 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Hypergraph-Enhanced Prediction of Sequential Medical Visits
Aug 08, 2024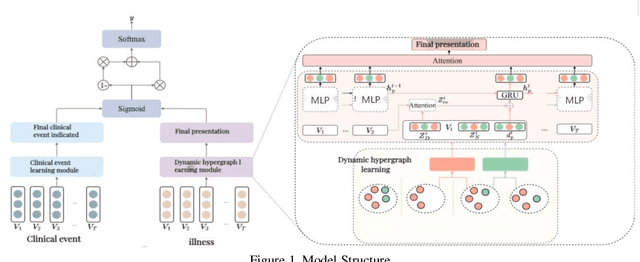
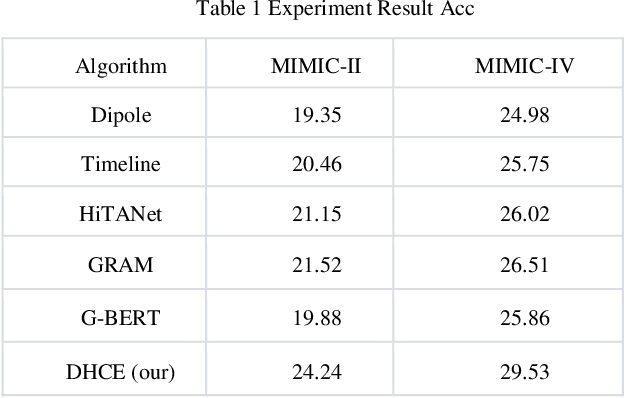
This study introduces a pioneering Dynamic Hypergraph Networks (DHCE) model designed to predict future medical diagnoses from electronic health records with enhanced accuracy. The DHCE model innovates by identifying and differentiating acute and chronic diseases within a patient's visit history, constructing dynamic hypergraphs that capture the complex, high-order interactions between diseases. It surpasses traditional recurrent neural networks and graph neural networks by effectively integrating clinical event data, reflected through medical language model-assisted encoding, into a robust patient representation. Through extensive experiments on two benchmark datasets, MIMIC-III and MIMIC-IV, the DHCE model exhibits superior performance, significantly outpacing established baseline models in the precision of sequential diagnosis prediction.
Adaptive Friction in Deep Learning: Enhancing Optimizers with Sigmoid and Tanh Function
Aug 07, 2024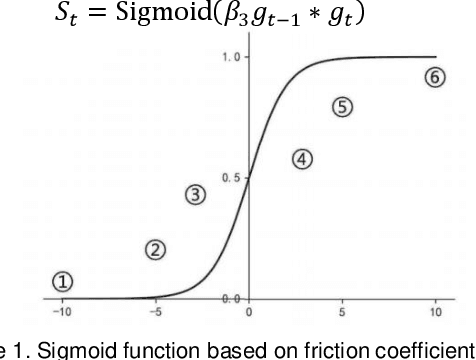
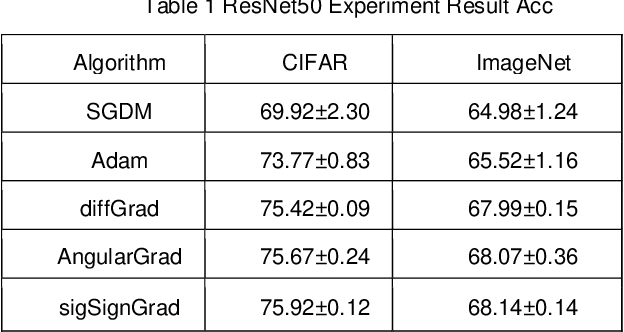

Adaptive optimizers are pivotal in guiding the weight updates of deep neural networks, yet they often face challenges such as poor generalization and oscillation issues. To counter these, we introduce sigSignGrad and tanhSignGrad, two novel optimizers that integrate adaptive friction coefficients based on the Sigmoid and Tanh functions, respectively. These algorithms leverage short-term gradient information, a feature overlooked in traditional Adam variants like diffGrad and AngularGrad, to enhance parameter updates and convergence.Our theoretical analysis demonstrates the wide-ranging adjustment capability of the friction coefficient S, which aligns with targeted parameter update strategies and outperforms existing methods in both optimization trajectory smoothness and convergence rate. Extensive experiments on CIFAR-10, CIFAR-100, and Mini-ImageNet datasets using ResNet50 and ViT architectures confirm the superior performance of our proposed optimizers, showcasing improved accuracy and reduced training time. The innovative approach of integrating adaptive friction coefficients as plug-ins into existing optimizers, exemplified by the sigSignAdamW and sigSignAdamP variants, presents a promising strategy for boosting the optimization performance of established algorithms. The findings of this study contribute to the advancement of optimizer design in deep learning.
