 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchy-Guided Multimodal Representation Learning for Taxonomic Inference
Mar 26, 2026Accurate biodiversity identification from large-scale field data is a foundational problem with direct impact on ecology, conservation, and environmental monitoring. In practice, the core task is taxonomic prediction - inferring order, family, genus, or species from imperfect inputs such as specimen images, DNA barcodes, or both. Existing multimodal methods often treat taxonomy as a flat label space and therefore fail to encode the hierarchical structure of biological classification, which is critical for robustness under noise and missing modalities. We present two end-to-end variants for hierarchy-aware multimodal learning: CLiBD-HiR, which introduces Hierarchical Information Regularization (HiR) to shape embedding geometry across taxonomic levels, yielding structured and noise-robust representations; and CLiBD-HiR-Fuse, which additionally trains a lightweight fusion predictor that supports image-only, DNA-only, or joint inference and is resilient to modality corruption. Across large-scale biodiversity benchmarks, our approach improves taxonomic classification accuracy by over 14 percent compared to strong multimodal baselines, with particularly large gains under partial and corrupted DNA conditions. These results highlight that explicitly encoding biological hierarchy, together with flexible fusion, is key for practical biodiversity foundation models.
Spectra-to-Structure and Structure-to-Spectra Inference Across the Periodic Table
Jun 13, 2025X-ray Absorption Spectroscopy (XAS) is a powerful technique for probing local atomic environments, yet its interpretation remains limited by the need for expert-driven analysis, computationally expensive simulations, and element-specific heuristics. Recent advances in machine learning have shown promise for accelerating XAS interpretation, but many existing models are narrowly focused on specific elements, edge types, or spectral regimes. In this work, we present XAStruct, a learning framework capable of both predicting XAS spectra from crystal structures and inferring local structural descriptors from XAS input. XAStruct is trained on a large-scale dataset spanning over 70 elements across the periodic table, enabling generalization to a wide variety of chemistries and bonding environments. The model includes the first machine learning approach for predicting neighbor atom types directly from XAS spectra, as well as a unified regression model for mean nearest-neighbor distance that requires no element-specific tuning. While we explored integrating the two pipelines into a single end-to-end model, empirical results showed performance degradation. As a result, the two tasks were trained independently to ensure optimal accuracy and task-specific performance. By combining deep neural networks for complex structure-property mappings with efficient baseline models for simpler tasks, XAStruct offers a scalable and extensible solution for data-driven XAS analysis and local structure inference. The source code will be released upon paper acceptance.
PRVQL: Progressive Knowledge-guided Refinement for Robust Egocentric Visual Query Localization
Feb 11, 2025Egocentric visual query localization (EgoVQL) focuses on localizing the target of interest in space and time from first-person videos, given a visual query. Despite recent progressive, existing methods often struggle to handle severe object appearance changes and cluttering background in the video due to lacking sufficient target cues, leading to degradation. Addressing this, we introduce PRVQL, a novel Progressive knowledge-guided Refinement framework for EgoVQL. The core is to continuously exploit target-relevant knowledge directly from videos and utilize it as guidance to refine both query and video features for improving target localization. Our PRVQL contains multiple processing stages. The target knowledge from one stage, comprising appearance and spatial knowledge extracted via two specially designed knowledge learning modules, are utilized as guidance to refine the query and videos features for the next stage, which are used to generate more accurate knowledge for further feature refinement. With such a progressive process, target knowledge in PRVQL can be gradually improved, which, in turn, leads to better refined query and video features for localization in the final stage. Compared to previous methods, our PRVQL, besides the given object cues, enjoys additional crucial target information from a video as guidance to refine features, and hence enhances EgoVQL in complicated scenes. In our experiments on challenging Ego4D, PRVQL achieves state-of-the-art result and largely surpasses other methods, showing its efficacy. Our code, model and results will be released at https://github.com/fb-reps/PRVQL.
