 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenRR-1k: A Scalable Dataset for Real-World Reflection Removal
Jun 10, 2025Reflection removal technology plays a crucial role in photography and computer vision applications. However, existing techniques are hindered by the lack of high-quality in-the-wild datasets. In this paper, we propose a novel paradigm for collecting reflection datasets from a fresh perspective. Our approach is convenient, cost-effective, and scalable, while ensuring that the collected data pairs are of high quality, perfectly aligned, and represent natural and diverse scenarios. Following this paradigm, we collect a Real-world, Diverse, and Pixel-aligned dataset (named OpenRR-1k dataset), which contains 1,000 high-quality transmission-reflection image pairs collected in the wild. Through the analysis of several reflection removal methods and benchmark evaluation experiments on our dataset, we demonstrate its effectiveness in improving robustness in challenging real-world environments. Our dataset is available at https://github.com/caijie0620/OpenRR-1k.
OpenRR-5k: A Large-Scale Benchmark for Reflection Removal in the Wild
Jun 05, 2025Removing reflections is a crucial task in computer vision, with significant applications in photography and image enhancement. Nevertheless, existing methods are constrained by the absence of large-scale, high-quality, and diverse datasets. In this paper, we present a novel benchmark for Single Image Reflection Removal (SIRR). We have developed a large-scale dataset containing 5,300 high-quality, pixel-aligned image pairs, each consisting of a reflection image and its corresponding clean version. Specifically, the dataset is divided into two parts: 5,000 images are used for training, and 300 images are used for validation. Additionally, we have included 100 real-world testing images without ground truth (GT) to further evaluate the practical performance of reflection removal methods. All image pairs are precisely aligned at the pixel level to guarantee accurate supervision. The dataset encompasses a broad spectrum of real-world scenarios, featuring various lighting conditions, object types, and reflection patterns, and is segmented into training, validation, and test sets to facilitate thorough evaluation. To validate the usefulness of our dataset, we train a U-Net-based model and evaluate it using five widely-used metrics, including PSNR, SSIM, LPIPS, DISTS, and NIQE. We will release both the dataset and the code on https://github.com/caijie0620/OpenRR-5k to facilitate future research in this field.
Degradation-Aware Image Enhancement via Vision-Language Classification
Jun 05, 2025Image degradation is a prevalent issue in various real-world applications, affecting visual quality and downstream processing tasks. In this study, we propose a novel framework that employs a Vision-Language Model (VLM) to automatically classify degraded images into predefined categories. The VLM categorizes an input image into one of four degradation types: (A) super-resolution degradation (including noise, blur, and JPEG compression), (B) reflection artifacts, (C) motion blur, or (D) no visible degradation (high-quality image). Once classified, images assigned to categories A, B, or C undergo targeted restoration using dedicated models tailored for each specific degradation type. The final output is a restored image with improved visual quality. Experimental results demonstrate the effectiveness of our approach in accurately classifying image degradations and enhancing image quality through specialized restoration models. Our method presents a scalable and automated solution for real-world image enhancement tasks, leveraging the capabilities of VLMs in conjunction with state-of-the-art restoration techniques.
F2T2-HiT: A U-Shaped FFT Transformer and Hierarchical Transformer for Reflection Removal
Jun 05, 2025Single Image Reflection Removal (SIRR) technique plays a crucial role in image processing by eliminating unwanted reflections from the background. These reflections, often caused by photographs taken through glass surfaces, can significantly degrade image quality. SIRR remains a challenging problem due to the complex and varied reflections encountered in real-world scenarios. These reflections vary significantly in intensity, shapes, light sources, sizes, and coverage areas across the image, posing challenges for most existing methods to effectively handle all cases. To address these challenges, this paper introduces a U-shaped Fast Fourier Transform Transformer and Hierarchical Transformer (F2T2-HiT) architecture, an innovative Transformer-based design for SIRR. Our approach uniquely combines Fast Fourier Transform (FFT) Transformer blocks and Hierarchical Transformer blocks within a UNet framework. The FFT Transformer blocks leverage the global frequency domain information to effectively capture and separate reflection patterns, while the Hierarchical Transformer blocks utilize multi-scale feature extraction to handle reflections of varying sizes and complexities. Extensive experiments conducted on three publicly available testing datasets demonstrate state-of-the-art performance, validating the effectiveness of our approach.
