 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Multi-agent and Single-agent Perception from Cooperative Views
Apr 07, 2026The LiDAR-based multi-agent and single-agent perception has shown promising performance in environmental understanding for robots and automated vehicles. However, there is no existing method that simultaneously solves both multi-agent and single-agent perception in an unsupervised way. By sharing sensor data between multiple agents via communication, this paper discovers two key insights: 1) Improved point cloud density after the data sharing from cooperative views could benefit unsupervised object classification, 2) Cooperative view of multiple agents can be used as unsupervised guidance for the 3D object detection in the single view. Based on these two discovered insights, we propose an Unsupervised Multi-agent and Single-agent (UMS) perception framework that leverages multi-agent cooperation without human annotations to simultaneously solve multi-agent and single-agent perception. UMS combines a learning-based Proposal Purifying Filter to better classify the candidate proposals after multi-agent point cloud density cooperation, followed by a Progressive Proposal Stabilizing module to yield reliable pseudo labels by the easy-to-hard curriculum learning. Furthermore, we design a Cross-View Consensus Learning to use multi-agent cooperative view to guide detection in single-agent view. Experimental results on two public datasets V2V4Real and OPV2V show that our UMS method achieved significantly higher 3D detection performance than the state-of-the-art methods on both multi-agent and single-agent perception tasks in an unsupervised setting.
DarkDriving: A Real-World Day and Night Aligned Dataset for Autonomous Driving in the Dark Environment
Mar 18, 2026The low-light conditions are challenging to the vision-centric perception systems for autonomous driving in the dark environment. In this paper, we propose a new benchmark dataset (named DarkDriving) to investigate the low-light enhancement for autonomous driving. The existing real-world low-light enhancement benchmark datasets can be collected by controlling various exposures only in small-ranges and static scenes. The dark images of the current nighttime driving datasets do not have the precisely aligned daytime counterparts. The extreme difficulty to collect a real-world day and night aligned dataset in the dynamic driving scenes significantly limited the research in this area. With a proposed automatic day-night Trajectory Tracking based Pose Matching (TTPM) method in a large real-world closed driving test field (area: 69 acres), we collected the first real-world day and night aligned dataset for autonomous driving in the dark environment. The DarkDriving dataset has 9,538 day and night image pairs precisely aligned in location and spatial contents, whose alignment error is in just several centimeters. For each pair, we also manually label the object 2D bounding boxes. DarkDriving introduces four perception related tasks, including low-light enhancement, generalized low-light enhancement, and low-light enhancement for 2D detection and 3D detection of autonomous driving in the dark environment. The experimental results show that our DarkDriving dataset provides a comprehensive benchmark for evaluating low-light enhancement for autonomous driving and it can also be generalized to enhance dark images and promote detection in some other low-light driving environment, such as nuScenes.
