peak Suppression of Response Map for Robust Object Tracking
Jan 24, 2020


I'm sorry, Table2,3(VOT2016,2018) do not match figure6,7(VOT2016,2018).More experiments need to be added. However, this replacement version may take a lot of time, because a lot of experiments need to be done again, and now because of the Chinese Spring Festival and the 2019 novel coronavirus (2019-nCoV) can't do experiments, in order to ensure the rigor of the paper, I applied to withdraw the manuscript, and then resubmit it after the replacement version.