 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUA-Track: Uncertainty-Aware End-to-End 3D Multi-Object Tracking
Jun 04, 2024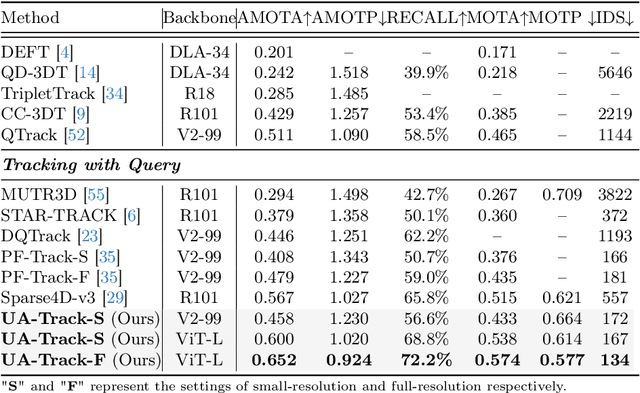
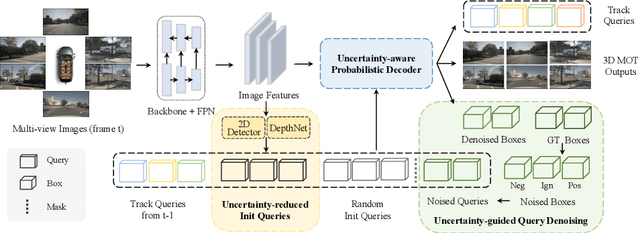
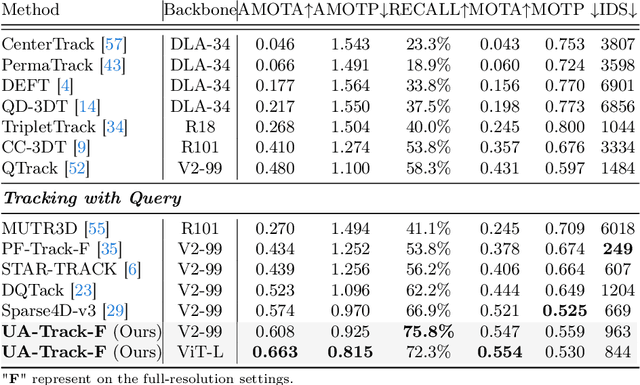

3D multiple object tracking (MOT) plays a crucial role in autonomous driving perception. Recent end-to-end query-based trackers simultaneously detect and track objects, which have shown promising potential for the 3D MOT task. However, existing methods overlook the uncertainty issue, which refers to the lack of precise confidence about the state and location of tracked objects. Uncertainty arises owing to various factors during motion observation by cameras, especially occlusions and the small size of target objects, resulting in an inaccurate estimation of the object's position, label, and identity. To this end, we propose an Uncertainty-Aware 3D MOT framework, UA-Track, which tackles the uncertainty problem from multiple aspects. Specifically, we first introduce an Uncertainty-aware Probabilistic Decoder to capture the uncertainty in object prediction with probabilistic attention. Secondly, we propose an Uncertainty-guided Query Denoising strategy to further enhance the training process. We also utilize Uncertainty-reduced Query Initialization, which leverages predicted 2D object location and depth information to reduce query uncertainty. As a result, our UA-Track achieves state-of-the-art performance on the nuScenes benchmark, i.e., 66.3% AMOTA on the test split, surpassing the previous best end-to-end solution by a significant margin of 8.9% AMOTA.
V2X-Real: a Largs-Scale Dataset for Vehicle-to-Everything Cooperative Perception
Mar 24, 2024Recent advancements in Vehicle-to-Everything (V2X) technologies have enabled autonomous vehicles to share sensing information to see through occlusions, greatly boosting the perception capability. However, there are no real-world datasets to facilitate the real V2X cooperative perception research -- existing datasets either only support Vehicle-to-Infrastructure cooperation or Vehicle-to-Vehicle cooperation. In this paper, we propose a dataset that has a mixture of multiple vehicles and smart infrastructure simultaneously to facilitate the V2X cooperative perception development with multi-modality sensing data. Our V2X-Real is collected using two connected automated vehicles and two smart infrastructures, which are all equipped with multi-modal sensors including LiDAR sensors and multi-view cameras. The whole dataset contains 33K LiDAR frames and 171K camera data with over 1.2M annotated bounding boxes of 10 categories in very challenging urban scenarios. According to the collaboration mode and ego perspective, we derive four types of datasets for Vehicle-Centric, Infrastructure-Centric, Vehicle-to-Vehicle, and Infrastructure-to-Infrastructure cooperative perception. Comprehensive multi-class multi-agent benchmarks of SOTA cooperative perception methods are provided. The V2X-Real dataset and benchmark codes will be released.
RecWizard: A Toolkit for Conversational Recommendation with Modular, Portable Models and Interactive User Interface
Feb 23, 2024
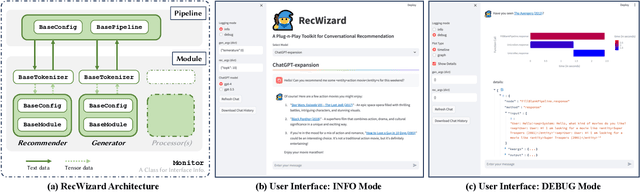


