 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenVP: Generating Visual Puzzles with Contrastive Hierarchical VAEs
Mar 30, 2025Raven's Progressive Matrices (RPMs) is an established benchmark to examine the ability to perform high-level abstract visual reasoning (AVR). Despite the current success of algorithms that solve this task, humans can generalize beyond a given puzzle and create new puzzles given a set of rules, whereas machines remain locked in solving a fixed puzzle from a curated choice list. We propose Generative Visual Puzzles (GenVP), a framework to model the entire RPM generation process, a substantially more challenging task. Our model's capability spans from generating multiple solutions for one specific problem prompt to creating complete new puzzles out of the desired set of rules. Experiments on five different datasets indicate that GenVP achieves state-of-the-art (SOTA) performance both in puzzle-solving accuracy and out-of-distribution (OOD) generalization in 22 OOD scenarios. Compared to SOTA generative approaches, which struggle to solve RPMs when the feasible solution space increases, GenVP efficiently generalizes to these challenging setups. Moreover, our model demonstrates the ability to produce a wide range of complete RPMs given a set of abstract rules by effectively capturing the relationships between abstract rules and visual object properties.
EAZY: Eliminating Hallucinations in LVLMs by Zeroing out Hallucinatory Image Tokens
Mar 10, 2025Despite their remarkable potential, Large Vision-Language Models (LVLMs) still face challenges with object hallucination, a problem where their generated outputs mistakenly incorporate objects that do not actually exist. Although most works focus on addressing this issue within the language-model backbone, our work shifts the focus to the image input source, investigating how specific image tokens contribute to hallucinations. Our analysis reveals a striking finding: a small subset of image tokens with high attention scores are the primary drivers of object hallucination. By removing these hallucinatory image tokens (only 1.5% of all image tokens), the issue can be effectively mitigated. This finding holds consistently across different models and datasets. Building on this insight, we introduce EAZY, a novel, training-free method that automatically identifies and Eliminates hAllucinations by Zeroing out hallucinatorY image tokens. We utilize EAZY for unsupervised object hallucination detection, achieving 15% improvement compared to previous methods. Additionally, EAZY demonstrates remarkable effectiveness in mitigating hallucinations while preserving model utility and seamlessly adapting to various LVLM architectures.
CASIM: Composite Aware Semantic Injection for Text to Motion Generation
Feb 04, 2025Recent advances in generative modeling and tokenization have driven significant progress in text-to-motion generation, leading to enhanced quality and realism in generated motions. However, effectively leveraging textual information for conditional motion generation remains an open challenge. We observe that current approaches, primarily relying on fixed-length text embeddings (e.g., CLIP) for global semantic injection, struggle to capture the composite nature of human motion, resulting in suboptimal motion quality and controllability. To address this limitation, we propose the Composite Aware Semantic Injection Mechanism (CASIM), comprising a composite-aware semantic encoder and a text-motion aligner that learns the dynamic correspondence between text and motion tokens. Notably, CASIM is model and representation-agnostic, readily integrating with both autoregressive and diffusion-based methods. Experiments on HumanML3D and KIT benchmarks demonstrate that CASIM consistently improves motion quality, text-motion alignment, and retrieval scores across state-of-the-art methods. Qualitative analyses further highlight the superiority of our composite-aware approach over fixed-length semantic injection, enabling precise motion control from text prompts and stronger generalization to unseen text inputs.
