 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSimGen: Controllable Diffusion Model for Simultaneous Image and Mask Generation
Mar 25, 2025The acquisition of annotated datasets with paired images and segmentation masks is a critical challenge in domains such as medical imaging, remote sensing, and computer vision. Manual annotation demands significant resources, faces ethical constraints, and depends heavily on domain expertise. Existing generative models often target single-modality outputs, either images or segmentation masks, failing to address the need for high-quality, simultaneous image-mask generation. Additionally, these models frequently lack adaptable conditioning mechanisms, restricting control over the generated outputs and limiting their applicability for dataset augmentation and rare scenario simulation. We propose CoSimGen, a diffusion-based framework for controllable simultaneous image and mask generation. Conditioning is intuitively achieved through (1) text prompts grounded in class semantics, (2) spatial embedding of context prompts to provide spatial coherence, and (3) spectral embedding of timestep information to model noise levels during diffusion. To enhance controllability and training efficiency, the framework incorporates contrastive triplet loss between text and class embeddings, alongside diffusion and adversarial losses. Initial low-resolution outputs 128 x 128 are super-resolved to 512 x 512, producing high-fidelity images and masks with strict adherence to conditions. We evaluate CoSimGen on metrics such as FID, KID, LPIPS, Class FID, Positive predicted value for image fidelity and semantic alignment of generated samples over 4 diverse datasets. CoSimGen achieves state-of-the-art performance across all datasets, achieving the lowest KID of 0.11 and LPIPS of 0.53 across datasets.
SimGen: A Diffusion-Based Framework for Simultaneous Surgical Image and Segmentation Mask Generation
Jan 15, 2025



Acquiring and annotating surgical data is often resource-intensive, ethical constraining, and requiring significant expert involvement. While generative AI models like text-to-image can alleviate data scarcity, incorporating spatial annotations, such as segmentation masks, is crucial for precision-driven surgical applications, simulation, and education. This study introduces both a novel task and method, SimGen, for Simultaneous Image and Mask Generation. SimGen is a diffusion model based on the DDPM framework and Residual U-Net, designed to jointly generate high-fidelity surgical images and their corresponding segmentation masks. The model leverages cross-correlation priors to capture dependencies between continuous image and discrete mask distributions. Additionally, a Canonical Fibonacci Lattice (CFL) is employed to enhance class separability and uniformity in the RGB space of the masks. SimGen delivers high-fidelity images and accurate segmentation masks, outperforming baselines across six public datasets assessed on image and semantic inception distance metrics. Ablation study shows that the CFL improves mask quality and spatial separation. Downstream experiments suggest generated image-mask pairs are usable if regulations limit human data release for research. This work offers a cost-effective solution for generating paired surgical images and complex labels, advancing surgical AI development by reducing the need for expensive manual annotations.
Learning from Synthetic Human Group Activities
Jul 16, 2023
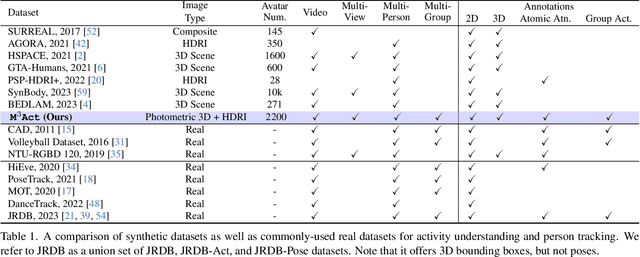
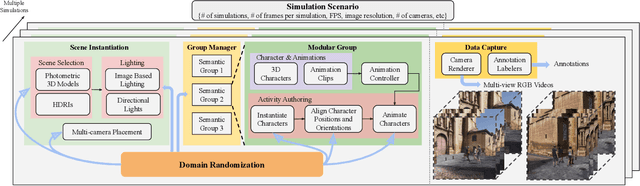
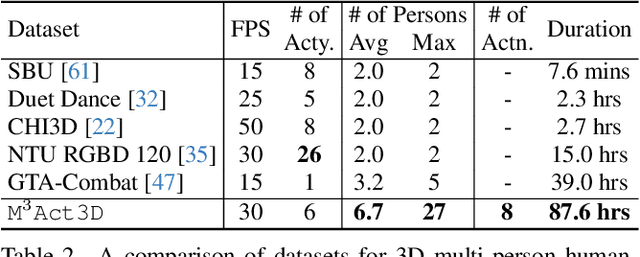
The understanding of complex human interactions and group activities has garnered attention in human-centric computer vision. However, the advancement of the related tasks is hindered due to the difficulty of obtaining large-scale labeled real-world datasets. To mitigate the issue, we propose M3Act, a multi-view multi-group multi-person human atomic action and group activity data generator. Powered by the Unity engine, M3Act contains simulation-ready 3D scenes and human assets, configurable lighting and camera systems, highly parameterized modular group activities, and a large degree of domain randomization during the data generation process. Our data generator is capable of generating large-scale datasets of human activities with multiple viewpoints, modalities (RGB images, 2D poses, 3D motions), and high-quality annotations for individual persons and multi-person groups (2D bounding boxes, instance segmentation masks, individual actions and group activity categories). Using M3Act, we perform synthetic data pre-training for 2D skeleton-based group activity recognition and RGB-based multi-person pose tracking. The results indicate that learning from our synthetic datasets largely improves the model performances on real-world datasets, with the highest gain of 5.59% and 7.32% respectively in group and person recognition accuracy on CAD2, as well as an improvement of 6.63 in MOTP on HiEve. Pre-training with our synthetic data also leads to faster model convergence on downstream tasks (up to 6.8% faster). Moreover, M3Act opens new research problems for 3D group activity generation. We release M3Act3D, an 87.6-hour 3D motion dataset of human activities with larger group sizes and higher complexity of inter-person interactions than previous multi-person datasets. We define multiple metrics and propose a competitive baseline for the novel task.