 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEVLP: Noise-Robust Framework for Efficient Vision-Language Pre-training
Sep 15, 2024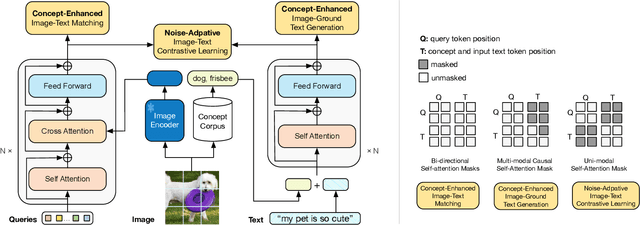
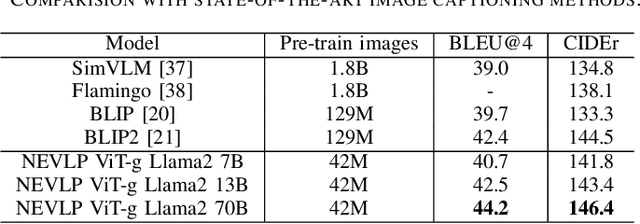
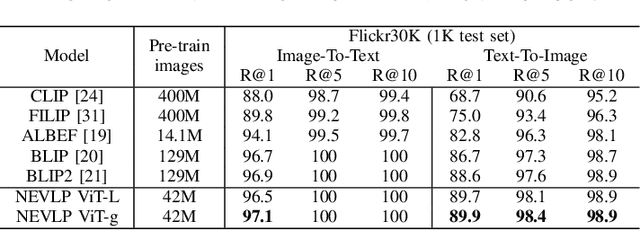
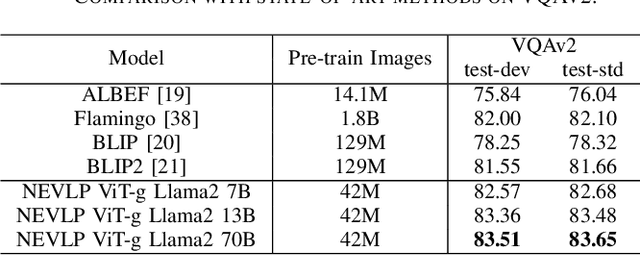
The success of Vision Language Models (VLMs) on various vision-language tasks heavily relies on pre-training with large scale web-crawled datasets. However, the noisy and incomplete nature of web data makes dataset scale crucial for performance, rendering end-to-end training increasingly prohibitive. In this paper, we propose NEVLP, a noise-robust framework for efficient vision-language pre-training that requires less pre-training data. Specifically, we bridge the modality gap between a frozen image encoder and a large language model with a transformer and introduce two innovative learning strategies: noise-adaptive learning and concept-enhanced learning to mitigate the impact of noise. In noise-adaptive learning, we estimate the noise probability of each image-text pair based on the transformer's memorization effect and employ noise-adaptive regularization on image-text contrastive learning to condition cross-modal alignment. In concept-enhanced learning, we enrich incomplete text by incorporating visual concepts (objects in the image) to provide prior information about existing objects for image-text matching and image-grounded text generation, thereby mitigating text incompletion. Our framework effectively utilizes noisy web data and achieves state-of-the-art performance with less pre-training data across a wide range of vision-language tasks, including image-text retrieval, image captioning, and visual question answering.
A Multiscale Gradient Fusion Method for Edge Detection in Color Images Utilizing the CBM3D Filter
Aug 26, 2024


In this paper, a color edge detection strategy based on collaborative filtering combined with multiscale gradient fusion is proposed. The block-matching and 3D (BM3D) filter are used to enhance the sparse representation in the transform domain and achieve the effect of denoising, whereas the multiscale gradient fusion makes up for the defect of loss of details in single-scale edge detection and improves the edge detection resolution and quality. First, the RGB images in the dataset are converted to XYZ color space images through mathematical operations. Second, the colored block-matching and 3D (CBM3D) filter are used on the sparse images and to remove noise interference. Then, the vector gradients of the color image and the anisotropic Gaussian directional derivative of the two scale parameters are calculated and averaged pixel-by-pixel to obtain a new edge strength map. Finally, the edge features are enhanced by image normalization and non-maximum suppression technology, and on that basis, the edge contour is obtained by double threshold selection and a new morphological refinement method. Through an experimental analysis of the edge detection dataset, the method proposed has good noise robustness and high edge quality, which is better than the Color Sobel, Color Canny, SE and Color AGDD as shown by the PR curve, AUC, PSNR, MSE, and FOM indicators.
Deep Learning in Medical Image Classification from MRI-based Brain Tumor Images
Aug 01, 2024



