 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Long-Horizon Vessel Trajectory and Destination Forecasting with Reasoning Large Language Models
Jun 07, 2026Long-horizon maritime trajectory prediction is important for shipping management, logistics planning, and maritime risk analysis, yet month-level forecasting remains insufficiently studied. Existing deep learning methods mainly focus on short- and mid-term coordinate extrapolation and often struggle to preserve route feasibility and destination correctness over extended horizons. This paper investigates joint long-horizon vessel trajectory and destination forecasting with reasoning-capable large language models, and develops a Maritime LLM post-training framework based on Reinforcement Learning with Verifiable Reward (RLVR). An AIS-based benchmark is constructed with 60-day historical trajectories and 30-day forecasting horizons, where trajectories are converted into semantic textual representations for RL prompt construction. RLVR aligns LLMs with maritime forecasting objectives by enforcing physical validity, providing early-weighted trajectory supervision, and evaluating destination correctness through hierarchical matching and curriculum learning. Experimental results show that RLVR-trained LLMs substantially improve over zero-shot LLMs and representative deep learning baselines, especially on destination-related metrics. Among the evaluated RLVR-trained variants, 4B LLMs achieve the best overall performance, suggesting that reward-compatible optimization and task-specific capacity matching are more important than simply using larger 8B or 14B LLMs. The results also show that LSTM remains a strong deep learning baseline under limited fine-tuning data, while Transformer-style spatio-temporal models typically require larger datasets and richer structured inputs. Overall, this work advances semantic, verifier-aligned maritime forecasting for operational decision support.
Revisiting Uncertainty: On Evidential Learning for Partially Relevant Video Retrieval
May 07, 2026Partially relevant video retrieval aims to retrieve untrimmed videos using text queries that describe only partial content. However, the inherent asymmetry between brief queries and rich video content inevitably introduces uncertainty into the retrieval process. In this setting, vague queries often induce semantic ambiguity across videos, a challenge that is further exacerbated by the sparse temporal supervision within videos, which fails to provide sufficient matching evidence. To address this, we propose Holmes, a hierarchical evidential learning framework that aggregates multi-granular cross-modal evidence to quantify and model uncertainty explicitly. At the inter-video level, similarity scores are interpreted as evidential support and modeled via a Dirichlet distribution. Based on the proposed three-fold principle, we perform fine-grained query identification, which then guides query-adaptive calibrated learning. At the intra-video level, to accumulate denser evidence, we formulate a soft query-clip alignment via flexible optimal transport with an adaptive dustbin, which alleviates sparse temporal supervision while suppressing spurious local responses. Extensive experiments demonstrate that Holmes outperforms state-of-the-art methods. Code is released at https://github.com/lijun2005/ICML26-Holmes.
Imagine Before Concentration: Diffusion-Guided Registers Enhance Partially Relevant Video Retrieval
Apr 04, 2026Partially Relevant Video Retrieval (PRVR) aims to retrieve untrimmed videos based on text queries that describe only partial events. Existing methods suffer from incomplete global contextual perception, struggling with query ambiguity and local noise induced by spurious responses. To address these issues, we propose DreamPRVR, which adopts a coarse-to-fine representation learning paradigm. The model first generates global contextual semantic registers as coarse-grained highlights spanning the entire video and then concentrates on fine-grained similarity optimization for precise cross-modal matching. Concretely, these registers are generated by initializing from the video-centric distribution produced by a probabilistic variational sampler and then iteratively refined via a text-supervised truncated diffusion model. During this process, textual semantic structure learning constructs a well-formed textual latent space, enhancing the reliability of global perception. The registers are then adaptively fused with video tokens through register-augmented Gaussian attention blocks, enabling context-aware feature learning. Extensive experiments show that DreamPRVR outperforms state-of-the-art methods. Code is released at https://github.com/lijun2005/CVPR26-DreamPRVR.
TacSIm: A Dataset and Benchmark for Football Tactical Style Imitation
Mar 26, 2026Current football imitation research primarily aims to opti mize reward-based objectives, such as goals scored or win rate proxies, paying less attention to accurately replicat ing real-world team tactical behaviors. We introduce Tac SIm, a large-scale dataset and benchmark for Tactical Style Imitation in football. TacSIm imitates the acitons of all 11 players in one team in the given broadcast footage of Pre mier League matches under a single broadcast view. Under a offensive or defensive broadcast footage, TacSIm projects the beginning positions and actions of all 22 players from both sides onto a standard pitch coordinate system. Tac SIm offers an explicit style imitation task and evaluation protocols. Tactics style imitation is measured by using spatial occupancy similarity and movement vector similarity in defined time, supporting the evaluation of spatial and tem poral similarities for one team. We run multiple baseline methods in a unified virtual environment to generate full team behaviors, enabling both quantitative and visual as sessment of tactical coordination. By using unified data and metrics from broadcast to simulation, TacSIm estab lishes a rigorous benchmark for measuring and modeling style-aligned tactical imitation task in football.
