 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantV2X: A Fully Quantized Multi-Agent System for Cooperative Perception
Sep 03, 2025Cooperative perception through Vehicle-to-Everything (V2X) communication offers significant potential for enhancing vehicle perception by mitigating occlusions and expanding the field of view. However, past research has predominantly focused on improving accuracy metrics without addressing the crucial system-level considerations of efficiency, latency, and real-world deployability. Noticeably, most existing systems rely on full-precision models, which incur high computational and transmission costs, making them impractical for real-time operation in resource-constrained environments. In this paper, we introduce \textbf{QuantV2X}, the first fully quantized multi-agent system designed specifically for efficient and scalable deployment of multi-modal, multi-agent V2X cooperative perception. QuantV2X introduces a unified end-to-end quantization strategy across both neural network models and transmitted message representations that simultaneously reduces computational load and transmission bandwidth. Remarkably, despite operating under low-bit constraints, QuantV2X achieves accuracy comparable to full-precision systems. More importantly, when evaluated under deployment-oriented metrics, QuantV2X reduces system-level latency by 3.2$\times$ and achieves a +9.5 improvement in mAP30 over full-precision baselines. Furthermore, QuantV2X scales more effectively, enabling larger and more capable models to fit within strict memory budgets. These results highlight the viability of a fully quantized multi-agent intermediate fusion system for real-world deployment. The system will be publicly released to promote research in this field: https://github.com/ucla-mobility/QuantV2X.
AgentAlign: Misalignment-Adapted Multi-Agent Perception for Resilient Inter-Agent Sensor Correlations
Dec 09, 2024Cooperative perception has attracted wide attention given its capability to leverage shared information across connected automated vehicles (CAVs) and smart infrastructures to address sensing occlusion and range limitation issues. However, existing research overlooks the fragile multi-sensor correlations in multi-agent settings, as the heterogeneous agent sensor measurements are highly susceptible to environmental factors, leading to weakened inter-agent sensor interactions. The varying operational conditions and other real-world factors inevitably introduce multifactorial noise and consequentially lead to multi-sensor misalignment, making the deployment of multi-agent multi-modality perception particularly challenging in the real world. In this paper, we propose AgentAlign, a real-world heterogeneous agent cross-modality feature alignment framework, to effectively address these multi-modality misalignment issues. Our method introduces a cross-modality feature alignment space (CFAS) and heterogeneous agent feature alignment (HAFA) mechanism to harmonize multi-modality features across various agents dynamically. Additionally, we present a novel V2XSet-noise dataset that simulates realistic sensor imperfections under diverse environmental conditions, facilitating a systematic evaluation of our approach's robustness. Extensive experiments on the V2X-Real and V2XSet-Noise benchmarks demonstrate that our framework achieves state-of-the-art performance, underscoring its potential for real-world applications in cooperative autonomous driving. The controllable V2XSet-Noise dataset and generation pipeline will be released in the future.
V2X-Real: a Largs-Scale Dataset for Vehicle-to-Everything Cooperative Perception
Mar 24, 2024Recent advancements in Vehicle-to-Everything (V2X) technologies have enabled autonomous vehicles to share sensing information to see through occlusions, greatly boosting the perception capability. However, there are no real-world datasets to facilitate the real V2X cooperative perception research -- existing datasets either only support Vehicle-to-Infrastructure cooperation or Vehicle-to-Vehicle cooperation. In this paper, we propose a dataset that has a mixture of multiple vehicles and smart infrastructure simultaneously to facilitate the V2X cooperative perception development with multi-modality sensing data. Our V2X-Real is collected using two connected automated vehicles and two smart infrastructures, which are all equipped with multi-modal sensors including LiDAR sensors and multi-view cameras. The whole dataset contains 33K LiDAR frames and 171K camera data with over 1.2M annotated bounding boxes of 10 categories in very challenging urban scenarios. According to the collaboration mode and ego perspective, we derive four types of datasets for Vehicle-Centric, Infrastructure-Centric, Vehicle-to-Vehicle, and Infrastructure-to-Infrastructure cooperative perception. Comprehensive multi-class multi-agent benchmarks of SOTA cooperative perception methods are provided. The V2X-Real dataset and benchmark codes will be released.