Brain tumors are among the deadliest diseases in the world. Magnetic Resonance Imaging (MRI) is one of the most effective ways to detect brain tumors. Accurate detection of brain tumors based on MRI scans is critical, as it can potentially save many lives and facilitate better decision-making at the early stages of the disease. Within our paper, four different types of MRI-based images have been collected from the database: glioma tumor, no tumor, pituitary tumor, and meningioma tumor. Our study focuses on making predictions for brain tumor classification. Five models, including four pre-trained models (MobileNet, EfficientNet-B0, ResNet-18, and VGG16) and one new model, MobileNet-BT, have been proposed for this study.
Predicting Stock Prices with FinBERT-LSTM: Integrating News Sentiment Analysis
Jul 23, 2024



The stock market's ascent typically mirrors the flourishing state of the economy, whereas its decline is often an indicator of an economic downturn. Therefore, for a long time, significant correlation elements for predicting trends in financial stock markets have been widely discussed, and people are becoming increasingly interested in the task of financial text mining. The inherent instability of stock prices makes them acutely responsive to fluctuations within the financial markets. In this article, we use deep learning networks, based on the history of stock prices and articles of financial, business, technical news that introduce market information to predict stock prices. We illustrate the enhancement of predictive precision by integrating weighted news categories into the forecasting model. We developed a pre-trained NLP model known as FinBERT, designed to discern the sentiments within financial texts. Subsequently, we advanced this model by incorporating the sophisticated Long Short Term Memory (LSTM) architecture, thus constructing the innovative FinBERT-LSTM model. This model utilizes news categories related to the stock market structure hierarchy, namely market, industry, and stock related news categories, combined with the stock market's stock price situation in the previous week for prediction. We selected NASDAQ-100 index stock data and trained the model on Benzinga news articles, and utilized Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), and Accuracy as the key metrics for the assessment and comparative analysis of the model's performance. The results indicate that FinBERT-LSTM performs the best, followed by LSTM, and DNN model ranks third in terms of effectiveness.
Research on Image Super-Resolution Reconstruction Mechanism based on Convolutional Neural Network
Jul 18, 2024



Super-resolution reconstruction techniques entail the utilization of software algorithms to transform one or more sets of low-resolution images captured from the same scene into high-resolution images. In recent years, considerable advancement has been observed in the domain of single-image super-resolution algorithms, particularly those based on deep learning techniques. Nevertheless, the extraction of image features and nonlinear mapping methods in the reconstruction process remain challenging for existing algorithms. These issues result in the network architecture being unable to effectively utilize the diverse range of information at different levels. The loss of high-frequency details is significant, and the final reconstructed image features are overly smooth, with a lack of fine texture details. This negatively impacts the subjective visual quality of the image. The objective is to recover high-quality, high-resolution images from low-resolution images. In this work, an enhanced deep convolutional neural network model is employed, comprising multiple convolutional layers, each of which is configured with specific filters and activation functions to effectively capture the diverse features of the image. Furthermore, a residual learning strategy is employed to accelerate training and enhance the convergence of the network, while sub-pixel convolutional layers are utilized to refine the high-frequency details and textures of the image. The experimental analysis demonstrates the superior performance of the proposed model on multiple public datasets when compared with the traditional bicubic interpolation method and several other learning-based super-resolution methods. Furthermore, it proves the model's efficacy in maintaining image edges and textures.
Transforming Movie Recommendations with Advanced Machine Learning: A Study of NMF, SVD,and K-Means Clustering
Jul 12, 2024