We present a new Python toolkit called RecWizard for Conversational Recommender Systems (CRS). RecWizard offers support for development of models and interactive user interface, drawing from the best practices of the Huggingface ecosystems. CRS with RecWizard are modular, portable, interactive and Large Language Models (LLMs)-friendly, to streamline the learning process and reduce the additional effort for CRS research. For more comprehensive information about RecWizard, please check our GitHub https://github.com/McAuley-Lab/RecWizard.
MegLoc: A Robust and Accurate Visual Localization Pipeline
Nov 25, 2021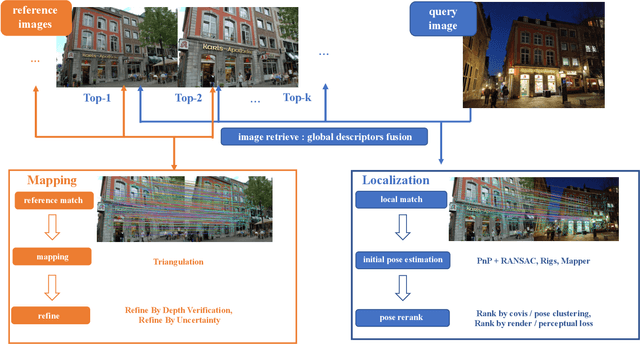
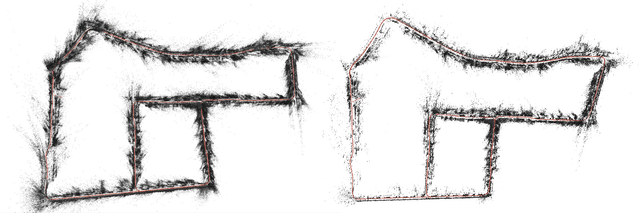
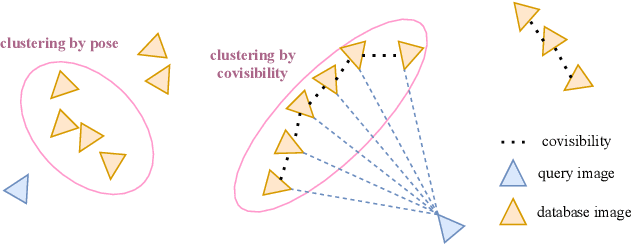

In this paper, we present a visual localization pipeline, namely MegLoc, for robust and accurate 6-DoF pose estimation under varying scenarios, including indoor and outdoor scenes, different time across a day, different seasons across a year, and even across years. MegLoc achieves state-of-the-art results on a range of challenging datasets, including winning the Outdoor and Indoor Visual Localization Challenge of ICCV 2021 Workshop on Long-term Visual Localization under Changing Conditions, as well as the Re-localization Challenge for Autonomous Driving of ICCV 2021 Workshop on Map-based Localization for Autonomous Driving.
Towards Understanding the Effectiveness of Attention Mechanism
Jun 29, 2021
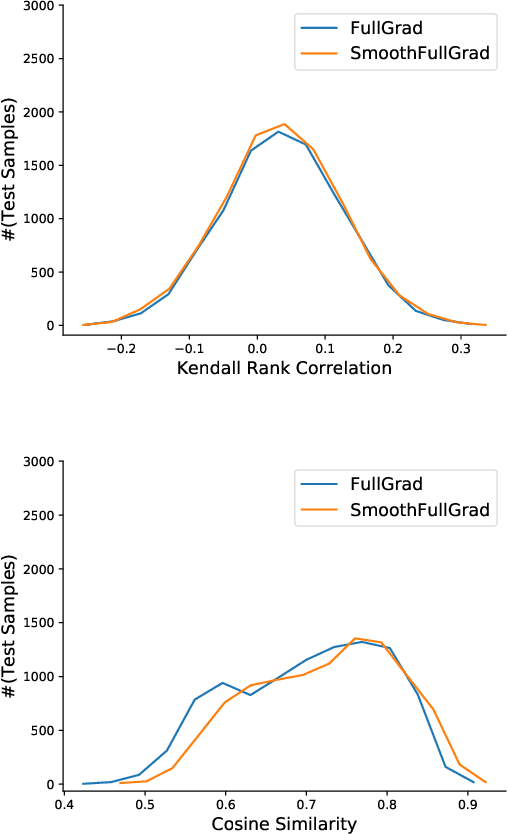

Attention Mechanism is a widely used method for improving the performance of convolutional neural networks (CNNs) on computer vision tasks. Despite its pervasiveness, we have a poor understanding of what its effectiveness stems from. It is popularly believed that its effectiveness stems from the visual attention explanation, advocating focusing on the important part of input data rather than ingesting the entire input. In this paper, we find that there is only a weak consistency between the attention weights of features and their importance. Instead, we verify the crucial role of feature map multiplication in attention mechanism and uncover a fundamental impact of feature map multiplication on the learned landscapes of CNNs: with the high order non-linearity brought by the feature map multiplication, it played a regularization role on CNNs, which made them learn smoother and more stable landscapes near real samples compared to vanilla CNNs. This smoothness and stability induce a more predictive and stable behavior in-between real samples, and make CNNs generate better. Moreover, motivated by the proposed effectiveness of feature map multiplication, we design feature map multiplication network (FMMNet) by simply replacing the feature map addition in ResNet with feature map multiplication. FMMNet outperforms ResNet on various datasets, and this indicates that feature map multiplication plays a vital role in improving the performance even without finely designed attention mechanism in existing methods.