 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRMFA-Net: A Neural ISP for Real RAW to RGB Image Reconstruction
Jun 17, 2024



Deep learning-based ISP algorithms have demonstrated significant potential in raw2rgb reconstruction. However, existing networks have not fully considered the specific characteristics of raw data, such as black level and CFA, which can negatively impact texture and color if mishandled. Moreover, uneven exposure in raw data is also not considered carefully, leading to adverse effects on contrast and brightness. In this paper, we introduce RMFA-Net to tackle these problems. We perform implicit black level correction to mitigate color shifts in dim scenes. To preserve high-frequency information and prevent misalignment, we propose a novel Three-Channel-Split mode. To address the issue of uneven exposure, we designed an explicit tone mapping module based on the Retinex theory. We train and evaluate our models using the dataset released by the Mobile AI 2022 Learned Smartphone ISP Challenge. It is demonstrated that RMFA-Net outperforms previous algorithms, achieving a PSNR score of over 25 dB, surpassing the state-of-the-art by +1 dB. Furthermore, we developed a lightweight version, RMFANet-tiny, for engineering deployment while still maintaining strong performance, surpassing the SOTA by +0.5 dB.
UA-Track: Uncertainty-Aware End-to-End 3D Multi-Object Tracking
Jun 04, 2024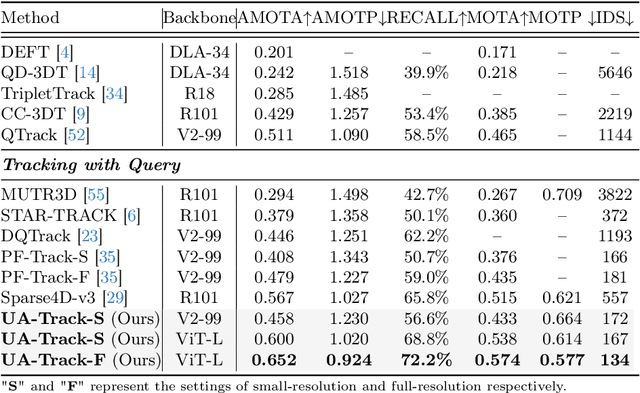
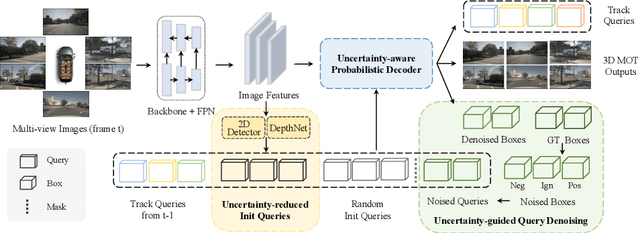
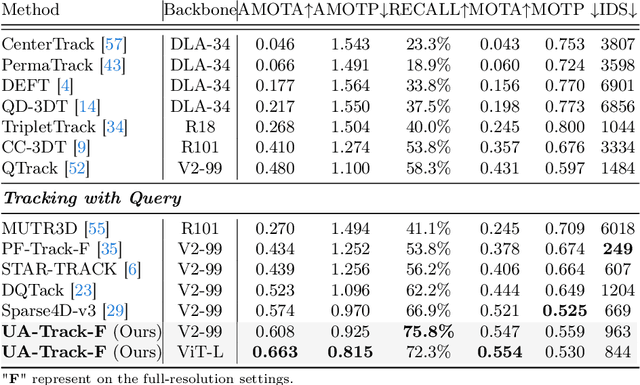

3D multiple object tracking (MOT) plays a crucial role in autonomous driving perception. Recent end-to-end query-based trackers simultaneously detect and track objects, which have shown promising potential for the 3D MOT task. However, existing methods overlook the uncertainty issue, which refers to the lack of precise confidence about the state and location of tracked objects. Uncertainty arises owing to various factors during motion observation by cameras, especially occlusions and the small size of target objects, resulting in an inaccurate estimation of the object's position, label, and identity. To this end, we propose an Uncertainty-Aware 3D MOT framework, UA-Track, which tackles the uncertainty problem from multiple aspects. Specifically, we first introduce an Uncertainty-aware Probabilistic Decoder to capture the uncertainty in object prediction with probabilistic attention. Secondly, we propose an Uncertainty-guided Query Denoising strategy to further enhance the training process. We also utilize Uncertainty-reduced Query Initialization, which leverages predicted 2D object location and depth information to reduce query uncertainty. As a result, our UA-Track achieves state-of-the-art performance on the nuScenes benchmark, i.e., 66.3% AMOTA on the test split, surpassing the previous best end-to-end solution by a significant margin of 8.9% AMOTA.
DuBox: No-Prior Box Objection Detection via Residual Dual Scale Detectors
Apr 16, 2019