Survey on Single-Image Reflection Removal using Deep Learning Techniques
Feb 12, 2025The phenomenon of reflection is quite common in digital images, posing significant challenges for various applications such as computer vision, photography, and image processing. Traditional methods for reflection removal often struggle to achieve clean results while maintaining high fidelity and robustness, particularly in real-world scenarios. Over the past few decades, numerous deep learning-based approaches for reflection removal have emerged, yielding impressive results. In this survey, we conduct a comprehensive review of the current literature by focusing on key venues such as ICCV, ECCV, CVPR, NeurIPS, etc., as these conferences and journals have been central to advances in the field. Our review follows a structured paper selection process, and we critically assess both single-stage and two-stage deep learning methods for reflection removal. The contribution of this survey is three-fold: first, we provide a comprehensive summary of the most recent work on single-image reflection removal; second, we outline task hypotheses, current deep learning techniques, publicly available datasets, and relevant evaluation metrics; and third, we identify key challenges and opportunities in deep learning-based reflection removal, highlighting the potential of this rapidly evolving research area.
VehicleGAN: Pair-flexible Pose Guided Image Synthesis for Vehicle Re-identification
Nov 27, 2023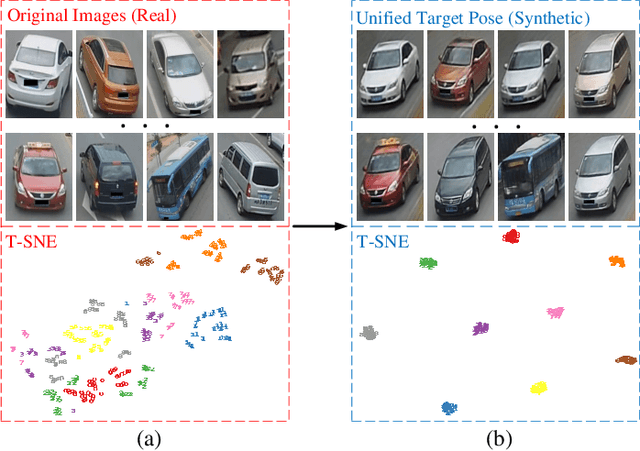
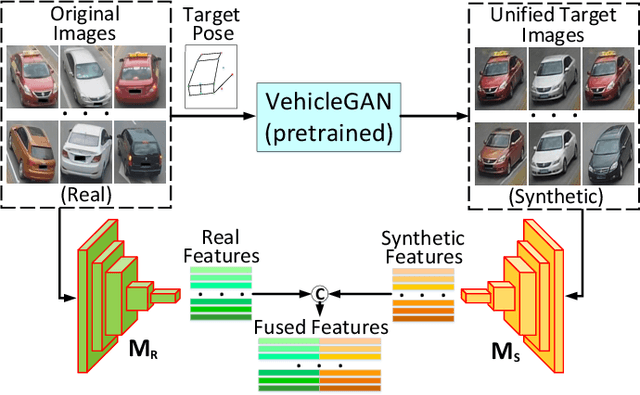
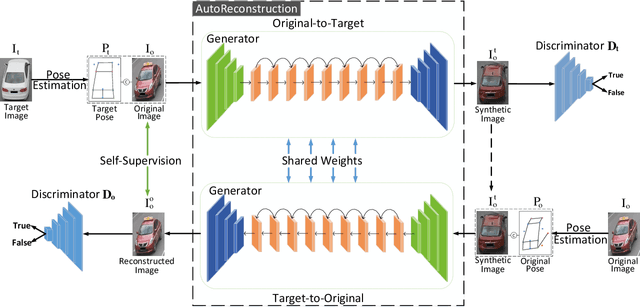
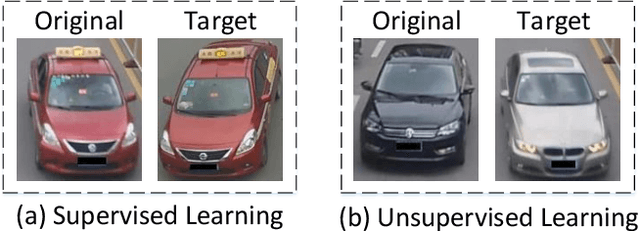
Vehicle Re-identification (Re-ID) has been broadly studied in the last decade; however, the different camera view angle leading to confused discrimination in the feature subspace for the vehicles of various poses, is still challenging for the Vehicle Re-ID models in the real world. To promote the Vehicle Re-ID models, this paper proposes to synthesize a large number of vehicle images in the target pose, whose idea is to project the vehicles of diverse poses into the unified target pose so as to enhance feature discrimination. Considering that the paired data of the same vehicles in different traffic surveillance cameras might be not available in the real world, we propose the first Pair-flexible Pose Guided Image Synthesis method for Vehicle Re-ID, named as VehicleGAN in this paper, which works for both supervised and unsupervised settings without the knowledge of geometric 3D models. Because of the feature distribution difference between real and synthetic data, simply training a traditional metric learning based Re-ID model with data-level fusion (i.e., data augmentation) is not satisfactory, therefore we propose a new Joint Metric Learning (JML) via effective feature-level fusion from both real and synthetic data. Intensive experimental results on the public VeRi-776 and VehicleID datasets prove the accuracy and effectiveness of our proposed VehicleGAN and JML.