V2V4Real: A Real-world Large-scale Dataset for Vehicle-to-Vehicle Cooperative Perception
Mar 19, 2023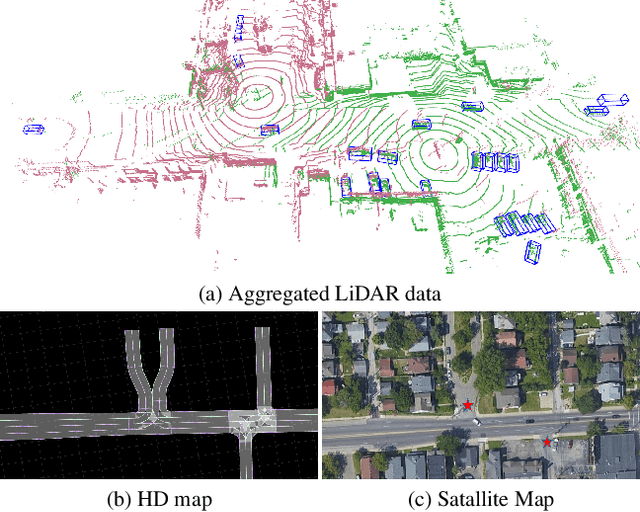



Modern perception systems of autonomous vehicles are known to be sensitive to occlusions and lack the capability of long perceiving range. It has been one of the key bottlenecks that prevents Level 5 autonomy. Recent research has demonstrated that the Vehicle-to-Vehicle (V2V) cooperative perception system has great potential to revolutionize the autonomous driving industry. However, the lack of a real-world dataset hinders the progress of this field. To facilitate the development of cooperative perception, we present V2V4Real, the first large-scale real-world multi-modal dataset for V2V perception. The data is collected by two vehicles equipped with multi-modal sensors driving together through diverse scenarios. Our V2V4Real dataset covers a driving area of 410 km, comprising 20K LiDAR frames, 40K RGB frames, 240K annotated 3D bounding boxes for 5 classes, and HDMaps that cover all the driving routes. V2V4Real introduces three perception tasks, including cooperative 3D object detection, cooperative 3D object tracking, and Sim2Real domain adaptation for cooperative perception. We provide comprehensive benchmarks of recent cooperative perception algorithms on three tasks. The V2V4Real dataset can be found at https://research.seas.ucla.edu/mobility-lab/v2v4real/.
The OpenCDA Open-source Ecosystem for Cooperative Driving Automation Research
Jan 26, 2023



Advances in Single-vehicle intelligence of automated driving have encountered significant challenges because of limited capabilities in perception and interaction with complex traffic environments. Cooperative Driving Automation~(CDA) has been considered a pivotal solution to next-generation automated driving and intelligent transportation. Though CDA has attracted much attention from both academia and industry, exploration of its potential is still in its infancy. In industry, companies tend to build their in-house data collection pipeline and research tools to tailor their needs and protect intellectual properties. Reinventing the wheels, however, wastes resources and limits the generalizability of the developed approaches since no standardized benchmarks exist. On the other hand, in academia, due to the absence of real-world traffic data and computation resources, researchers often investigate CDA topics in simplified and mostly simulated environments, restricting the possibility of scaling the research outputs to real-world scenarios. Therefore, there is an urgent need to establish an open-source ecosystem~(OSE) to address the demands of different communities for CDA research, particularly in the early exploratory research stages, and provide the bridge to ensure an integrated development and testing pipeline that diverse communities can share. In this paper, we introduce the OpenCDA research ecosystem, a unified OSE integrated with a model zoo, a suite of driving simulators at various resolutions, large-scale real-world and simulated datasets, complete development toolkits for benchmark training/testing, and a scenario database/generator. We also demonstrate the effectiveness of OpenCDA OSE through example use cases, including cooperative 3D LiDAR detection, cooperative merge, cooperative camera-based map prediction, and adversarial scenario generation.
Automated Driving Systems Data Acquisition and Processing Platform
Nov 24, 2022This paper presents an automated driving system (ADS) data acquisition and processing platform for vehicle trajectory extraction, reconstruction, and evaluation based on connected automated vehicle (CAV) cooperative perception. This platform presents a holistic pipeline from the raw advanced sensory data collection to data processing, which can process the sensor data from multiple CAVs and extract the objects' Identity (ID) number, position, speed, and orientation information in the map and Frenet coordinates. First, the ADS data acquisition and analytics platform are presented. Specifically, the experimental CAVs platform and sensor configuration are shown, and the processing software, including a deep-learning-based object detection algorithm using LiDAR information, a late fusion scheme to leverage cooperative perception to fuse the detected objects from multiple CAVs, and a multi-object tracking method is introduced. To further enhance the object detection and tracking results, high definition maps consisting of point cloud and vector maps are generated and forwarded to a world model to filter out the objects off the road and extract the objects' coordinates in Frenet coordinates and the lane information. In addition, a post-processing method is proposed to refine trajectories from the object tracking algorithms. Aiming to tackle the ID switch issue of the object tracking algorithm, a fuzzy-logic-based approach is proposed to detect the discontinuous trajectories of the same object. Finally, results, including object detection and tracking and a late fusion scheme, are presented, and the post-processing algorithm's improvements in noise level and outlier removal are discussed, confirming the functionality and effectiveness of the proposed holistic data collection and processing platform.