CATS-V2V: A Real-World Vehicle-to-Vehicle Cooperative Perception Dataset with Complex Adverse Traffic Scenarios
Nov 14, 2025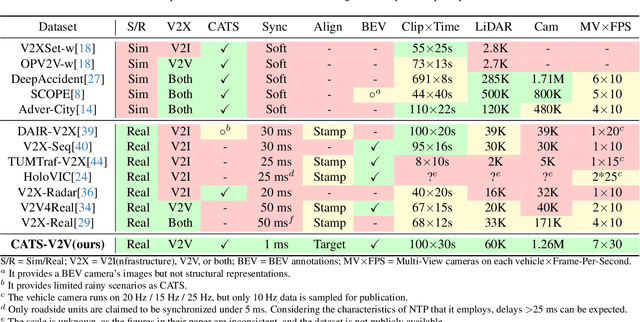


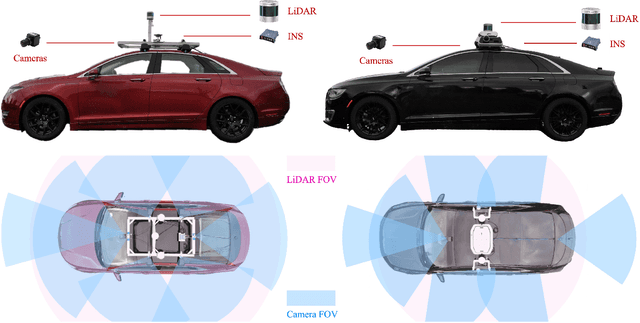
Vehicle-to-Vehicle (V2V) cooperative perception has great potential to enhance autonomous driving performance by overcoming perception limitations in complex adverse traffic scenarios (CATS). Meanwhile, data serves as the fundamental infrastructure for modern autonomous driving AI. However, due to stringent data collection requirements, existing datasets focus primarily on ordinary traffic scenarios, constraining the benefits of cooperative perception. To address this challenge, we introduce CATS-V2V, the first-of-its-kind real-world dataset for V2V cooperative perception under complex adverse traffic scenarios. The dataset was collected by two hardware time-synchronized vehicles, covering 10 weather and lighting conditions across 10 diverse locations. The 100-clip dataset includes 60K frames of 10 Hz LiDAR point clouds and 1.26M multi-view 30 Hz camera images, along with 750K anonymized yet high-precision RTK-fixed GNSS and IMU records. Correspondingly, we provide time-consistent 3D bounding box annotations for objects, as well as static scenes to construct a 4D BEV representation. On this basis, we propose a target-based temporal alignment method, ensuring that all objects are precisely aligned across all sensor modalities. We hope that CATS-V2V, the largest-scale, most supportive, and highest-quality dataset of its kind to date, will benefit the autonomous driving community in related tasks.
A Low-Rank Method for Vision Language Model Hallucination Mitigation in Autonomous Driving
Nov 09, 2025
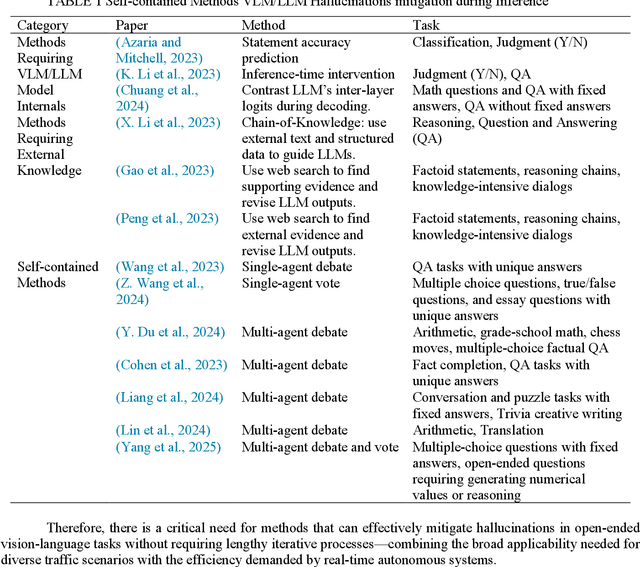
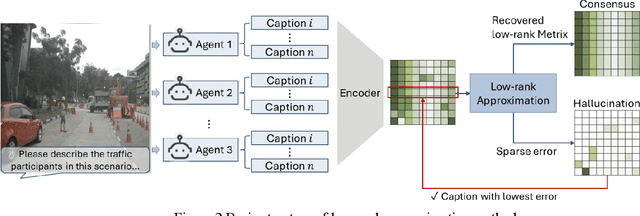

Vision Language Models (VLMs) are increasingly used in autonomous driving to help understand traffic scenes, but they sometimes produce hallucinations, which are false details not grounded in the visual input. Detecting and mitigating hallucinations is challenging when ground-truth references are unavailable and model internals are inaccessible. This paper proposes a novel self-contained low-rank approach to automatically rank multiple candidate captions generated by multiple VLMs based on their hallucination levels, using only the captions themselves without requiring external references or model access. By constructing a sentence-embedding matrix and decomposing it into a low-rank consensus component and a sparse residual, we use the residual magnitude to rank captions: selecting the one with the smallest residual as the most hallucination-free. Experiments on the NuScenes dataset demonstrate that our approach achieves 87% selection accuracy in identifying hallucination-free captions, representing a 19% improvement over the unfiltered baseline and a 6-10% improvement over multi-agent debate method. The sorting produced by sparse error magnitudes shows strong correlation with human judgments of hallucinations, validating our scoring mechanism. Additionally, our method, which can be easily parallelized, reduces inference time by 51-67% compared to debate approaches, making it practical for real-time autonomous driving applications.