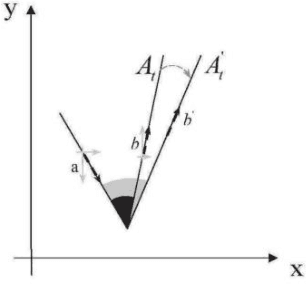
Multiple Greedy Quasi-Newton Methods for Saddle Point Problems
Aug 01, 2024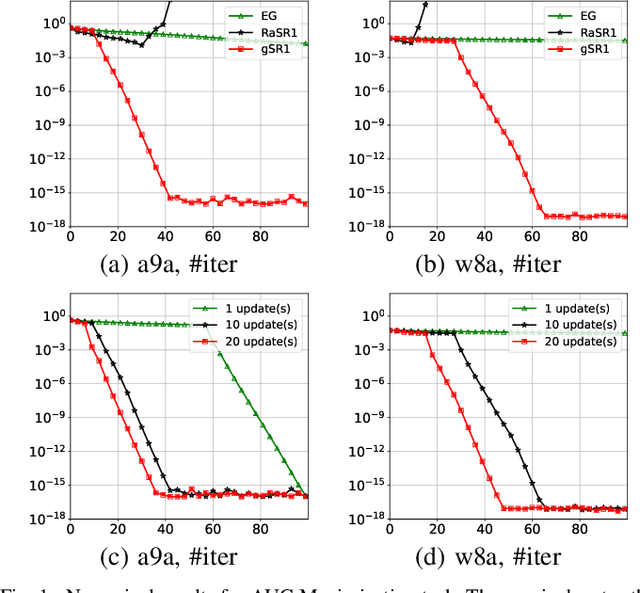
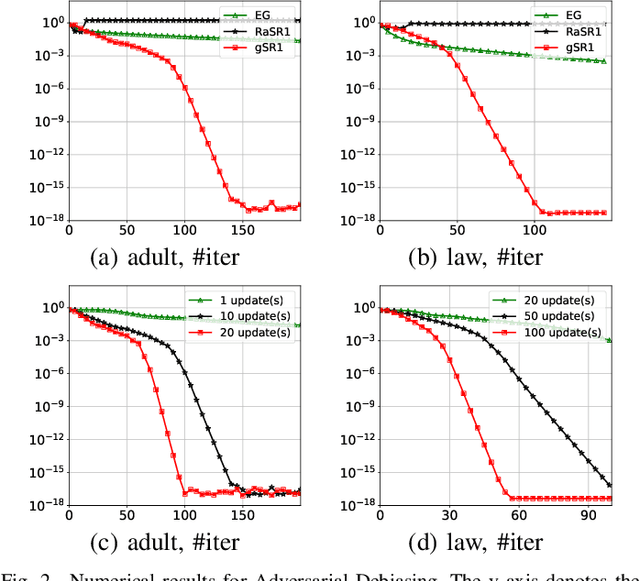
This paper introduces the Multiple Greedy Quasi-Newton (MGSR1-SP) method, a novel approach to solving strongly-convex-strongly-concave (SCSC) saddle point problems. Our method enhances the approximation of the squared indefinite Hessian matrix inherent in these problems, significantly improving both stability and efficiency through iterative greedy updates. We provide a thorough theoretical analysis of MGSR1-SP, demonstrating its linear-quadratic convergence rate. Numerical experiments conducted on AUC maximization and adversarial debiasing problems, compared with state-of-the-art algorithms, underscore our method's enhanced convergence rate. These results affirm the potential of MGSR1-SP to improve performance across a broad spectrum of machine learning applications where efficient and accurate Hessian approximations are crucial.