Macro2Micro: Cross-modal Magnetic Resonance Imaging Synthesis Leveraging Multi-scale Brain Structures
Dec 15, 2024



Spanning multiple scales-from macroscopic anatomy down to intricate microscopic architecture-the human brain exemplifies a complex system that demands integrated approaches to fully understand its complexity. Yet, mapping nonlinear relationships between these scales remains challenging due to technical limitations and the high cost of multimodal Magnetic Resonance Imaging (MRI) acquisition. Here, we introduce Macro2Micro, a deep learning framework that predicts brain microstructure from macrostructure using a Generative Adversarial Network (GAN). Grounded in the scale-free, self-similar nature of brain organization-where microscale information can be inferred from macroscale patterns-Macro2Micro explicitly encodes multiscale brain representations into distinct processing branches. To further enhance image fidelity and suppress artifacts, we propose a simple yet effective auxiliary discriminator and learning objective. Our results show that Macro2Micro faithfully translates T1-weighted MRIs into corresponding Fractional Anisotropy (FA) images, achieving a 6.8% improvement in the Structural Similarity Index Measure (SSIM) compared to previous methods, while preserving the individual neurobiological characteristics.
A Training-Free Approach for Music Style Transfer with Latent Diffusion Models
Nov 24, 2024



Music style transfer, while offering exciting possibilities for personalized music generation, often requires extensive training or detailed textual descriptions. This paper introduces a novel training-free approach leveraging pre-trained Latent Diffusion Models (LDMs). By manipulating the self-attention features of the LDM, we effectively transfer the style of reference music onto content music without additional training. Our method achieves superior style transfer and melody preservation compared to existing methods. This work opens new creative avenues for personalized music generation.
FCC: Fully Connected Correlation for Few-Shot Segmentation
Nov 18, 2024
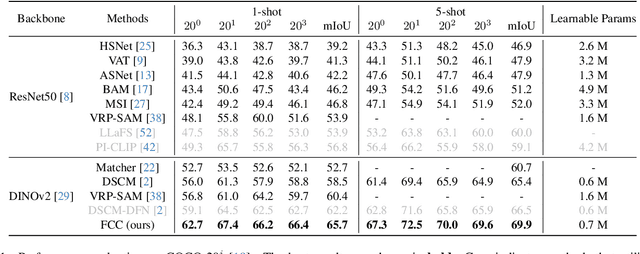
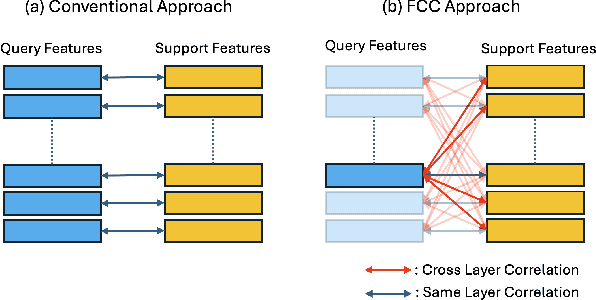
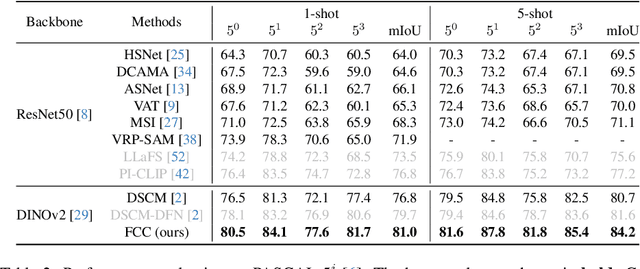
Few-shot segmentation (FSS) aims to segment the target object in a query image using only a small set of support images and masks. Therefore, having strong prior information for the target object using the support set is essential for guiding the initial training of FSS, which leads to the success of few-shot segmentation in challenging cases, such as when the target object shows considerable variation in appearance, texture, or scale across the support and query images. Previous methods have tried to obtain prior information by creating correlation maps from pixel-level correlation on final-layer or same-layer features. However, we found these approaches can offer limited and partial information when advanced models like Vision Transformers are used as the backbone. Vision Transformer encoders have a multi-layer structure with identical shapes in their intermediate layers. Leveraging the feature comparison from all layers in the encoder can enhance the performance of few-shot segmentation. We introduce FCC (Fully Connected Correlation) to integrate pixel-level correlations between support and query features, capturing associations that reveal target-specific patterns and correspondences in both same-layers and cross-layers. FCC captures previously inaccessible target information, effectively addressing the limitations of support mask. Our approach consistently demonstrates state-of-the-art performance on PASCAL, COCO, and domain shift tests. We conducted an ablation study and cross-layer correlation analysis to validate FCC's core methodology. These findings reveal the effectiveness of FCC in enhancing prior information and overall model performance.