Generative AI for Autonomous Driving: Frontiers and Opportunities
May 13, 2025Generative Artificial Intelligence (GenAI) constitutes a transformative technological wave that reconfigures industries through its unparalleled capabilities for content creation, reasoning, planning, and multimodal understanding. This revolutionary force offers the most promising path yet toward solving one of engineering's grandest challenges: achieving reliable, fully autonomous driving, particularly the pursuit of Level 5 autonomy. This survey delivers a comprehensive and critical synthesis of the emerging role of GenAI across the autonomous driving stack. We begin by distilling the principles and trade-offs of modern generative modeling, encompassing VAEs, GANs, Diffusion Models, and Large Language Models (LLMs). We then map their frontier applications in image, LiDAR, trajectory, occupancy, video generation as well as LLM-guided reasoning and decision making. We categorize practical applications, such as synthetic data workflows, end-to-end driving strategies, high-fidelity digital twin systems, smart transportation networks, and cross-domain transfer to embodied AI. We identify key obstacles and possibilities such as comprehensive generalization across rare cases, evaluation and safety checks, budget-limited implementation, regulatory compliance, ethical concerns, and environmental effects, while proposing research plans across theoretical assurances, trust metrics, transport integration, and socio-technical influence. By unifying these threads, the survey provides a forward-looking reference for researchers, engineers, and policymakers navigating the convergence of generative AI and advanced autonomous mobility. An actively maintained repository of cited works is available at https://github.com/taco-group/GenAI4AD.
Visibility-Uncertainty-guided 3D Gaussian Inpainting via Scene Conceptional Learning
Apr 23, 20253D Gaussian Splatting (3DGS) has emerged as a powerful and efficient 3D representation for novel view synthesis. This paper extends 3DGS capabilities to inpainting, where masked objects in a scene are replaced with new contents that blend seamlessly with the surroundings. Unlike 2D image inpainting, 3D Gaussian inpainting (3DGI) is challenging in effectively leveraging complementary visual and semantic cues from multiple input views, as occluded areas in one view may be visible in others. To address this, we propose a method that measures the visibility uncertainties of 3D points across different input views and uses them to guide 3DGI in utilizing complementary visual cues. We also employ uncertainties to learn a semantic concept of scene without the masked object and use a diffusion model to fill masked objects in input images based on the learned concept. Finally, we build a novel 3DGI framework, VISTA, by integrating VISibility-uncerTainty-guided 3DGI with scene conceptuAl learning. VISTA generates high-quality 3DGS models capable of synthesizing artifact-free and naturally inpainted novel views. Furthermore, our approach extends to handling dynamic distractors arising from temporal object changes, enhancing its versatility in diverse scene reconstruction scenarios. We demonstrate the superior performance of our method over state-of-the-art techniques using two challenging datasets: the SPIn-NeRF dataset, featuring 10 diverse static 3D inpainting scenes, and an underwater 3D inpainting dataset derived from UTB180, including fast-moving fish as inpainting targets.