Defense against Adversarial Cloud Attack on Remote Sensing Salient Object Detection
Jul 05, 2023Detecting the salient objects in a remote sensing image has wide applications for the interdisciplinary research. Many existing deep learning methods have been proposed for Salient Object Detection (SOD) in remote sensing images and get remarkable results. However, the recent adversarial attack examples, generated by changing a few pixel values on the original remote sensing image, could result in a collapse for the well-trained deep learning based SOD model. Different with existing methods adding perturbation to original images, we propose to jointly tune adversarial exposure and additive perturbation for attack and constrain image close to cloudy image as Adversarial Cloud. Cloud is natural and common in remote sensing images, however, camouflaging cloud based adversarial attack and defense for remote sensing images are not well studied before. Furthermore, we design DefenseNet as a learn-able pre-processing to the adversarial cloudy images so as to preserve the performance of the deep learning based remote sensing SOD model, without tuning the already deployed deep SOD model. By considering both regular and generalized adversarial examples, the proposed DefenseNet can defend the proposed Adversarial Cloud in white-box setting and other attack methods in black-box setting. Experimental results on a synthesized benchmark from the public remote sensing SOD dataset (EORSSD) show the promising defense against adversarial cloud attacks.
Semi-supervised Large-scale Fiber Detection in Material Images with Synthetic Data
Feb 10, 2023Accurate detection of large-scale, elliptical-shape fibers, including their parameters of center, orientation and major/minor axes, on the 2D cross-sectioned image slices is very important for characterizing the underlying cylinder 3D structures in microscopic material images. Detecting fibers in a degraded image poses a challenge to both current fiber detection and ellipse detection methods. This paper proposes a new semi-supervised deep learning method for large-scale elliptical fiber detection with synthetic data, which frees people from heavy data annotations and is robust to various kinds of image degradations. A domain adaptation strategy is utilized to reduce the domain distribution discrepancy between the synthetic data and the real data, and a new Region of Interest (RoI)-ellipse learning and a novel RoI ranking with the symmetry constraint are embedded in the proposed method. Experiments on real microscopic material images demonstrate the effectiveness of the proposed approach in large-scale fiber detection.
Structure-Informed Shadow Removal Networks
Jan 09, 2023



Shadow removal is a fundamental task in computer vision. Despite the success, existing deep learning-based shadow removal methods still produce images with shadow remnants. These shadow remnants typically exist in homogeneous regions with low intensity values, making them untraceable in the existing image-to-image mapping paradigm. We observe from our experiments that shadows mainly degrade object colors at the image structure level (in which humans perceive object outlines filled with continuous colors). Hence, in this paper, we propose to remove shadows at the image structure level. Based on this idea, we propose a novel structure-informed shadow removal network (StructNet) to leverage the image structure information to address the shadow remnant problem. Specifically, StructNet first reconstructs the structure information of the input image without shadows and then uses the restored shadow-free structure prior to guiding the image-level shadow removal. StructNet contains two main novel modules: (1) a mask-guided shadow-free extraction (MSFE) module to extract image structural features in a non-shadow to shadow directional manner, and (2) a multi-scale feature & residual aggregation (MFRA) module to leverage the shadow-free structure information to regularize feature consistency. In addition, we also propose to extend StructNet to exploit multi-level structure information (MStructNet), to further boost the shadow removal performance with minimum computational overheads. Extensive experiments on three shadow removal benchmarks demonstrate that our method outperforms existing shadow removal methods, and our StructNet can be integrated with existing methods to boost their performances further.