Design and Optimization of Big Data and Machine Learning-Based Risk Monitoring System in Financial Markets
Jul 28, 2024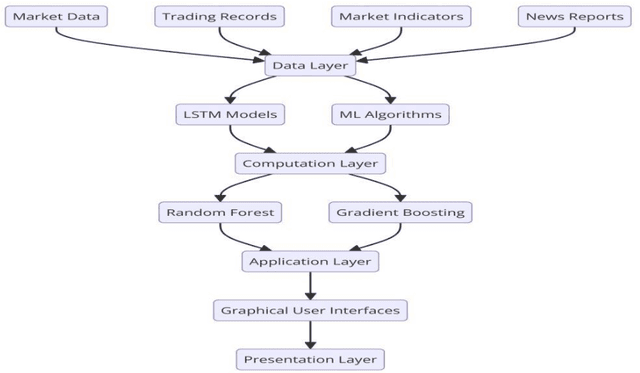
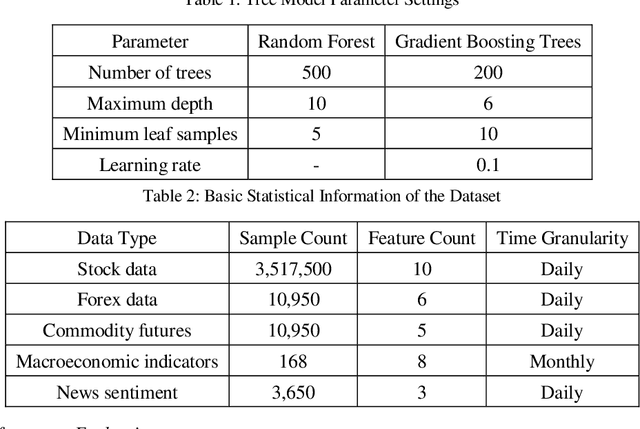
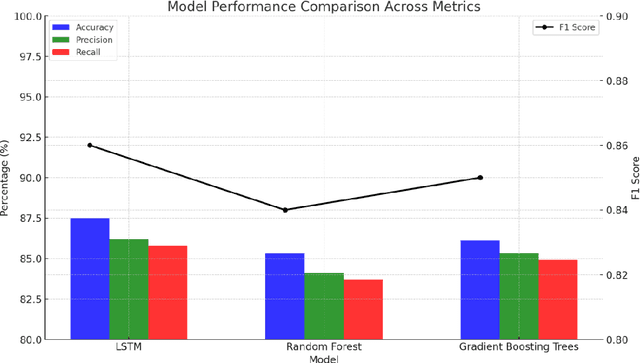
With the increasing complexity of financial markets and rapid growth in data volume, traditional risk monitoring methods no longer suffice for modern financial institutions. This paper designs and optimizes a risk monitoring system based on big data and machine learning. By constructing a four-layer architecture, it effectively integrates large-scale financial data and advanced machine learning algorithms. Key technologies employed in the system include Long Short-Term Memory (LSTM) networks, Random Forest, Gradient Boosting Trees, and real-time data processing platform Apache Flink, ensuring the real-time and accurate nature of risk monitoring. Research findings demonstrate that the system significantly enhances efficiency and accuracy in risk management, particularly excelling in identifying and warning against market crash risks.