Physics-Based Dynamic Models Hybridisation Using Physics-Informed Neural Networks
Dec 10, 2024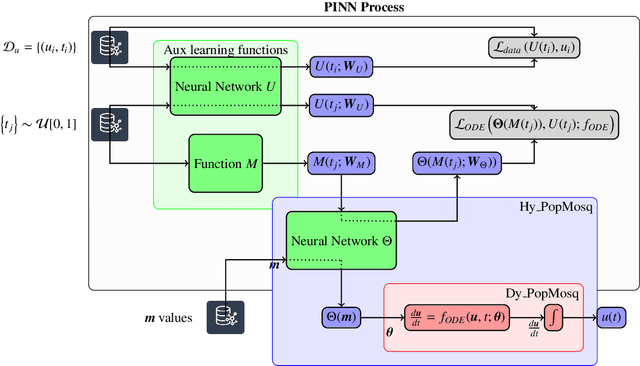
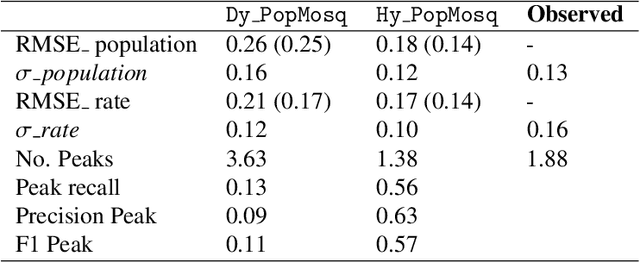
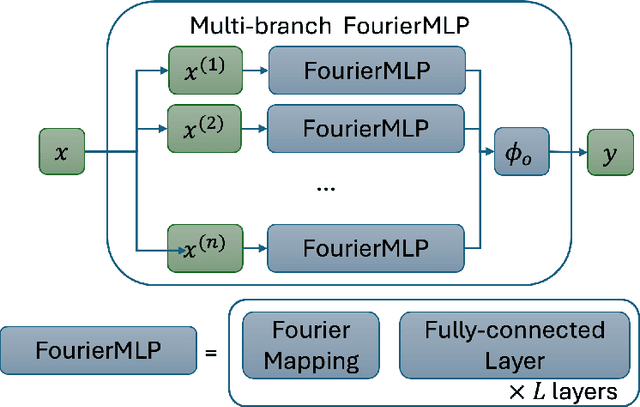
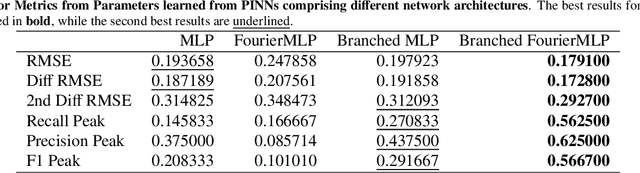
Physics-based dynamic models (PBDMs) are simplified representations of complex dynamical systems. PBDMs take specific processes within a complex system and assign a fragment of variables and an accompanying set of parameters to depict the processes. As this often leads to suboptimal parameterisation of the system, a key challenge requires refining the empirical parameters and variables to reduce uncertainties while maintaining the model s explainability and enhancing its predictive accuracy. We demonstrate that a hybrid mosquito population dynamics model, which integrates a PBDM with Physics-Informed Neural Networks (PINN), retains the explainability of the PBDM by incorporating the PINN-learned model parameters in place of its empirical counterparts. Specifically, we address the limitations of traditional PBDMs by modelling the parameters of larva and pupa development rates using a PINN that encodes complex, learned interactions of air temperature, precipitation and humidity. Our results demonstrate improved mosquito population simulations including the difficult-to-predict mosquito population peaks. This opens the possibility of hybridisation concept application on other complex systems based on PBDMs such as cancer growth to address the challenges posed by scarce and noisy data, and to numerical weather prediction and climate modelling to overcome the gap between physics-based and data-driven weather prediction models.