From Verbatim to Gist: Distilling Pyramidal Multimodal Memory via Semantic Information Bottleneck for Long-Horizon Video Agents
Mar 02, 2026While multimodal large language models have demonstrated impressive short-term reasoning, they struggle with long-horizon video understanding due to limited context windows and static memory mechanisms that fail to mirror human cognitive efficiency. Existing paradigms typically fall into two extremes: vision-centric methods that incur high latency and redundancy through dense visual accumulation, or text-centric approaches that suffer from detail loss and hallucination via aggressive captioning. To bridge this gap, we propose MM-Mem, a pyramidal multimodal memory architecture grounded in Fuzzy-Trace Theory. MM-Mem structures memory hierarchically into a Sensory Buffer, Episodic Stream, and Symbolic Schema, enabling the progressive distillation of fine-grained perceptual traces (verbatim) into high-level semantic schemas (gist). Furthermore, to govern the dynamic construction of memory, we derive a Semantic Information Bottleneck objective and introduce SIB-GRPO to optimize the trade-off between memory compression and task-relevant information retention. In inference, we design an entropy-driven top-down memory retrieval strategy, which first tries with the abstract Symbolic Schema and progressively "drills down" to the Sensory Buffer and Episodic Stream under high uncertainty. Extensive experiments across 4 benchmarks confirm the effectiveness of MM-Mem on both offline and streaming tasks, demonstrating robust generalization and validating the effectiveness of cognition-inspired memory organization. Code is available at https://github.com/EliSpectre/MM-Mem.
Large-scale EM Benchmark for Multi-Organelle Instance Segmentation in the Wild
Jan 18, 2026Accurate instance-level segmentation of organelles in electron microscopy (EM) is critical for quantitative analysis of subcellular morphology and inter-organelle interactions. However, current benchmarks, based on small, curated datasets, fail to capture the inherent heterogeneity and large spatial context of in-the-wild EM data, imposing fundamental limitations on current patch-based methods. To address these limitations, we developed a large-scale, multi-source benchmark for multi-organelle instance segmentation, comprising over 100,000 2D EM images across variety cell types and five organelle classes that capture real-world variability. Dataset annotations were generated by our designed connectivity-aware Label Propagation Algorithm (3D LPA) with expert refinement. We further benchmarked several state-of-the-art models, including U-Net, SAM variants, and Mask2Former. Our results show several limitations: current models struggle to generalize across heterogeneous EM data and perform poorly on organelles with global, distributed morphologies (e.g., Endoplasmic Reticulum). These findings underscore the fundamental mismatch between local-context models and the challenge of modeling long-range structural continuity in the presence of real-world variability. The benchmark dataset and labeling tool will be publicly released soon.
Deep Learning Superresolution for 7T Knee MR Imaging: Impact on Image Quality and Diagnostic Performance
Jan 05, 2026Background: Deep learning superresolution (SR) may enhance musculoskeletal MR image quality, but its diagnostic value in knee imaging at 7T is unclear. Objectives: To compare image quality and diagnostic performance of SR, low-resolution (LR), and high-resolution (HR) 7T knee MRI. Methods: In this prospective study, 42 participants underwent 7T knee MRI with LR (0.8*0.8*2 mm3) and HR (0.4*0.4*2 mm3) sequences. SR images were generated from LR data using a Hybrid Attention Transformer model. Three radiologists assessed image quality, anatomic conspicuity, and detection of knee pathologies. Arthroscopy served as reference in 10 cases. Results: SR images showed higher overall quality than LR (median score 5 vs 4, P<.001) and lower noise than HR (5 vs 4, P<.001). Visibility of cartilage, menisci, and ligaments was superior in SR and HR compared to LR (P<.001). Detection rates and diagnostic performance (sensitivity, specificity, AUC) for intra-articular pathology were similar across image types (P>=.095). Conclusions: Deep learning superresolution improved subjective image quality in 7T knee MRI but did not increase diagnostic accuracy compared with standard LR imaging.