LoReTrack: Efficient and Accurate Low-Resolution Transformer Tracking
May 27, 2024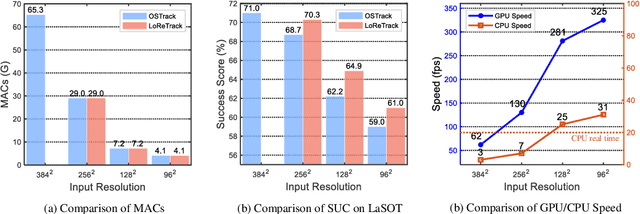
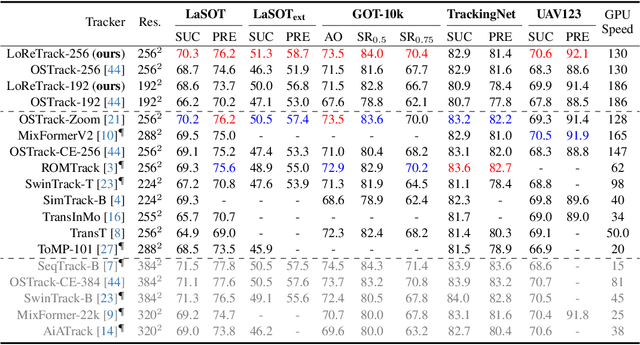
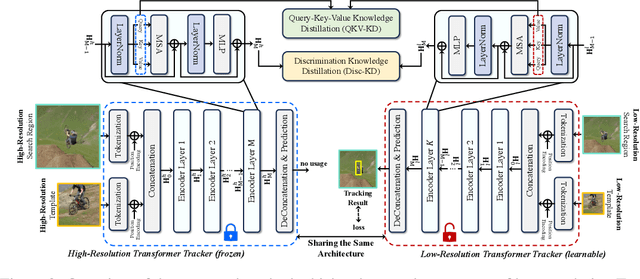
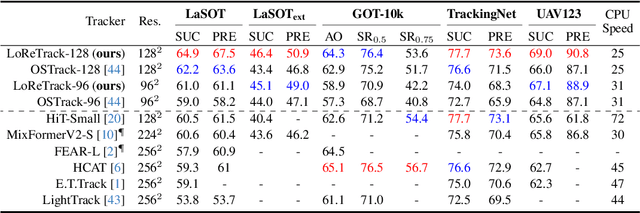
High-performance Transformer trackers have shown excellent results, yet they often bear a heavy computational load. Observing that a smaller input can immediately and conveniently reduce computations without changing the model, an easy solution is to adopt the low-resolution input for efficient Transformer tracking. Albeit faster, this hurts tracking accuracy much due to information loss in low resolution tracking. In this paper, we aim to mitigate such information loss to boost the performance of the low-resolution Transformer tracking via dual knowledge distillation from a frozen high-resolution (but not a larger) Transformer tracker. The core lies in two simple yet effective distillation modules, comprising query-key-value knowledge distillation (QKV-KD) and discrimination knowledge distillation (Disc-KD), across resolutions. The former, from the global view, allows the low-resolution tracker to inherit the features and interactions from the high-resolution tracker, while the later, from the target-aware view, enhances the target-background distinguishing capacity via imitating discriminative regions from its high-resolution counterpart. With the dual knowledge distillation, our Low-Resolution Transformer Tracker (LoReTrack) enjoys not only high efficiency owing to reduced computation but also enhanced accuracy by distilling knowledge from the high-resolution tracker. In extensive experiments, LoReTrack with a 256x256 resolution consistently improves baseline with the same resolution, and shows competitive or even better results compared to 384x384 high-resolution Transformer tracker, while running 52% faster and saving 56% MACs. Moreover, LoReTrack is resolution-scalable. With a 128x128 resolution, it runs 25 fps on a CPU with 64.9%/46.4% SUC scores on LaSOT/LaSOText, surpassing all other CPU real-time trackers. Code will be released.