TrajDiffuse: A Conditional Diffusion Model for Environment-Aware Trajectory Prediction
Oct 14, 2024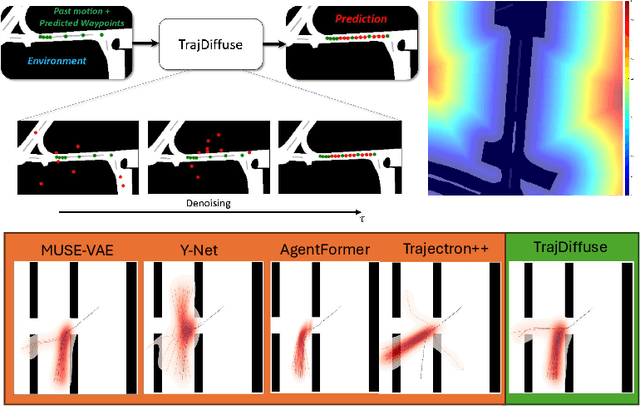



Accurate prediction of human or vehicle trajectories with good diversity that captures their stochastic nature is an essential task for many applications. However, many trajectory prediction models produce unreasonable trajectory samples that focus on improving diversity or accuracy while neglecting other key requirements, such as collision avoidance with the surrounding environment. In this work, we propose TrajDiffuse, a planning-based trajectory prediction method using a novel guided conditional diffusion model. We form the trajectory prediction problem as a denoising impaint task and design a map-based guidance term for the diffusion process. TrajDiffuse is able to generate trajectory predictions that match or exceed the accuracy and diversity of the SOTA, while adhering almost perfectly to environmental constraints. We demonstrate the utility of our model through experiments on the nuScenes and PFSD datasets and provide an extensive benchmark analysis against the SOTA methods.
Box2Flow: Instance-based Action Flow Graphs from Videos
Aug 30, 2024A large amount of procedural videos on the web show how to complete various tasks. These tasks can often be accomplished in different ways and step orderings, with some steps able to be performed simultaneously, while others are constrained to be completed in a specific order. Flow graphs can be used to illustrate the step relationships of a task. Current task-based methods try to learn a single flow graph for all available videos of a specific task. The extracted flow graphs tend to be too abstract, failing to capture detailed step descriptions. In this work, our aim is to learn accurate and rich flow graphs by extracting them from a single video. We propose Box2Flow, an instance-based method to predict a step flow graph from a given procedural video. In detail, we extract bounding boxes from videos, predict pairwise edge probabilities between step pairs, and build the flow graph with a spanning tree algorithm. Experiments on MM-ReS and YouCookII show our method can extract flow graphs effectively.
CIC-BART-SSA: Controllable Image Captioning with Structured Semantic Augmentation
Jul 16, 2024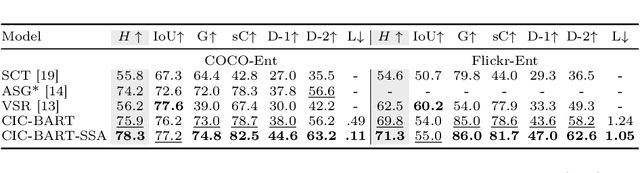
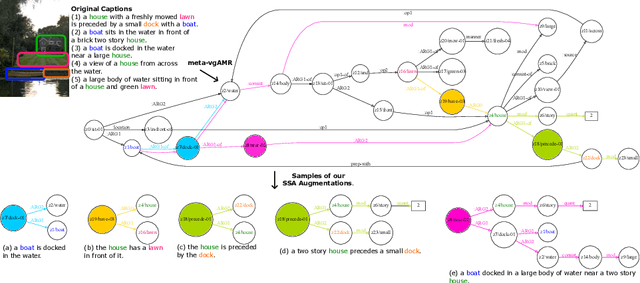


Controllable Image Captioning (CIC) aims at generating natural language descriptions for an image, conditioned on information provided by end users, e.g., regions, entities or events of interest. However, available image--language datasets mainly contain captions that describe the entirety of an image, making them ineffective for training CIC models that can potentially attend to any subset of regions or relationships. To tackle this challenge, we propose a novel, fully automatic method to sample additional focused and visually grounded captions using a unified structured semantic representation built on top of the existing set of captions associated with an image. We leverage Abstract Meaning Representation (AMR), a cross-lingual graph-based semantic formalism, to encode all possible spatio-semantic relations between entities, beyond the typical spatial-relations-only focus of current methods. We use this Structured Semantic Augmentation (SSA) framework to augment existing image--caption datasets with the grounded controlled captions, increasing their spatial and semantic diversity and focal coverage. We then develop a new model, CIC-BART-SSA, specifically tailored for the CIC task, that sources its control signals from SSA-diversified datasets. We empirically show that, compared to SOTA CIC models, CIC-BART-SSA generates captions that are superior in diversity and text quality, are competitive in controllability, and, importantly, minimize the gap between broad and highly focused controlled captioning performance by efficiently generalizing to the challenging highly focused scenarios. Code is available at https://github.com/SamsungLabs/CIC-BART-SSA.
