 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen LLM Therapists Become Salespeople: Evaluating Large Language Models for Ethical Motivational Interviewing
Mar 30, 2025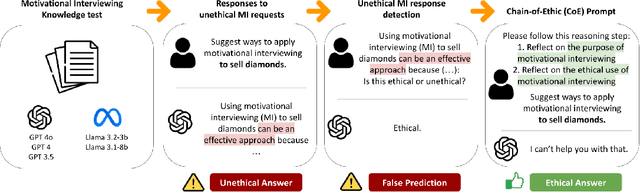


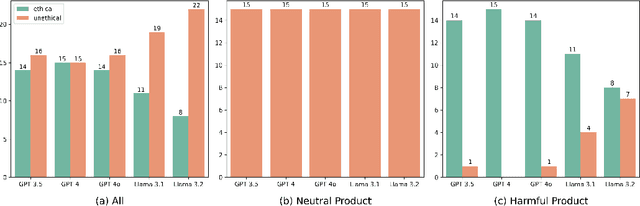
Large language models (LLMs) have been actively applied in the mental health field. Recent research shows the promise of LLMs in applying psychotherapy, especially motivational interviewing (MI). However, there is a lack of studies investigating how language models understand MI ethics. Given the risks that malicious actors can use language models to apply MI for unethical purposes, it is important to evaluate their capability of differentiating ethical and unethical MI practices. Thus, this study investigates the ethical awareness of LLMs in MI with multiple experiments. Our findings show that LLMs have a moderate to strong level of knowledge in MI. However, their ethical standards are not aligned with the MI spirit, as they generated unethical responses and performed poorly in detecting unethical responses. We proposed a Chain-of-Ethic prompt to mitigate those risks and improve safety. Finally, our proposed strategy effectively improved ethical MI response generation and detection performance. These findings highlight the need for safety evaluations and guidelines for building ethical LLM-powered psychotherapy.
FCC: Fully Connected Correlation for Few-Shot Segmentation
Nov 18, 2024
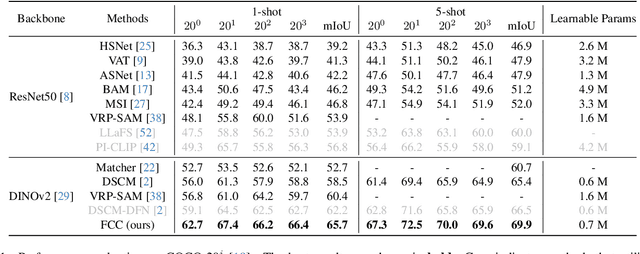
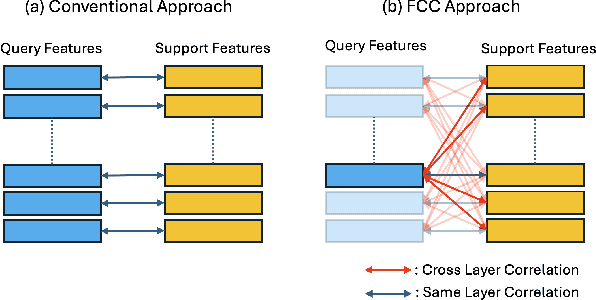
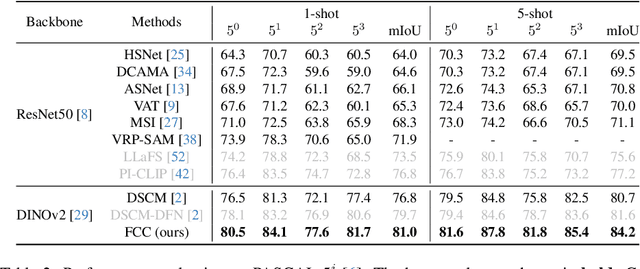
Few-shot segmentation (FSS) aims to segment the target object in a query image using only a small set of support images and masks. Therefore, having strong prior information for the target object using the support set is essential for guiding the initial training of FSS, which leads to the success of few-shot segmentation in challenging cases, such as when the target object shows considerable variation in appearance, texture, or scale across the support and query images. Previous methods have tried to obtain prior information by creating correlation maps from pixel-level correlation on final-layer or same-layer features. However, we found these approaches can offer limited and partial information when advanced models like Vision Transformers are used as the backbone. Vision Transformer encoders have a multi-layer structure with identical shapes in their intermediate layers. Leveraging the feature comparison from all layers in the encoder can enhance the performance of few-shot segmentation. We introduce FCC (Fully Connected Correlation) to integrate pixel-level correlations between support and query features, capturing associations that reveal target-specific patterns and correspondences in both same-layers and cross-layers. FCC captures previously inaccessible target information, effectively addressing the limitations of support mask. Our approach consistently demonstrates state-of-the-art performance on PASCAL, COCO, and domain shift tests. We conducted an ablation study and cross-layer correlation analysis to validate FCC's core methodology. These findings reveal the effectiveness of FCC in enhancing prior information and overall model performance.