V2X-DG: Domain Generalization for Vehicle-to-Everything Cooperative Perception
Mar 19, 2025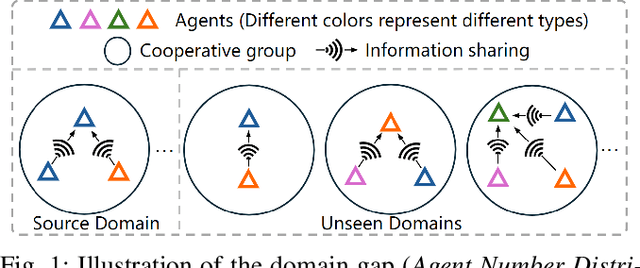
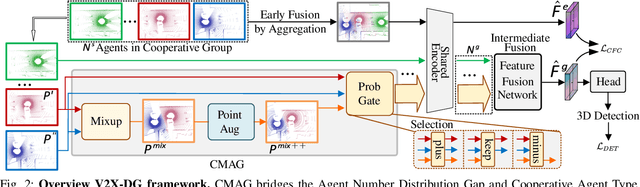
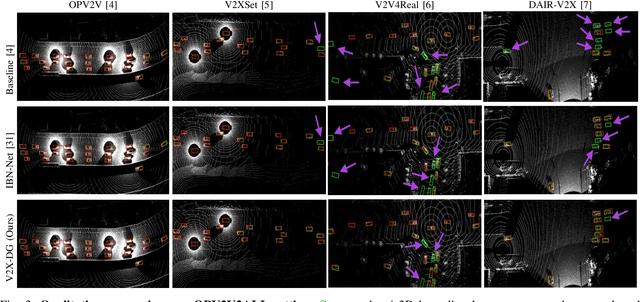

LiDAR-based Vehicle-to-Everything (V2X) cooperative perception has demonstrated its impact on the safety and effectiveness of autonomous driving. Since current cooperative perception algorithms are trained and tested on the same dataset, the generalization ability of cooperative perception systems remains underexplored. This paper is the first work to study the Domain Generalization problem of LiDAR-based V2X cooperative perception (V2X-DG) for 3D detection based on four widely-used open source datasets: OPV2V, V2XSet, V2V4Real and DAIR-V2X. Our research seeks to sustain high performance not only within the source domain but also across other unseen domains, achieved solely through training on source domain. To this end, we propose Cooperative Mixup Augmentation based Generalization (CMAG) to improve the model generalization capability by simulating the unseen cooperation, which is designed compactly for the domain gaps in cooperative perception. Furthermore, we propose a constraint for the regularization of the robust generalized feature representation learning: Cooperation Feature Consistency (CFC), which aligns the intermediately fused features of the generalized cooperation by CMAG and the early fused features of the original cooperation in source domain. Extensive experiments demonstrate that our approach achieves significant performance gains when generalizing to other unseen datasets while it also maintains strong performance on the source dataset.
Stealthy Multi-Task Adversarial Attacks
Nov 26, 2024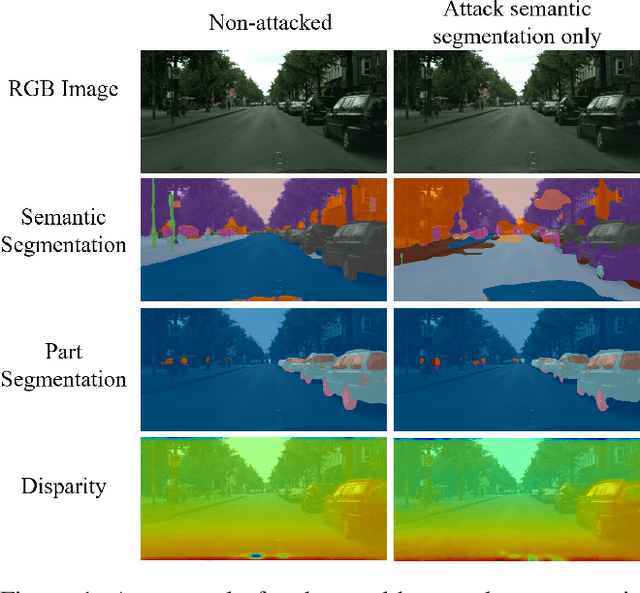
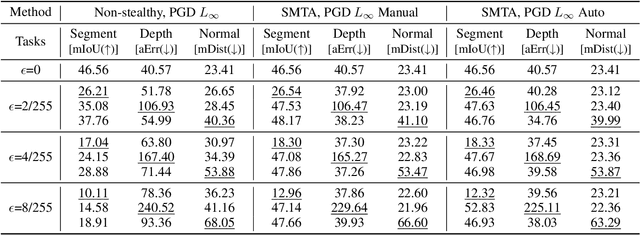
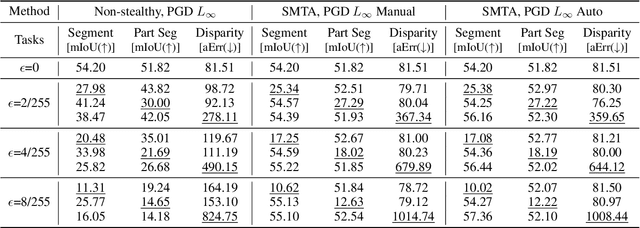
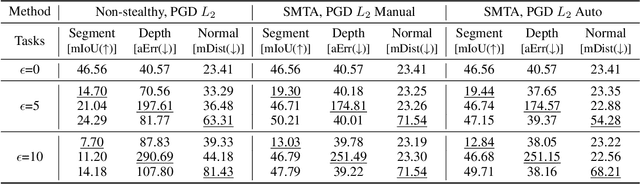
Deep Neural Networks exhibit inherent vulnerabilities to adversarial attacks, which can significantly compromise their outputs and reliability. While existing research primarily focuses on attacking single-task scenarios or indiscriminately targeting all tasks in multi-task environments, we investigate selectively targeting one task while preserving performance in others within a multi-task framework. This approach is motivated by varying security priorities among tasks in real-world applications, such as autonomous driving, where misinterpreting critical objects (e.g., signs, traffic lights) poses a greater security risk than minor depth miscalculations. Consequently, attackers may hope to target security-sensitive tasks while avoiding non-critical tasks from being compromised, thus evading being detected before compromising crucial functions. In this paper, we propose a method for the stealthy multi-task attack framework that utilizes multiple algorithms to inject imperceptible noise into the input. This novel method demonstrates remarkable efficacy in compromising the target task while simultaneously maintaining or even enhancing performance across non-targeted tasks - a criterion hitherto unexplored in the field. Additionally, we introduce an automated approach for searching the weighting factors in the loss function, further enhancing attack efficiency. Experimental results validate our framework's ability to successfully attack the target task while preserving the performance of non-targeted tasks. The automated loss function weight searching method demonstrates comparable efficacy to manual tuning, establishing a state-of-the-art multi-task attack framework.
