 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP2DNav: Panorama-to-Downview Reasoning for Zero-shot Vision-and-Language Navigation
May 19, 2026Vision-and-language navigation (VLN) requires an embodied agent to ground natural-language instructions into executable navigation actions in unseen environments. Existing zero-shot methods typically rely on additional waypoint prediction modules, which often entangle high-level directional reasoning with fine-grained local grounding, leading to error-prone and unstable decisions. In this paper, we propose P2DNav, a hierarchical framework for zero-shot vision-and-language navigation. P2DNav consists of three core components: Panorama-to-Downview (P2D), Sliding-Window Dialogue Memory (SDM), and Reflective Reorientation Mechanism (RRM). P2D explicitly decomposes navigation decision-making into two stages: panoramic direction selection and downview local grounding. It first selects the instruction-relevant direction from a 360° panorama, and then predicts a pixel-level target point from the downview RGB observation in that direction. In addition, SDM organizes navigation history as a multi-turn dialogue context and maintains recent visual observations within a sliding window to support long-horizon navigation. RRM further enables reflective reorientation by assessing the reliability of local grounding based on the downview observation and returning to panoramic direction selection when necessary. Experiments on the R2R-CE benchmark show that P2DNav achieves strong performance among zero-shot methods. In particular, compared with the state-of-the-art (SOTA) zero-shot waypoint-based and waypoint-free methods, P2DNav achieves SR gains of 146.6% and 58.9%, respectively, demonstrating the effectiveness of P2D, SDM, and RRM for zero-shot VLN. Code will be released for public use.
Adaptive Negative Scheduling for Graph Contrastive Learning
May 04, 2026Graph contrastive learning (GCL) has become a central paradigm for self-supervised representation learning in computational intelligence, with applications spanning recommendation, anomaly detection, and personalization. A key limitation of existing methods is their reliance on static negative sampling, which fails to account for the dynamic informativeness and computational cost of negatives during training. We propose AdNGCL, an adaptive negative scheduling framework with a hardness-aware scheduler (HANS) that formulates negative selection as a loss-gated, budget-constrained process across hard, intermediate, and easy strata. The scheduler dynamically adjusts step sizes based on contrastive loss trends under both global and per-category budgets, while periodically refreshing samples to maintain diversity without exceeding compute constraints. Experiments on nine benchmark graph datasets demonstrate that AdNGCL consistently advances state-of-the-art performance, achieving the best accuracy on seven datasets and second-best on the remaining two, while offering explicit control over computational cost. These results highlight the value of budget-aware, loss-sensitive scheduling as a general strategy for improving the robustness and efficiency of representation learning in emerging computational intelligence applications.
Plug-and-Play Consistency Models for MIMO Channel Estimation
Apr 26, 2026Consistency models (CMs) learn a consistent mapping from multiple noise levels to the data endpoint and can therefore perform generative inference in one or a few steps. This property makes them attractive as learned priors for low-latency inverse problems. Multiple-input multiple-output (MIMO) channel estimation under limited pilot overhead can be formulated as a high-dimensional linear inverse problem with an explicit measurement matrix, where data consistency alone is often insufficient for stable angular-domain channel recovery. This paper applies the plug-and-play consistency model (PnP-CM) framework to pilot-aided MIMO channel estimation. The PnP-CM inference procedure enforces the pilot observation model in the data-consistency update and invokes a pretrained CM denoiser in the prior update, thereby recovering the angular-domain channel vector within a small number of outer iterations. Preliminary experiments validate the feasibility of using CMs as low-latency channel-estimation priors and show that adaptive parameter scheduling and cross-scenario robustness remain important directions for further improvement.
OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
Apr 20, 2026Chain-of-Thought (CoT) reasoning has become a powerful driver of trajectory prediction in VLA-based autonomous driving, yet its autoregressive nature imposes a latency cost that is prohibitive for real-time deployment. Latent CoT methods attempt to close this gap by compressing reasoning into continuous hidden states, but consistently fall short of their explicit counterparts. We suggest that this is due to purely linguistic latent representations compressing a symbolic abstraction of the world, rather than the causal dynamics that actually govern driving. Thus, we present OneVL (One-step latent reasoning and planning with Vision-Language explanations), a unified VLA and World Model framework that routes reasoning through compact latent tokens supervised by dual auxiliary decoders. Alongside a language decoder that reconstructs text CoT, we introduce a visual world model decoder that predicts future-frame tokens, forcing the latent space to internalize the causal dynamics of road geometry, agent motion, and environmental change. A three-stage training pipeline progressively aligns these latents with trajectory, language, and visual objectives, ensuring stable joint optimization. At inference, the auxiliary decoders are discarded and all latent tokens are prefilled in a single parallel pass, matching the speed of answer-only prediction. Across four benchmarks, OneVL becomes the first latent CoT method to surpass explicit CoT, delivering state-of-the-art accuracy at answer-only latency, and providing direct evidence that tighter compression, when guided in both language and world-model supervision, produces more generalizable representations than verbose token-by-token reasoning. Project Page: https://xiaomi-embodied-intelligence.github.io/OneVL
NTIRE 2026 Challenge on Single Image Reflection Removal in the Wild: Datasets, Results, and Methods
Apr 11, 2026In this paper, we review the NTIRE 2026 challenge on single-image reflection removal (SIRR) in the Wild. SIRR is a fundamental task in image restoration. Despite progress in academic research, most methods are tested on synthetic images or limited real-world images, creating a gap in real-world applications. In this challenge, we provide participants with the OpenRR-5k dataset, which requires them to process real-world images that cover a range of reflection scenarios and intensities, with the goal of generating clean images without reflections. The challenge attracted more than 100 registrations, with 11 of them participating in the final testing phase. The top-ranked methods advanced the state-of-the-art reflection removal performance and earned unanimous recognition from the five experts in the field. The proposed OpenRR-5k dataset is available at https://huggingface.co/datasets/qiuzhangTiTi/OpenRR-5k, and the homepage of this challenge is at https://github.com/caijie0620/OpenRR-5k. Due to page limitations, this article only presents partial content; the full report and detailed analyses are available in the extended arXiv version.
ClawArena: Benchmarking AI Agents in Evolving Information Environments
Apr 05, 2026AI agents deployed as persistent assistants must maintain correct beliefs as their information environment evolves. In practice, evidence is scattered across heterogeneous sources that often contradict one another, new information can invalidate earlier conclusions, and user preferences surface through corrections rather than explicit instructions. Existing benchmarks largely assume static, single-authority settings and do not evaluate whether agents can keep up with this complexity. We introduce ClawArena, a benchmark for evaluating AI agents in evolving information environments. Each scenario maintains a complete hidden ground truth while exposing the agent only to noisy, partial, and sometimes contradictory traces across multi-channel sessions, workspace files, and staged updates. Evaluation is organized around three coupled challenges: multi-source conflict reasoning, dynamic belief revision, and implicit personalization, whose interactions yield a 14-category question taxonomy. Two question formats, multi-choice (set-selection) and shell-based executable checks, test both reasoning and workspace grounding. The current release contains 64 scenarios across 8 professional domains, totaling 1{,}879 evaluation rounds and 365 dynamic updates. Experiments on five agent frameworks and five language models show that both model capability (15.4% range) and framework design (9.2%) substantially affect performance, that self-evolving skill frameworks can partially close model-capability gaps, and that belief revision difficulty is determined by update design strategy rather than the mere presence of updates. Code is available at https://github.com/aiming-lab/ClawArena.
Token Reduction via Local and Global Contexts Optimization for Efficient Video Large Language Models
Mar 02, 2026Video Large Language Models (VLLMs) demonstrate strong video understanding but suffer from inefficiency due to redundant visual tokens. Existing pruning primary targets intra-frame spatial redundancy or prunes inside the LLM with shallow-layer overhead, yielding suboptimal spatiotemporal reduction and underutilizing long-context compressibility. All of them often discard subtle yet informative context from merged or pruned tokens. In this paper, we propose a new perspective that elaborates token \textbf{A}nchors within intra-frame and inter-frame to comprehensively aggregate the informative contexts via local-global \textbf{O}ptimal \textbf{T}ransport (\textbf{AOT}). Specifically, we first establish local- and global-aware token anchors within each frame under the attention guidance, which then optimal transport aggregates the informative contexts from pruned tokens, constructing intra-frame token anchors. Then, building on the temporal frame clips, the first frame within each clip will be considered as the keyframe anchors to ensemble similar information from consecutive frames through optimal transport, while keeping distinct tokens to represent temporal dynamics, leading to efficient token reduction in a training-free manner. Extensive evaluations show that our proposed AOT obtains competitive performances across various short- and long-video benchmarks on leading video LLMs, obtaining substantial computational efficiency while preserving temporal and visual fidelity. Project webpage: \href{https://tyroneli.github.io/AOT}{AOT}.