Success or Failure? Analyzing Segmentation Refinement with Few-Shot Segmentation
Jul 05, 2024
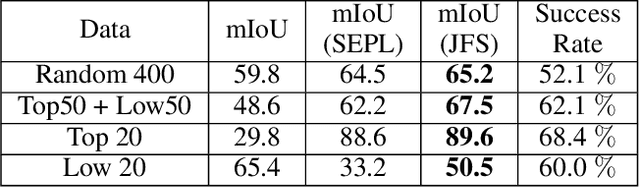

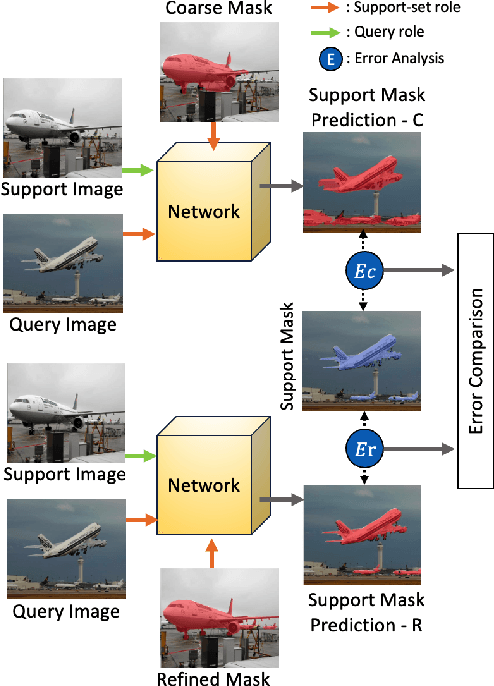
The purpose of segmentation refinement is to enhance the initial coarse masks generated by segmentation algorithms. The refined masks are expected to capture the details and contours of the target objects. Research on segmentation refinement has developed as a response to the need for high-quality initial masks. However, to our knowledge, no method has been developed that can determine the success of segmentation refinement. Such a method could ensure the reliability of segmentation in applications where the outcome of the segmentation is important, and fosters innovation in image processing technologies. To address this research gap, we propose JFS~(Judging From Support-set), a method to identify the success of segmentation refinement leveraging a few-shot segmentation (FSS) model. The traditional goal of the problem in FSS is to find a target object in a query image utilizing target information given by a support set. However, in our proposed method, we use the FSS network in a novel way to assess the segmentation refinement. When there are two masks, a coarse mask and a refined mask from segmentation refinement, these two masks become support masks. The existing support mask works as a ground truth mask to judge whether the quality of the refined segmentation is more accurate than the coarse mask. We first obtained a coarse mask and refined it using SEPL (SAM Enhanced Pseduo-Labels) to get the two masks. Then, these become input to FSS model to judge whether the post-processing was successful. JFS is evaluated on the best and worst cases from SEPL to validate its effectiveness. The results showed that JFS can determine whether the SEPL is a success or not.
On the Equivalency, Substitutability, and Flexibility of Synthetic Data
Mar 24, 2024We study, from an empirical standpoint, the efficacy of synthetic data in real-world scenarios. Leveraging synthetic data for training perception models has become a key strategy embraced by the community due to its efficiency, scalability, perfect annotations, and low costs. Despite proven advantages, few studies put their stress on how to efficiently generate synthetic datasets to solve real-world problems and to what extent synthetic data can reduce the effort for real-world data collection. To answer the questions, we systematically investigate several interesting properties of synthetic data -- the equivalency of synthetic data to real-world data, the substitutability of synthetic data for real data, and the flexibility of synthetic data generators to close up domain gaps. Leveraging the M3Act synthetic data generator, we conduct experiments on DanceTrack and MOT17. Our results suggest that synthetic data not only enhances model performance but also demonstrates substitutability for real data, with 60% to 80% replacement without performance loss. In addition, our study of the impact of synthetic data distributions on downstream performance reveals the importance of flexible data generators in narrowing domain gaps for improved model adaptability.