CoMamba: Real-time Cooperative Perception Unlocked with State Space Models
Sep 16, 2024



Cooperative perception systems play a vital role in enhancing the safety and efficiency of vehicular autonomy. Although recent studies have highlighted the efficacy of vehicle-to-everything (V2X) communication techniques in autonomous driving, a significant challenge persists: how to efficiently integrate multiple high-bandwidth features across an expanding network of connected agents such as vehicles and infrastructure. In this paper, we introduce CoMamba, a novel cooperative 3D detection framework designed to leverage state-space models for real-time onboard vehicle perception. Compared to prior state-of-the-art transformer-based models, CoMamba enjoys being a more scalable 3D model using bidirectional state space models, bypassing the quadratic complexity pain-point of attention mechanisms. Through extensive experimentation on V2X/V2V datasets, CoMamba achieves superior performance compared to existing methods while maintaining real-time processing capabilities. The proposed framework not only enhances object detection accuracy but also significantly reduces processing time, making it a promising solution for next-generation cooperative perception systems in intelligent transportation networks.
Light the Night: A Multi-Condition Diffusion Framework for Unpaired Low-Light Enhancement in Autonomous Driving
Apr 07, 2024Vision-centric perception systems for autonomous driving have gained considerable attention recently due to their cost-effectiveness and scalability, especially compared to LiDAR-based systems. However, these systems often struggle in low-light conditions, potentially compromising their performance and safety. To address this, our paper introduces LightDiff, a domain-tailored framework designed to enhance the low-light image quality for autonomous driving applications. Specifically, we employ a multi-condition controlled diffusion model. LightDiff works without any human-collected paired data, leveraging a dynamic data degradation process instead. It incorporates a novel multi-condition adapter that adaptively controls the input weights from different modalities, including depth maps, RGB images, and text captions, to effectively illuminate dark scenes while maintaining context consistency. Furthermore, to align the enhanced images with the detection model's knowledge, LightDiff employs perception-specific scores as rewards to guide the diffusion training process through reinforcement learning. Extensive experiments on the nuScenes datasets demonstrate that LightDiff can significantly improve the performance of several state-of-the-art 3D detectors in night-time conditions while achieving high visual quality scores, highlighting its potential to safeguard autonomous driving.