Benchmarking Shadow Removal for Facial Landmark Detection and Beyond
Nov 27, 2021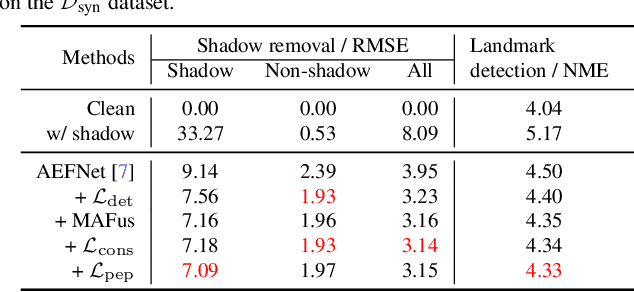
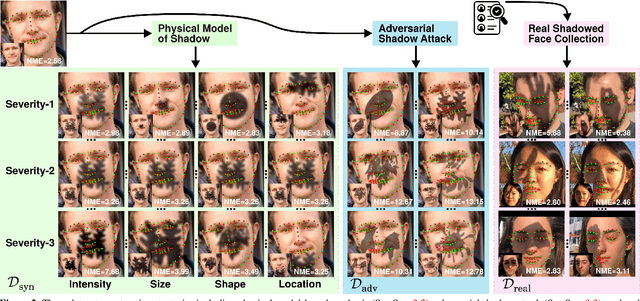
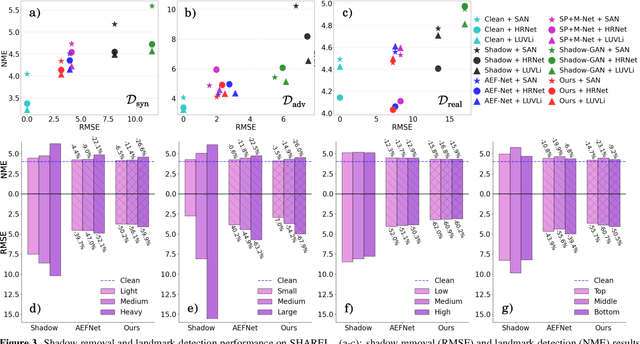
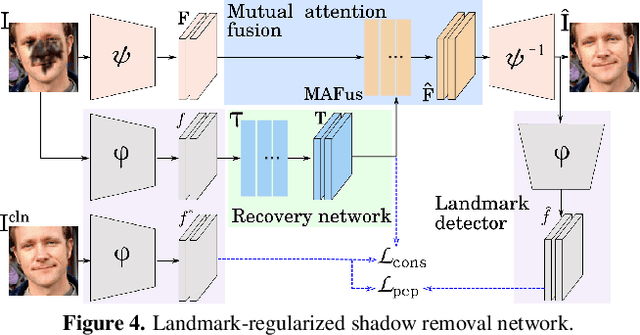
Facial landmark detection is a very fundamental and significant vision task with many important applications. In practice, facial landmark detection can be affected by a lot of natural degradations. One of the most common and important degradations is the shadow caused by light source blocking. While many advanced shadow removal methods have been proposed to recover the image quality in recent years, their effects to facial landmark detection are not well studied. For example, it remains unclear whether shadow removal could enhance the robustness of facial landmark detection to diverse shadow patterns or not. In this work, for the first attempt, we construct a novel benchmark to link two independent but related tasks (i.e., shadow removal and facial landmark detection). In particular, the proposed benchmark covers diverse face shadows with different intensities, sizes, shapes, and locations. Moreover, to mine hard shadow patterns against facial landmark detection, we propose a novel method (i.e., adversarial shadow attack), which allows us to construct a challenging subset of the benchmark for a comprehensive analysis. With the constructed benchmark, we conduct extensive analysis on three state-of-the-art shadow removal methods and three landmark detectors. The observation of this work motivates us to design a novel detection-aware shadow removal framework, which empowers shadow removal to achieve higher restoration quality and enhance the shadow robustness of deployed facial landmark detectors.