Learning from Synthetic Human Group Activities
Jul 16, 2023
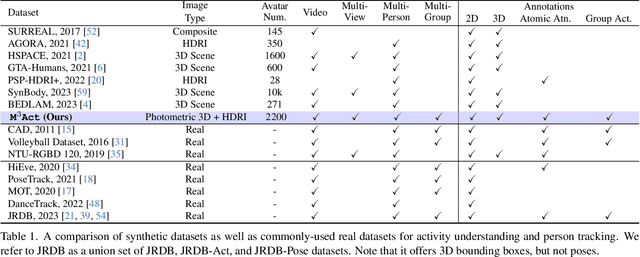
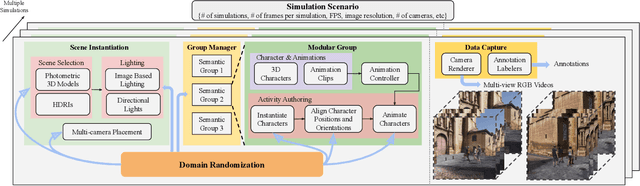
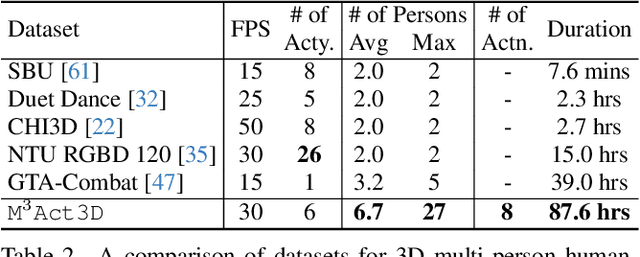
The understanding of complex human interactions and group activities has garnered attention in human-centric computer vision. However, the advancement of the related tasks is hindered due to the difficulty of obtaining large-scale labeled real-world datasets. To mitigate the issue, we propose M3Act, a multi-view multi-group multi-person human atomic action and group activity data generator. Powered by the Unity engine, M3Act contains simulation-ready 3D scenes and human assets, configurable lighting and camera systems, highly parameterized modular group activities, and a large degree of domain randomization during the data generation process. Our data generator is capable of generating large-scale datasets of human activities with multiple viewpoints, modalities (RGB images, 2D poses, 3D motions), and high-quality annotations for individual persons and multi-person groups (2D bounding boxes, instance segmentation masks, individual actions and group activity categories). Using M3Act, we perform synthetic data pre-training for 2D skeleton-based group activity recognition and RGB-based multi-person pose tracking. The results indicate that learning from our synthetic datasets largely improves the model performances on real-world datasets, with the highest gain of 5.59% and 7.32% respectively in group and person recognition accuracy on CAD2, as well as an improvement of 6.63 in MOTP on HiEve. Pre-training with our synthetic data also leads to faster model convergence on downstream tasks (up to 6.8% faster). Moreover, M3Act opens new research problems for 3D group activity generation. We release M3Act3D, an 87.6-hour 3D motion dataset of human activities with larger group sizes and higher complexity of inter-person interactions than previous multi-person datasets. We define multiple metrics and propose a competitive baseline for the novel task.