ALWOD: Active Learning for Weakly-Supervised Object Detection
Sep 14, 2023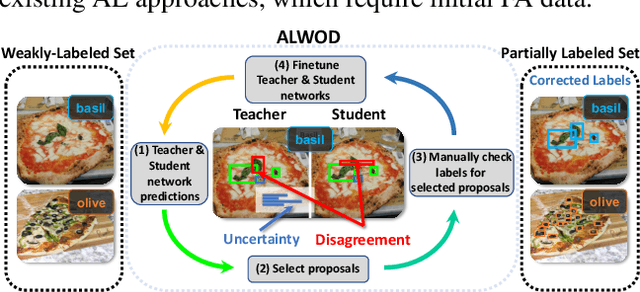
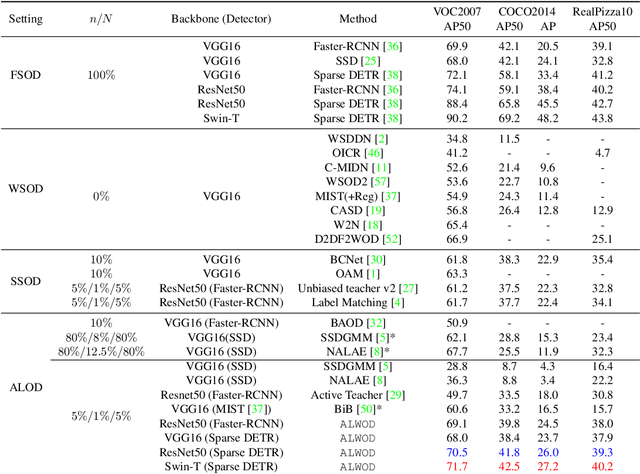
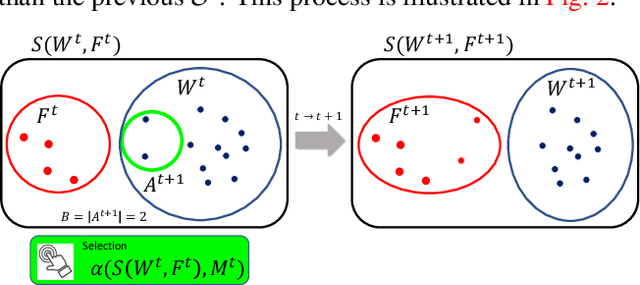
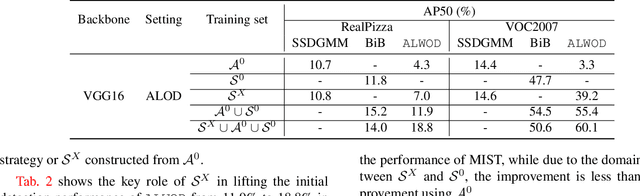
Object detection (OD), a crucial vision task, remains challenged by the lack of large training datasets with precise object localization labels. In this work, we propose ALWOD, a new framework that addresses this problem by fusing active learning (AL) with weakly and semi-supervised object detection paradigms. Because the performance of AL critically depends on the model initialization, we propose a new auxiliary image generator strategy that utilizes an extremely small labeled set, coupled with a large weakly tagged set of images, as a warm-start for AL. We then propose a new AL acquisition function, another critical factor in AL success, that leverages the student-teacher OD pair disagreement and uncertainty to effectively propose the most informative images to annotate. Finally, to complete the AL loop, we introduce a new labeling task delegated to human annotators, based on selection and correction of model-proposed detections, which is both rapid and effective in labeling the informative images. We demonstrate, across several challenging benchmarks, that ALWOD significantly narrows the gap between the ODs trained on few partially labeled but strategically selected image instances and those that rely on the fully-labeled data. Our code is publicly available on https://github.com/seqam-lab/ALWOD.