RADAR: Accelerating Large Language Model Inference With RL-Based Dynamic Draft Trees
Dec 16, 2025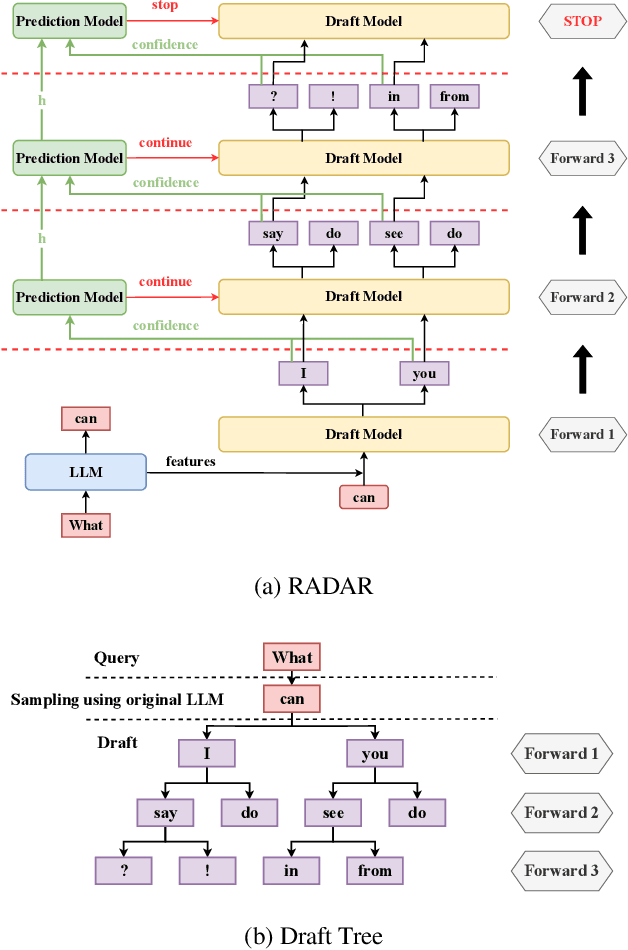
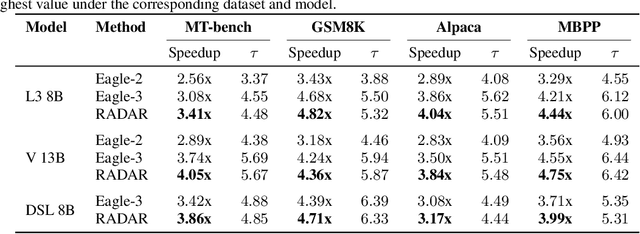
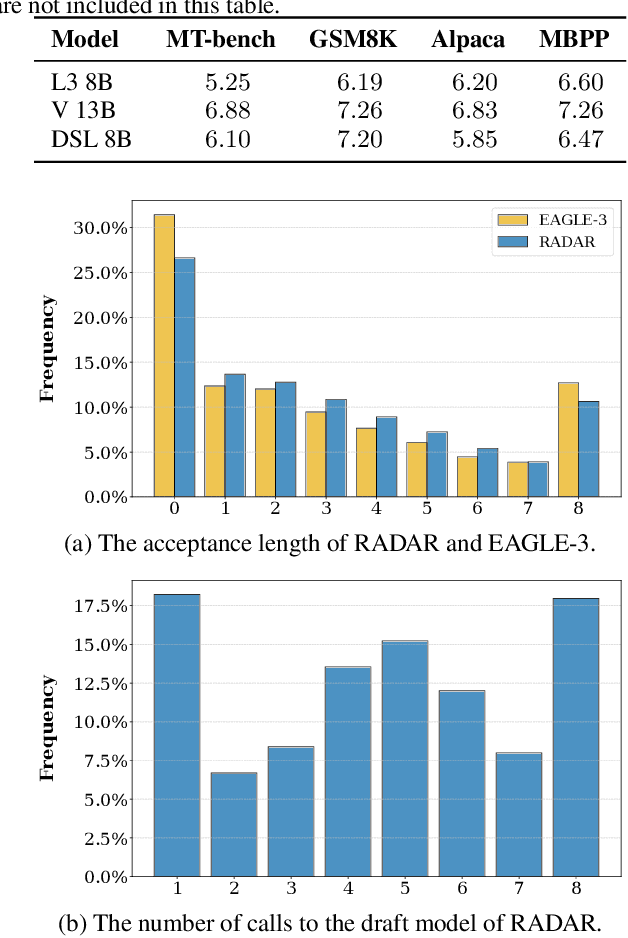
Inference with modern Large Language Models (LLMs) is expensive and slow, and speculative sampling has emerged as an effective solution to this problem, however, the number of the calls to the draft model for generating candidate tokens in speculative sampling is a preset hyperparameter, lacking flexibility. To generate and utilize the candidate tokens more effectively, we propose RADAR, a novel speculative sampling method with RL-based dynamic draft trees. RADAR formulates the draft tree generation process as a Markov Decision Process (MDP) and employs offline reinforcement learning to train a prediction model, which enables real-time decision on the calls to the draft model, reducing redundant computations and further accelerating inference. Evaluations across three LLMs and four tasks show that RADAR achieves a speedup of 3.17x-4.82x over the auto-regressive decoding baseline. The code is available at https://github.com/minaduki-sora/RADAR.