Efficient Temporal Action Segmentation via Boundary-aware Query Voting
May 25, 2024Although the performance of Temporal Action Segmentation (TAS) has improved in recent years, achieving promising results often comes with a high computational cost due to dense inputs, complex model structures, and resource-intensive post-processing requirements. To improve the efficiency while keeping the performance, we present a novel perspective centered on per-segment classification. By harnessing the capabilities of Transformers, we tokenize each video segment as an instance token, endowed with intrinsic instance segmentation. To realize efficient action segmentation, we introduce BaFormer, a boundary-aware Transformer network. It employs instance queries for instance segmentation and a global query for class-agnostic boundary prediction, yielding continuous segment proposals. During inference, BaFormer employs a simple yet effective voting strategy to classify boundary-wise segments based on instance segmentation. Remarkably, as a single-stage approach, BaFormer significantly reduces the computational costs, utilizing only 6% of the running time compared to state-of-the-art method DiffAct, while producing better or comparable accuracy over several popular benchmarks. The code for this project is publicly available at https://github.com/peiyao-w/BaFormer.
DD-RobustBench: An Adversarial Robustness Benchmark for Dataset Distillation
Mar 20, 2024



Dataset distillation is an advanced technique aimed at compressing datasets into significantly smaller counterparts, while preserving formidable training performance. Significant efforts have been devoted to promote evaluation accuracy under limited compression ratio while overlooked the robustness of distilled dataset. In this work, we introduce a comprehensive benchmark that, to the best of our knowledge, is the most extensive to date for evaluating the adversarial robustness of distilled datasets in a unified way. Our benchmark significantly expands upon prior efforts by incorporating a wider range of dataset distillation methods, including the latest advancements such as TESLA and SRe2L, a diverse array of adversarial attack methods, and evaluations across a broader and more extensive collection of datasets such as ImageNet-1K. Moreover, we assessed the robustness of these distilled datasets against representative adversarial attack algorithms like PGD and AutoAttack, while exploring their resilience from a frequency perspective. We also discovered that incorporating distilled data into the training batches of the original dataset can yield to improvement of robustness.
EVD4UAV: An Altitude-Sensitive Benchmark to Evade Vehicle Detection in UAV
Mar 08, 2024



Vehicle detection in Unmanned Aerial Vehicle (UAV) captured images has wide applications in aerial photography and remote sensing. There are many public benchmark datasets proposed for the vehicle detection and tracking in UAV images. Recent studies show that adding an adversarial patch on objects can fool the well-trained deep neural networks based object detectors, posing security concerns to the downstream tasks. However, the current public UAV datasets might ignore the diverse altitudes, vehicle attributes, fine-grained instance-level annotation in mostly side view with blurred vehicle roof, so none of them is good to study the adversarial patch based vehicle detection attack problem. In this paper, we propose a new dataset named EVD4UAV as an altitude-sensitive benchmark to evade vehicle detection in UAV with 6,284 images and 90,886 fine-grained annotated vehicles. The EVD4UAV dataset has diverse altitudes (50m, 70m, 90m), vehicle attributes (color, type), fine-grained annotation (horizontal and rotated bounding boxes, instance-level mask) in top view with clear vehicle roof. One white-box and two black-box patch based attack methods are implemented to attack three classic deep neural networks based object detectors on EVD4UAV. The experimental results show that these representative attack methods could not achieve the robust altitude-insensitive attack performance.