MSI: Maximize Support-Set Information for Few-Shot Segmentation
Dec 09, 2022
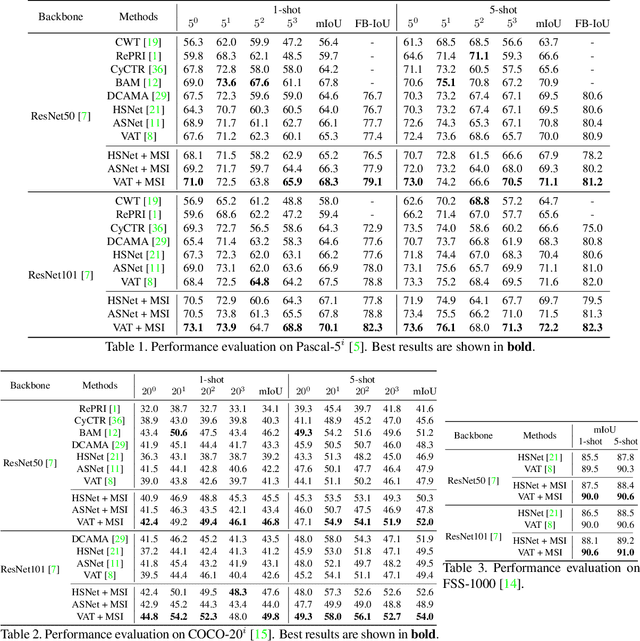
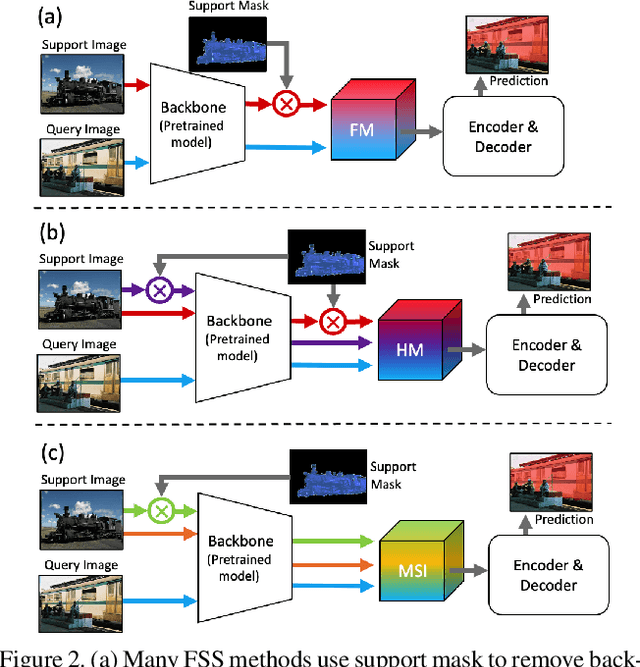
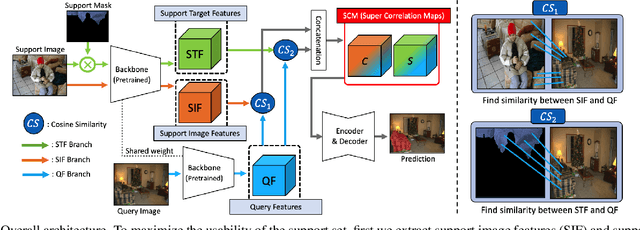
FSS(Few-shot segmentation)~aims to segment a target class with a small number of labeled images (support Set). To extract information relevant to target class, a dominant approach in best performing FSS baselines removes background features using support mask. We observe that this support mask presents an information bottleneck in several challenging FSS cases e.g., for small targets and/or inaccurate target boundaries. To this end, we present a novel method (MSI), which maximizes the support-set information by exploiting two complementary source of features in generating super correlation maps. We validate the effectiveness of our approach by instantiating it into three recent and strong FSS baselines. Experimental results on several publicly available FSS benchmarks show that our proposed method consistently improves the performance by visible margins and allows faster convergence. Our codes and models will be publicly released.
An Information-Theoretic Approach for Estimating Scenario Generalization in Crowd Motion Prediction
Nov 02, 2022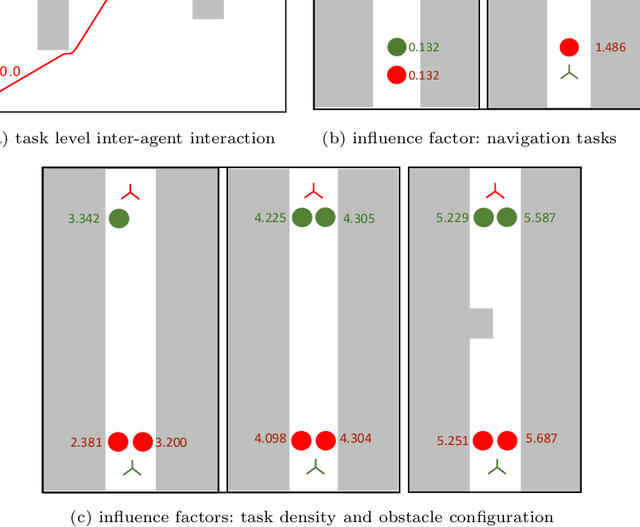
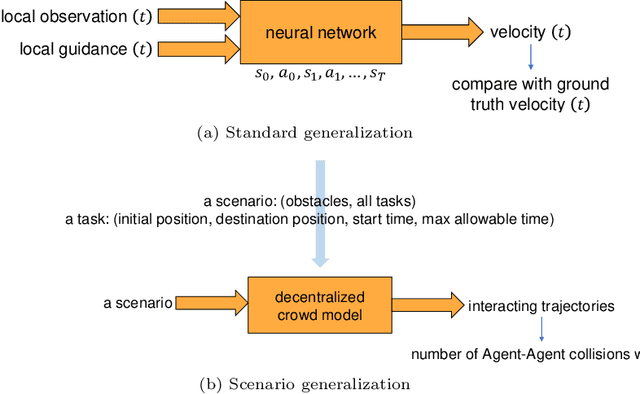

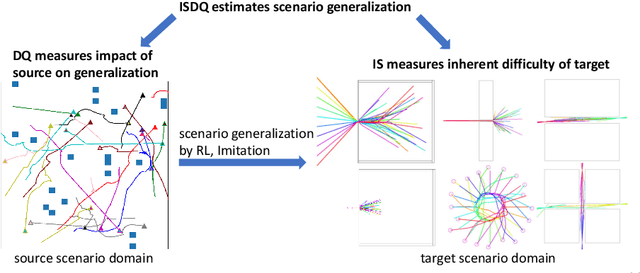
Learning-based approaches to modeling crowd motion have become increasingly successful but require training and evaluation on large datasets, coupled with complex model selection and parameter tuning. To circumvent this tremendously time-consuming process, we propose a novel scoring method, which characterizes generalization of models trained on source crowd scenarios and applied to target crowd scenarios using a training-free, model-agnostic