Advanced AI Framework for Enhanced Detection and Assessment of Abdominal Trauma: Integrating 3D Segmentation with 2D CNN and RNN Models
Jul 23, 2024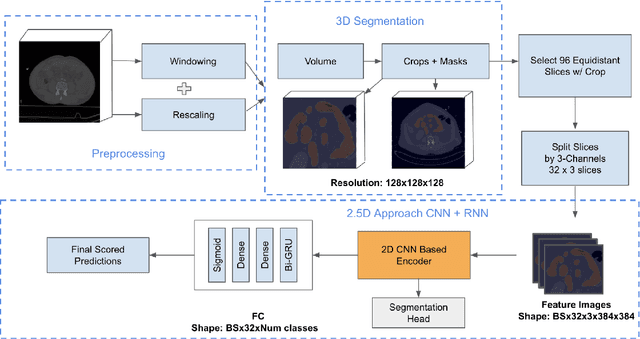
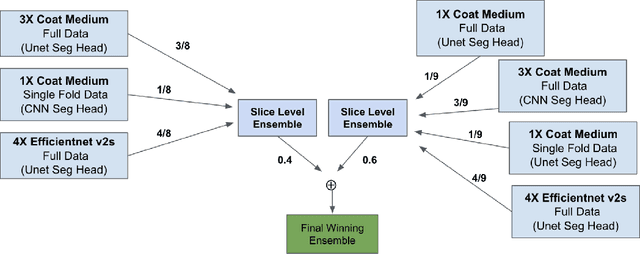
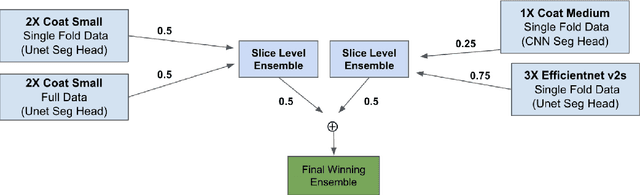

Trauma is a significant cause of mortality and disability, particularly among individuals under forty. Traditional diagnostic methods for traumatic injuries, such as X-rays, CT scans, and MRI, are often time-consuming and dependent on medical expertise, which can delay critical interventions. This study explores the application of artificial intelligence (AI) and machine learning (ML) to improve the speed and accuracy of abdominal trauma diagnosis. We developed an advanced AI-based model combining 3D segmentation, 2D Convolutional Neural Networks (CNN), and Recurrent Neural Networks (RNN) to enhance diagnostic performance. Our model processes abdominal CT scans to provide real-time, precise assessments, thereby improving clinical decision-making and patient outcomes. Comprehensive experiments demonstrated that our approach significantly outperforms traditional diagnostic methods, as evidenced by rigorous evaluation metrics. This research sets a new benchmark for automated trauma detection, leveraging the strengths of AI and ML to revolutionize trauma care.
Research on Image Super-Resolution Reconstruction Mechanism based on Convolutional Neural Network
Jul 18, 2024



Super-resolution reconstruction techniques entail the utilization of software algorithms to transform one or more sets of low-resolution images captured from the same scene into high-resolution images. In recent years, considerable advancement has been observed in the domain of single-image super-resolution algorithms, particularly those based on deep learning techniques. Nevertheless, the extraction of image features and nonlinear mapping methods in the reconstruction process remain challenging for existing algorithms. These issues result in the network architecture being unable to effectively utilize the diverse range of information at different levels. The loss of high-frequency details is significant, and the final reconstructed image features are overly smooth, with a lack of fine texture details. This negatively impacts the subjective visual quality of the image. The objective is to recover high-quality, high-resolution images from low-resolution images. In this work, an enhanced deep convolutional neural network model is employed, comprising multiple convolutional layers, each of which is configured with specific filters and activation functions to effectively capture the diverse features of the image. Furthermore, a residual learning strategy is employed to accelerate training and enhance the convergence of the network, while sub-pixel convolutional layers are utilized to refine the high-frequency details and textures of the image. The experimental analysis demonstrates the superior performance of the proposed model on multiple public datasets when compared with the traditional bicubic interpolation method and several other learning-based super-resolution methods. Furthermore, it proves the model's efficacy in maintaining image edges and textures.
Research on Autonomous Robots Navigation based on Reinforcement Learning
Jul 02, 2024Reinforcement learning continuously optimizes decision-making based on real-time feedback reward signals through continuous interaction with the environment, demonstrating strong adaptive and self-learning capabilities. In recent years, it has become one of the key methods to achieve autonomous navigation of robots. In this work, an autonomous robot navigation method based on reinforcement learning is introduced. We use the Deep Q Network (DQN) and Proximal Policy Optimization (PPO) models to optimize the path planning and decision-making process through the continuous interaction between the robot and the environment, and the reward signals with real-time feedback. By combining the Q-value function with the deep neural network, deep Q network can handle high-dimensional state space, so as to realize path planning in complex environments. Proximal policy optimization is a strategy gradient-based method, which enables robots to explore and utilize environmental information more efficiently by optimizing policy functions. These methods not only improve the robot's navigation ability in the unknown environment, but also enhance its adaptive and self-learning capabilities. Through multiple training and simulation experiments, we have verified the effectiveness and robustness of these models in various complex scenarios.