This study develops a robust movie recommendation system using various machine learning techniques, including Non- Negative Matrix Factorization (NMF), Truncated Singular Value Decomposition (SVD), and K-Means clustering. The primary objective is to enhance user experience by providing personalized movie recommendations. The research encompasses data preprocessing, model training, and evaluation, highlighting the efficacy of the employed methods. Results indicate that the proposed system achieves high accuracy and relevance in recommendations, making significant contributions to the field of recommendations systems.
Research on Autonomous Robots Navigation based on Reinforcement Learning
Jul 02, 2024Reinforcement learning continuously optimizes decision-making based on real-time feedback reward signals through continuous interaction with the environment, demonstrating strong adaptive and self-learning capabilities. In recent years, it has become one of the key methods to achieve autonomous navigation of robots. In this work, an autonomous robot navigation method based on reinforcement learning is introduced. We use the Deep Q Network (DQN) and Proximal Policy Optimization (PPO) models to optimize the path planning and decision-making process through the continuous interaction between the robot and the environment, and the reward signals with real-time feedback. By combining the Q-value function with the deep neural network, deep Q network can handle high-dimensional state space, so as to realize path planning in complex environments. Proximal policy optimization is a strategy gradient-based method, which enables robots to explore and utilize environmental information more efficiently by optimizing policy functions. These methods not only improve the robot's navigation ability in the unknown environment, but also enhance its adaptive and self-learning capabilities. Through multiple training and simulation experiments, we have verified the effectiveness and robustness of these models in various complex scenarios.
COMIC: An Unsupervised Change Detection Method for Heterogeneous Remote Sensing Images Based on Copula Mixtures and Cycle-Consistent Adversarial Networks
Apr 03, 2023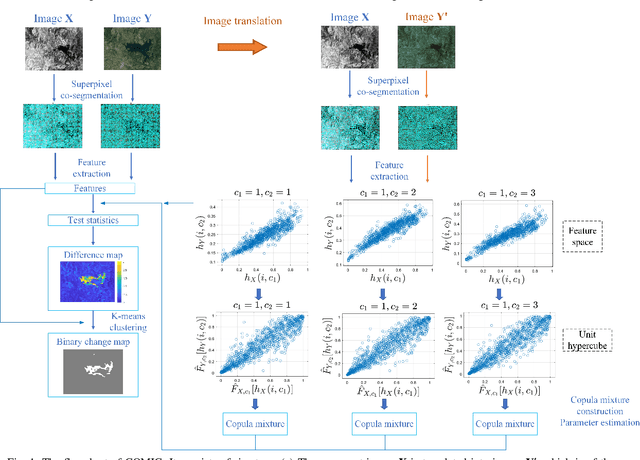
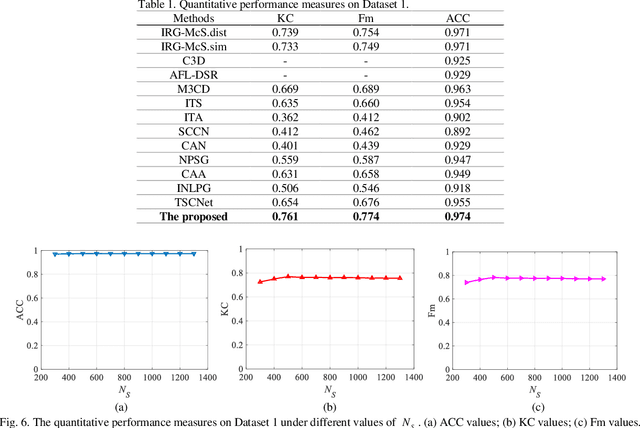
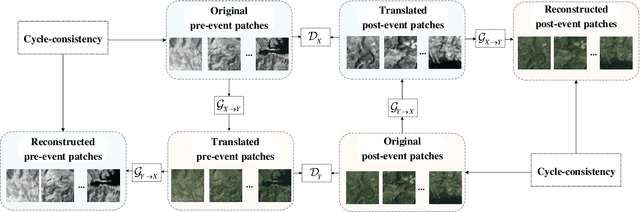
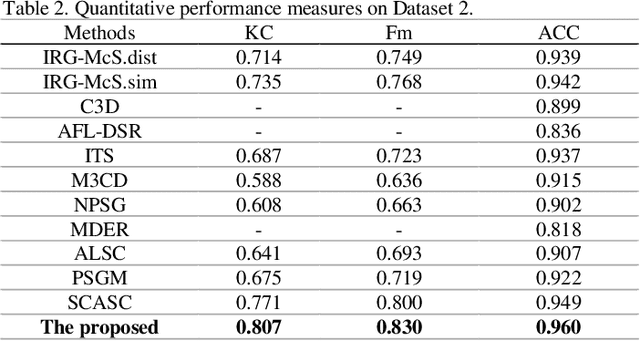
In this paper, we consider the problem of change detection (CD) with two heterogeneous remote sensing (RS) images. For this problem, an unsupervised change detection method has been proposed recently based on the image translation technique of Cycle-Consistent Adversarial Networks (CycleGANs), where one image is translated from its original modality to the modality of the other image so that the difference map can be obtained by performing arithmetical subtraction. However, the difference map derived from subtraction is susceptible to image translation errors, in which case the changed area and the unchanged area are less distinguishable. To overcome the above shortcoming, we propose a new unsupervised copula mixture and CycleGAN-based CD method (COMIC), which combines the advantages of copula mixtures on statistical modeling and the advantages of CycleGANs on data mining. In COMIC, the pre-event image is first translated from its original modality to the post-event image modality. After that, by constructing a copula mixture, the joint distribution of the features from the heterogeneous images can be learnt according to quantitive analysis of the dependence structure based on the translated image and the original pre-event image, which are of the same modality and contain totally the same objects. Then, we model the CD problem as a binary hypothesis testing problem and derive its test statistics based on the constructed copula mixture. Finally, the difference map can be obtained from the test statistics and the binary change map (BCM) is generated by K-means clustering. We perform experiments on real RS datasets, which demonstrate the superiority of COMIC over the state-of-the-art methods.