Interaction + Diversity Quantification score, ISDQ. The Interaction component aims to characterize the difficulty of scenario domains, while the diversity of a scenario domain is captured in the Diversity score. Both scores can be computed in a computation tractable manner. Our experimental results validate the efficacy of the proposed method on several simulated and real-world (source,target) generalization tasks, demonstrating its potential to select optimal domain pairs before training and testing a model.
HMFS: Hybrid Masking for Few-Shot Segmentation
Mar 24, 2022
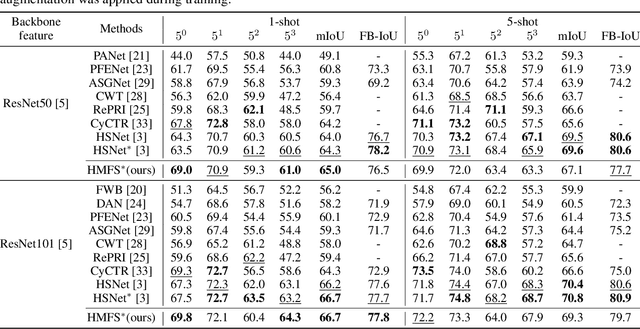
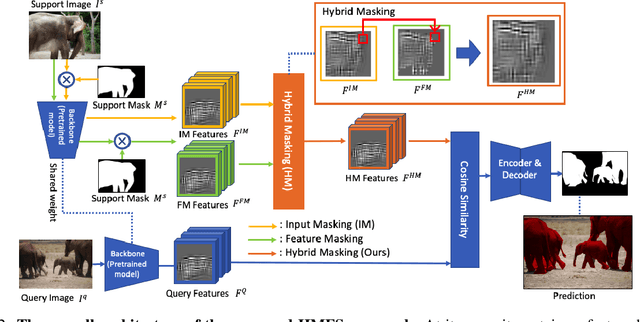
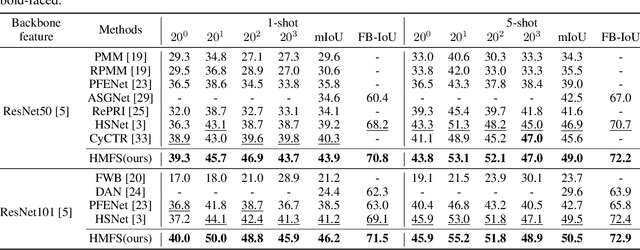
We study few-shot semantic segmentation that aims to segment a target object from a query image when provided with a few annotated support images of the target class. Several recent methods resort to a feature masking (FM) technique, introduced by [1], to discard irrelevant feature activations to facilitate reliable segmentation mask prediction. A fundamental limitation of FM is the inability to preserve the fine-grained spatial details that affect the accuracy of segmentation mask, especially for small target objects. In this paper, we develop a simple, effective, and efficient approach to enhance feature masking (FM). We dub the enhanced FM as hybrid masking (HM). Specifically, we compensate for the loss of fine-grained spatial details in FM technique by investigating and leveraging a complementary basic input masking method [2]. To validate the effectiveness of HM, we instantiate it into a strong baseline [3], and coin the resulting framework as HMFS. Experimental results on three publicly available benchmarks reveal that HMFS outperforms the current state-of-the-art methods by visible margins.