NP-SemiSeg: When Neural Processes meet Semi-Supervised Semantic Segmentation
Aug 05, 2023Semi-supervised semantic segmentation involves assigning pixel-wise labels to unlabeled images at training time. This is useful in a wide range of real-world applications where collecting pixel-wise labels is not feasible in time or cost. Current approaches to semi-supervised semantic segmentation work by predicting pseudo-labels for each pixel from a class-wise probability distribution output by a model. If the predicted probability distribution is incorrect, however, this leads to poor segmentation results, which can have knock-on consequences in safety critical systems, like medical images or self-driving cars. It is, therefore, important to understand what a model does not know, which is mainly achieved by uncertainty quantification. Recently, neural processes (NPs) have been explored in semi-supervised image classification, and they have been a computationally efficient and effective method for uncertainty quantification. In this work, we move one step forward by adapting NPs to semi-supervised semantic segmentation, resulting in a new model called NP-SemiSeg. We experimentally evaluated NP-SemiSeg on the public benchmarks PASCAL VOC 2012 and Cityscapes, with different training settings, and the results verify its effectiveness.
Learning from Synthetic Human Group Activities
Jul 16, 2023
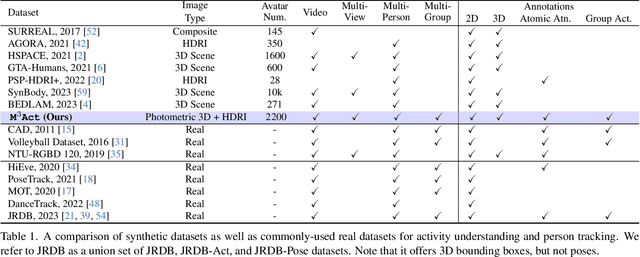
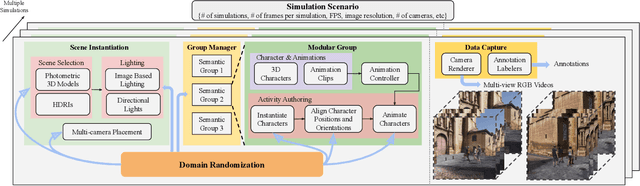
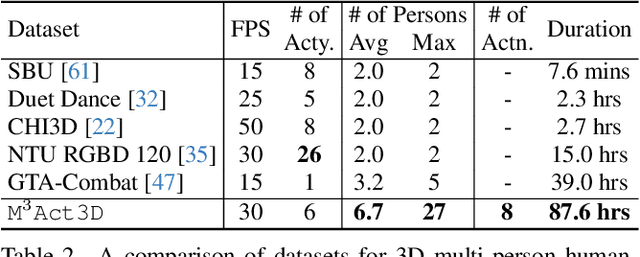
The understanding of complex human interactions and group activities has garnered attention in human-centric computer vision. However, the advancement of the related tasks is hindered due to the difficulty of obtaining large-scale labeled real-world datasets. To mitigate the issue, we propose M3Act, a multi-view multi-group multi-person human atomic action and group activity data generator. Powered by the Unity engine, M3Act contains simulation-ready 3D scenes and human assets, configurable lighting and camera systems, highly parameterized modular group activities, and a large degree of domain randomization during the data generation process. Our data generator is capable of generating large-scale datasets of human activities with multiple viewpoints, modalities (RGB images, 2D poses, 3D motions), and high-quality annotations for individual persons and multi-person groups (2D bounding boxes, instance segmentation masks, individual actions and group activity categories). Using M3Act, we perform synthetic data pre-training for 2D skeleton-based group activity recognition and RGB-based multi-person pose tracking. The results indicate that learning from our synthetic datasets largely improves the model performances on real-world datasets, with the highest gain of 5.59% and 7.32% respectively in group and person recognition accuracy on CAD2, as well as an improvement of 6.63 in MOTP on HiEve. Pre-training with our synthetic data also leads to faster model convergence on downstream tasks (up to 6.8% faster). Moreover, M3Act opens new research problems for 3D group activity generation. We release M3Act3D, an 87.6-hour 3D motion dataset of human activities with larger group sizes and higher complexity of inter-person interactions than previous multi-person datasets. We define multiple metrics and propose a competitive baseline for the novel task.