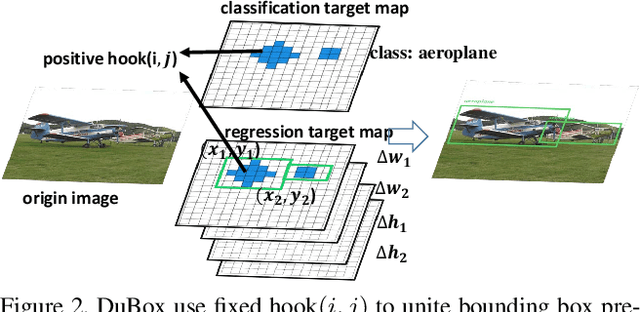
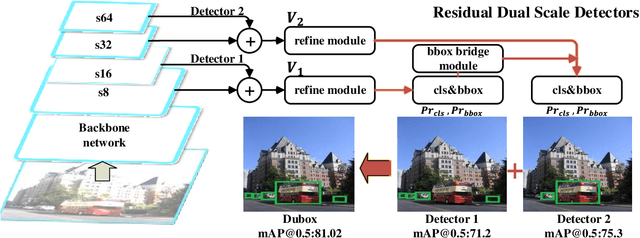
Traditional neural objection detection methods use multi-scale features that allow multiple detectors to perform detecting tasks independently and in parallel. At the same time, with the handling of the prior box, the algorithm's ability to deal with scale invariance is enhanced. However, too many prior boxes and independent detectors will increase the computational redundancy of the detection algorithm. In this study, we introduce Dubox, a new one-stage approach that detects the objects without prior box. Working with multi-scale features, the designed dual scale residual unit makes dual scale detectors no longer run independently. The second scale detector learns the residual of the first. Dubox has enhanced the capacity of heuristic-guided that can further enable the first scale detector to maximize the detection of small targets and the second to detect objects that cannot be identified by the first one. Besides, for each scale detector, with the new classification-regression progressive strapped loss makes our process not based on prior boxes. Integrating these strategies, our detection algorithm has achieved excellent performance in terms of speed and accuracy. Extensive experiments on the VOC, COCO object detection benchmark have confirmed the effectiveness of this algorithm.
Shape Robust Text Detection with Progressive Scale Expansion Network
Mar 28, 2019
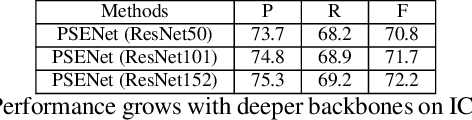

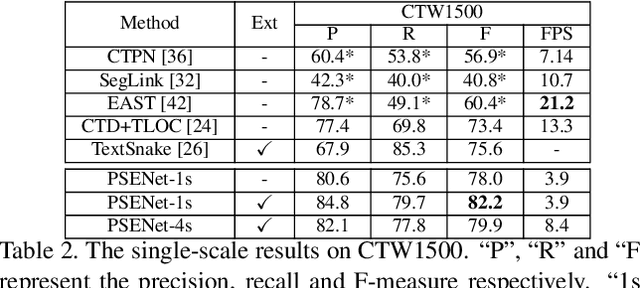
Scene text detection has witnessed rapid progress especially with the recent development of convolutional neural networks. However, there still exists two challenges which prevent the algorithm into industry applications. On the one hand, most of the state-of-art algorithms require quadrangle bounding box which is in-accurate to locate the texts with arbitrary shape. On the other hand, two text instances which are close to each other may lead to a false detection which covers both instances. Traditionally, the segmentation-based approach can relieve the first problem but usually fail to solve the second challenge. To address these two challenges, in this paper, we propose a novel Progressive Scale Expansion Network (PSENet), which can precisely detect text instances with arbitrary shapes. More specifically, PSENet generates the different scale of kernels for each text instance, and gradually expands the minimal scale kernel to the text instance with the complete shape. Due to the fact that there are large geometrical margins among the minimal scale kernels, our method is effective to split the close text instances, making it easier to use segmentation-based methods to detect arbitrary-shaped text instances. Extensive experiments on CTW1500, Total-Text, ICDAR 2015 and ICDAR 2017 MLT validate the effectiveness of PSENet. Notably, on CTW1500, a dataset full of long curve texts, PSENet achieves a F-measure of 74.3% at 27 FPS, and our best F-measure (82.2%) outperforms state-of-art algorithms by 6.6%. The code will be released in the future.