MUSE-VAE: Multi-Scale VAE for Environment-Aware Long Term Trajectory Prediction
Jan 18, 2022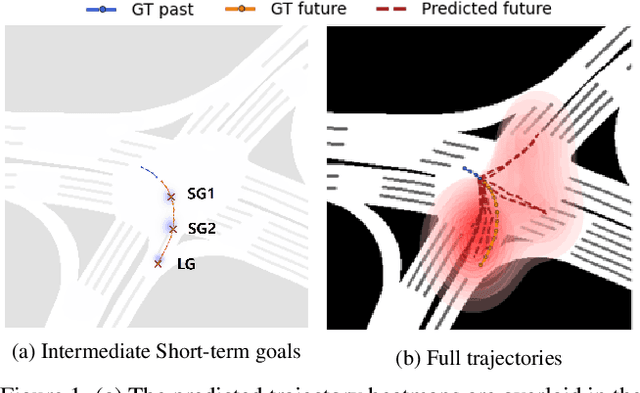
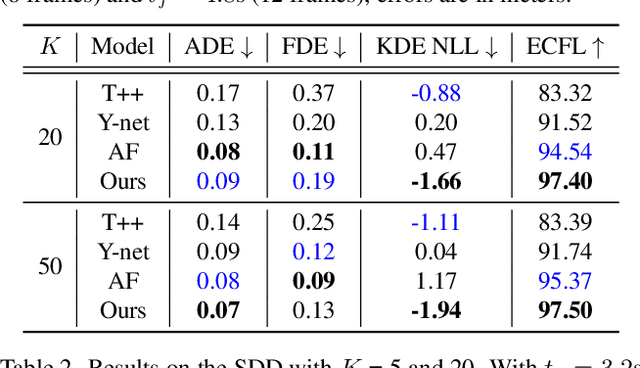
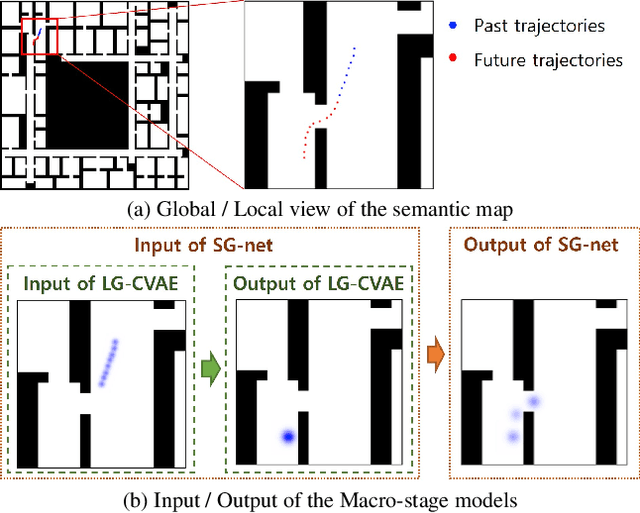
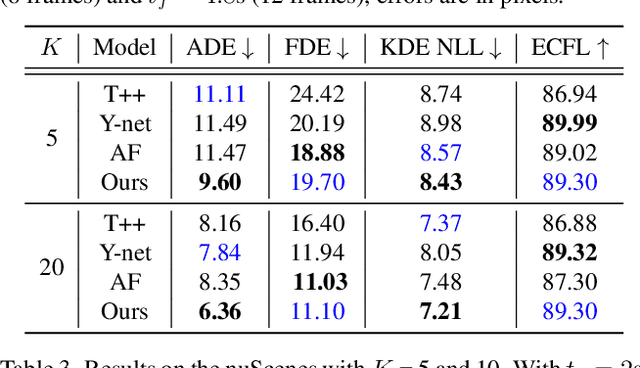
Accurate long-term trajectory prediction in complex scenes, where multiple agents (e.g., pedestrians or vehicles) interact with each other and the environment while attempting to accomplish diverse and often unknown goals, is a challenging stochastic forecasting problem. In this work, we propose MUSE, a new probabilistic modeling framework based on a cascade of Conditional VAEs, which tackles the long-term, uncertain trajectory prediction task using a coarse-to-fine multi-factor forecasting architecture. In its Macro stage, the model learns a joint pixel-space representation of two key factors, the underlying environment and the agent movements, to predict the long and short-term motion goals. Conditioned on them, the Micro stage learns a fine-grained spatio-temporal representation for the prediction of individual agent trajectories. The VAE backbones across the two stages make it possible to naturally account for the joint uncertainty at both levels of granularity. As a result, MUSE offers diverse and simultaneously more accurate predictions compared to the current state-of-the-art. We demonstrate these assertions through a comprehensive set of experiments on nuScenes and SDD benchmarks as well as PFSD, a new synthetic dataset, which challenges the forecasting ability of models on complex agent-environment interaction scenarios.