RFAssigner: A Generic Label Assignment Strategy for Dense Object Detection
Jan 03, 2026Label assignment is a critical component in training dense object detectors. State-of-the-art methods typically assign each training sample a positive and a negative weight, optimizing the assignment scheme during training. However, these strategies often assign an insufficient number of positive samples to small objects, leading to a scale imbalance during training. To address this limitation, we introduce RFAssigner, a novel assignment strategy designed to enhance the multi-scale learning capabilities of dense detectors. RFAssigner first establishes an initial set of positive samples using a point-based prior. It then leverages a Gaussian Receptive Field (GRF) distance to measure the similarity between the GRFs of unassigned candidate locations and the ground-truth objects. Based on this metric, RFAssigner adaptively selects supplementary positive samples from the unassigned pool, promoting a more balanced learning process across object scales. Comprehensive experiments on three datasets with distinct object scale distributions validate the effectiveness and generalizability of our method. Notably, a single FCOS-ResNet-50 detector equipped with RFAssigner achieves state-of-the-art performance across all object scales, consistently outperforming existing strategies without requiring auxiliary modules or heuristics.
InteractRank: Personalized Web-Scale Search Pre-Ranking with Cross Interaction Features
Apr 09, 2025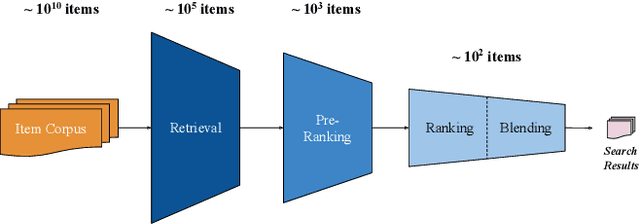

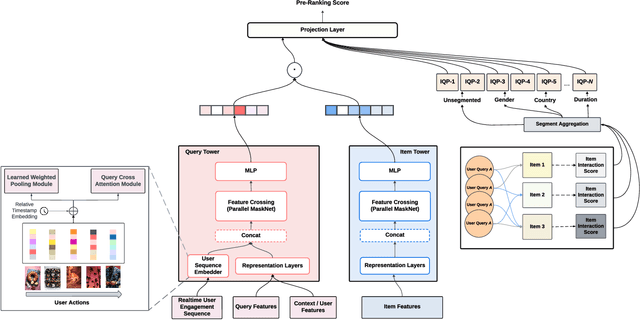
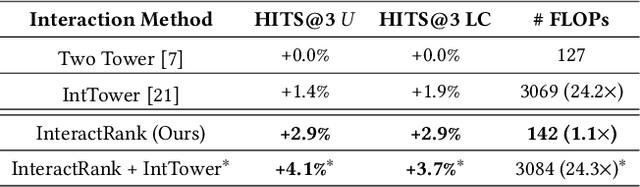
Modern search systems use a multi-stage architecture to deliver personalized results efficiently. Key stages include retrieval, pre-ranking, full ranking, and blending, which refine billions of items to top selections. The pre-ranking stage, vital for scoring and filtering hundreds of thousands of items down to a few thousand, typically relies on two tower models due to their computational efficiency, despite often lacking in capturing complex interactions. While query-item cross interaction features are paramount for full ranking, integrating them into pre-ranking models presents efficiency-related challenges. In this paper, we introduce InteractRank, a novel two tower pre-ranking model with robust cross interaction features used at Pinterest. By incorporating historical user engagement-based query-item interactions in the scoring function along with the two tower dot product, InteractRank significantly boosts pre-ranking performance with minimal latency and computation costs. In real-world A/B experiments at Pinterest, InteractRank improves the online engagement metric by 6.5% over a BM25 baseline and by 3.7% over a vanilla two tower baseline. We also highlight other components of InteractRank, like real-time user-sequence modeling, and analyze their contributions through offline ablation studies. The code for InteractRank is available at https://github.com/pinterest/atg-research/tree/main/InteractRank.
Efficient Self-Supervised Video Hashing with Selective State Spaces
Dec 19, 2024



Self-supervised video hashing (SSVH) is a practical task in video indexing and retrieval. Although Transformers are predominant in SSVH for their impressive temporal modeling capabilities, they often suffer from computational and memory inefficiencies. Drawing inspiration from Mamba, an advanced state-space model, we explore its potential in SSVH to achieve a better balance between efficacy and efficiency. We introduce S5VH, a Mamba-based video hashing model with an improved self-supervised learning paradigm. Specifically, we design bidirectional Mamba layers for both the encoder and decoder, which are effective and efficient in capturing temporal relationships thanks to the data-dependent selective scanning mechanism with linear complexity. In our learning strategy, we transform global semantics in the feature space into semantically consistent and discriminative hash centers, followed by a center alignment loss as a global learning signal. Our self-local-global (SLG) paradigm significantly improves learning efficiency, leading to faster and better convergence. Extensive experiments demonstrate S5VH's improvements over state-of-the-art methods, superior transferability, and scalable advantages in inference efficiency. Code is available at https://github.com/gimpong/AAAI25-S5VH.