Research on target detection method of distracted driving behavior based on improved YOLOv8
Jul 02, 2024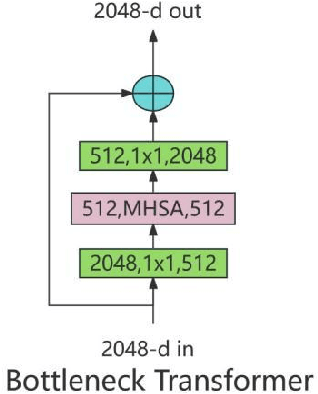
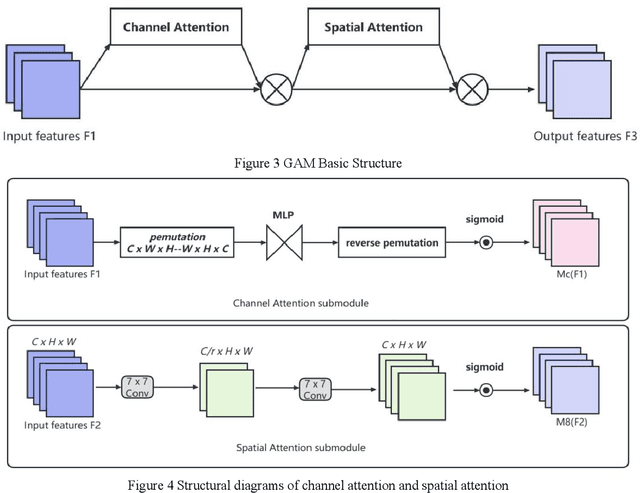
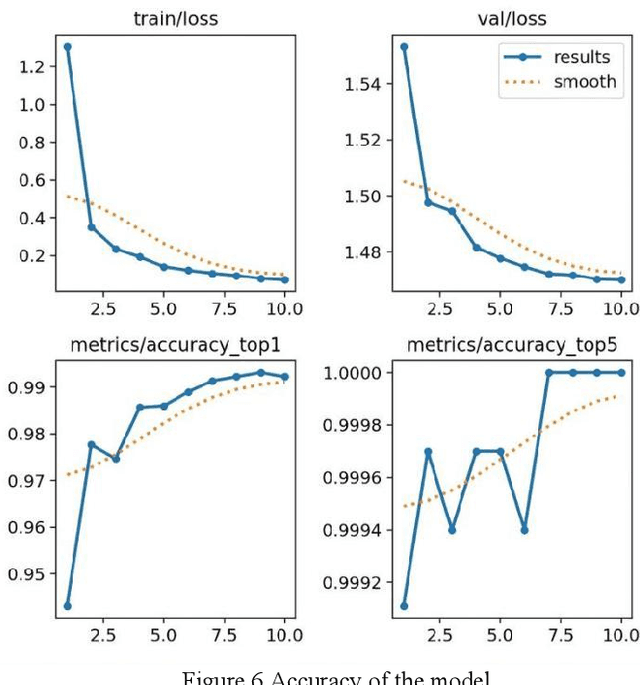
With the development of deep learning technology, the detection and classification of distracted driving behaviour requires higher accuracy. Existing deep learning-based methods are computationally intensive and parameter redundant, limiting the efficiency and accuracy in practical applications. To solve this problem, this study proposes an improved YOLOv8 detection method based on the original YOLOv8 model by integrating the BoTNet module, GAM attention mechanism and EIoU loss function. By optimising the feature extraction and multi-scale feature fusion strategies, the training and inference processes are simplified, and the detection accuracy and efficiency are significantly improved. Experimental results show that the improved model performs well in both detection speed and accuracy, with an accuracy rate of 99.4%, and the model is smaller and easy to deploy, which is able to identify and classify distracted driving behaviours in real time, provide timely warnings, and enhance driving safety.