CLASH: Collaborative Large-Small Hierarchical Framework for Continuous Vision-and-Language Navigation
Dec 11, 2025Vision-and-Language Navigation (VLN) requires robots to follow natural language instructions and navigate complex environments without prior maps. While recent vision-language large models demonstrate strong reasoning abilities, they often underperform task-specific panoramic small models in VLN tasks. To address this, we propose CLASH (Collaborative Large-Small Hierarchy), a VLN-CE framework that integrates a reactive small-model planner (RSMP) with a reflective large-model reasoner (RLMR). RSMP adopts a causal-learning-based dual-branch architecture to enhance generalization, while RLMR leverages panoramic visual prompting with chain-of-thought reasoning to support interpretable spatial understanding and navigation. We further introduce an uncertainty-aware collaboration mechanism (UCM) that adaptively fuses decisions from both models. For obstacle avoidance, in simulation, we replace the rule-based controller with a fully learnable point-goal policy, and in real-world deployment, we design a LiDAR-based clustering module for generating navigable waypoints and pair it with an online SLAM-based local controller. CLASH achieves state-of-the-art (SoTA) results (ranking 1-st) on the VLN-CE leaderboard, significantly improving SR and SPL on the test-unseen set over the previous SoTA methods. Real-world experiments demonstrate CLASH's strong robustness, validating its effectiveness in both simulation and deployment scenarios.
ILRe: Intermediate Layer Retrieval for Context Compression in Causal Language Models
Aug 25, 2025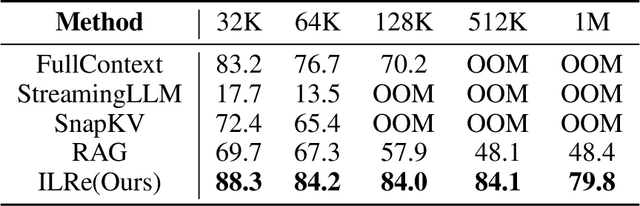
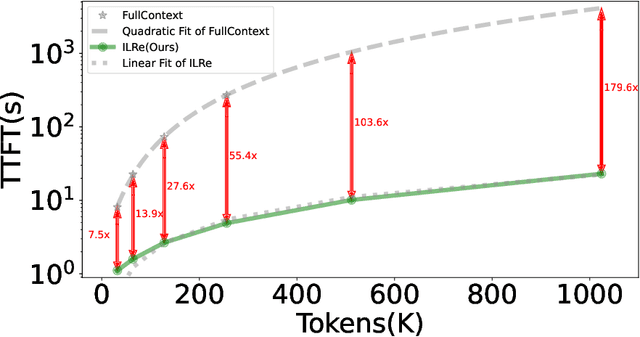
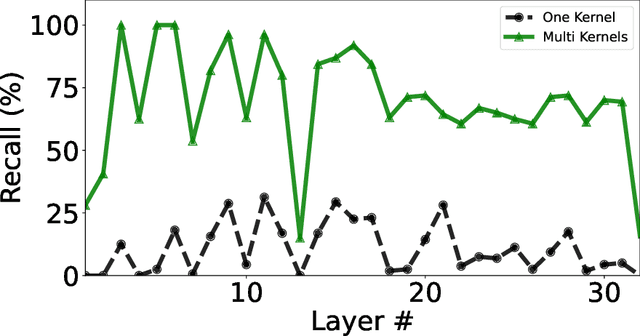
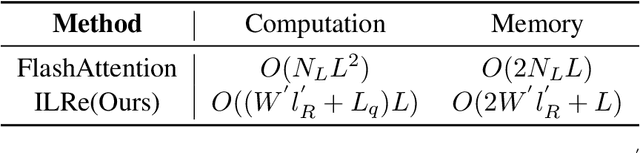
Large Language Models (LLMs) have demonstrated success across many benchmarks. However, they still exhibit limitations in long-context scenarios, primarily due to their short effective context length, quadratic computational complexity, and high memory overhead when processing lengthy inputs. To mitigate these issues, we introduce a novel context compression pipeline, called Intermediate Layer Retrieval (ILRe), which determines one intermediate decoder layer offline, encodes context by streaming chunked prefill only up to that layer, and recalls tokens by the attention scores between the input query and full key cache in that specified layer. In particular, we propose a multi-pooling kernels allocating strategy in the token recalling process to maintain the completeness of semantics. Our approach not only reduces the prefilling complexity from $O(L^2)$ to $O(L)$, but also achieves performance comparable to or better than the full context in the long context scenarios. Without additional post training or operator development, ILRe can process a single $1M$ tokens request in less than half a minute (speedup $\approx 180\times$) and scores RULER-$1M$ benchmark of $\approx 79.8$ with model Llama-3.1-UltraLong-8B-1M-Instruct on a Huawei Ascend 910B NPU.