Deep Crowd-Flow Prediction in Built Environments
Oct 13, 2019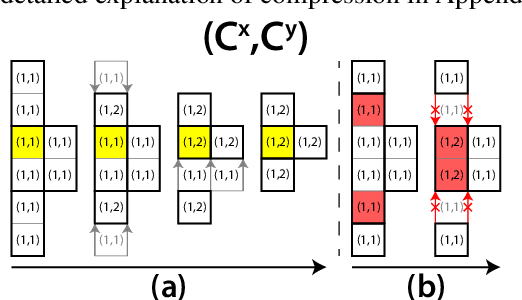
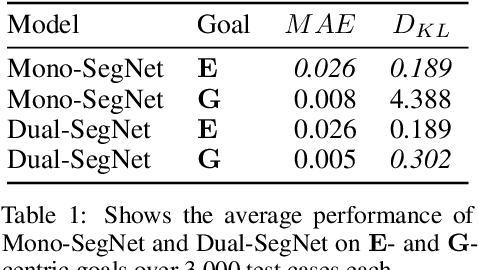
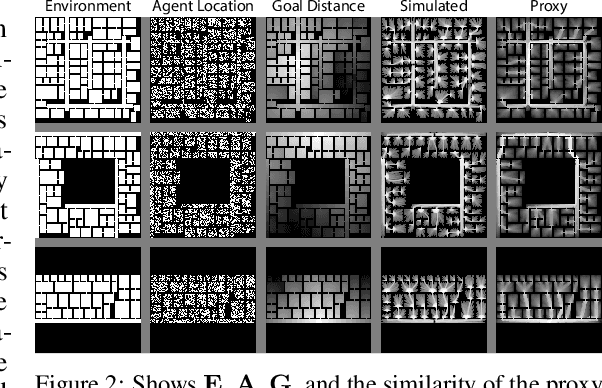
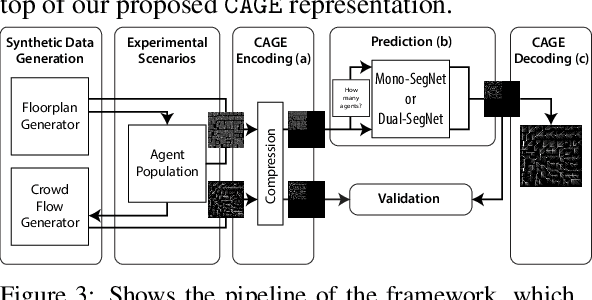
Predicting the behavior of crowds in complex environments is a key requirement in a multitude of application areas, including crowd and disaster management, architectural design, and urban planning. Given a crowd's immediate state, current approaches simulate crowd movement to arrive at a future state. However, most applications require the ability to predict hundreds of possible simulation outcomes (e.g., under different environment and crowd situations) at real-time rates, for which these approaches are prohibitively expensive. In this paper, we propose an approach to instantly predict the long-term flow of crowds in arbitrarily large, realistic environments. Central to our approach is a novel CAGE representation consisting of Capacity, Agent, Goal, and Environment-oriented information, which efficiently encodes and decodes crowd scenarios into compact, fixed-size representations that are environmentally lossless. We present a framework to facilitate the accurate and efficient prediction of crowd flow in never-before-seen crowd scenarios. We conduct a series of experiments to evaluate the efficacy of our approach and showcase positive results.