 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Analysis of Large Language Models for Context-Aware Code Completion using SAFIM Framework
Feb 21, 2025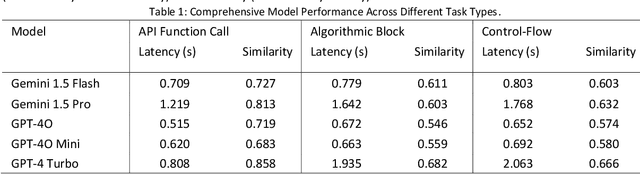
The advent of Large Language Models (LLMs) has revolutionized code completion, transforming it into a more intelligent and context-aware feature in modern integrated development environments. These advancements have significantly enhanced developers' ability to write efficient and error-free code. This study evaluates the performance of several chat-based LLMs, including Gemini 1.5 Flash, Gemini 1.5 Pro, GPT-4o, GPT-4o-mini, and GPT-4 Turbo, using the Syntax-Aware Fill-in-the-Middle (SAFIM) dataset. This benchmark is specifically designed to assess models' capabilities in syntax-sensitive code generation. Performance metrics, such as cosine similarity with ground-truth completions and latency, were employed to measure both accuracy and efficiency. The findings reveal substantial differences in the models' code completion abilities, offering valuable insights into their respective strengths and weaknesses. This work provides a comparative analysis that underscores the trade-offs between accuracy and speed, establishing a benchmark for future advancements in LLM-based code completion.
Deep Semantic Graph Learning via LLM based Node Enhancement
Feb 11, 2025Graph learning has attracted significant attention due to its widespread real-world applications. Current mainstream approaches rely on text node features and obtain initial node embeddings through shallow embedding learning using GNNs, which shows limitations in capturing deep textual semantics. Recent advances in Large Language Models (LLMs) have demonstrated superior capabilities in understanding text semantics, transforming traditional text feature processing. This paper proposes a novel framework that combines Graph Transformer architecture with LLM-enhanced node features. Specifically, we leverage LLMs to generate rich semantic representations of text nodes, which are then processed by a multi-head self-attention mechanism in the Graph Transformer to capture both local and global graph structural information. Our model utilizes the Transformer's attention mechanism to dynamically aggregate neighborhood information while preserving the semantic richness provided by LLM embeddings. Experimental results demonstrate that the LLM-enhanced node features significantly improve the performance of graph learning models on node classification tasks. This approach shows promising results across multiple graph learning tasks, offering a practical direction for combining graph networks with language models.
Zero-Shot End-to-End Relation Extraction in Chinese: A Comparative Study of Gemini, LLaMA and ChatGPT
Feb 08, 2025



This study investigates the performance of various large language models (LLMs) on zero-shot end-to-end relation extraction (RE) in Chinese, a task that integrates entity recognition and relation extraction without requiring annotated data. While LLMs show promise for RE, most prior work focuses on English or assumes pre-annotated entities, leaving their effectiveness in Chinese RE largely unexplored. To bridge this gap, we evaluate ChatGPT, Gemini, and LLaMA based on accuracy, efficiency, and adaptability. ChatGPT demonstrates the highest overall performance, balancing precision and recall, while Gemini achieves the fastest inference speed, making it suitable for real-time applications. LLaMA underperforms in both accuracy and latency, highlighting the need for further adaptation. Our findings provide insights into the strengths and limitations of LLMs for zero-shot Chinese RE, shedding light on trade-offs between accuracy and efficiency. This study serves as a foundation for future research aimed at improving LLM adaptability to complex linguistic tasks in Chinese NLP.
AltGen: AI-Driven Alt Text Generation for Enhancing EPUB Accessibility
Dec 30, 2024



Digital accessibility is a cornerstone of inclusive content delivery, yet many EPUB files fail to meet fundamental accessibility standards, particularly in providing descriptive alt text for images. Alt text plays a critical role in enabling visually impaired users to understand visual content through assistive technologies. However, generating high-quality alt text at scale is a resource-intensive process, creating significant challenges for organizations aiming to ensure accessibility compliance. This paper introduces AltGen, a novel AI-driven pipeline designed to automate the generation of alt text for images in EPUB files. By integrating state-of-the-art generative models, including advanced transformer-based architectures, AltGen achieves contextually relevant and linguistically coherent alt text descriptions. The pipeline encompasses multiple stages, starting with data preprocessing to extract and prepare relevant content, followed by visual analysis using computer vision models such as CLIP and ViT. The extracted visual features are enriched with contextual information from surrounding text, enabling the fine-tuned language models to generate descriptive and accurate alt text. Validation of the generated output employs both quantitative metrics, such as cosine similarity and BLEU scores, and qualitative feedback from visually impaired users. Experimental results demonstrate the efficacy of AltGen across diverse datasets, achieving a 97.5% reduction in accessibility errors and high scores in similarity and linguistic fidelity metrics. User studies highlight the practical impact of AltGen, with participants reporting significant improvements in document usability and comprehension. Furthermore, comparative analyses reveal that AltGen outperforms existing approaches in terms of accuracy, relevance, and scalability.
Comparative Analysis of Listwise Reranking with Large Language Models in Limited-Resource Language Contexts
Dec 28, 2024Large Language Models (LLMs) have demonstrated significant effectiveness across various NLP tasks, including text ranking. This study assesses the performance of large language models (LLMs) in listwise reranking for limited-resource African languages. We compare proprietary models RankGPT3.5, Rank4o-mini, RankGPTo1-mini and RankClaude-sonnet in cross-lingual contexts. Results indicate that these LLMs significantly outperform traditional baseline methods such as BM25-DT in most evaluation metrics, particularly in nDCG@10 and MRR@100. These findings highlight the potential of LLMs in enhancing reranking tasks for low-resource languages and offer insights into cost-effective solutions.
Robustness of Large Language Models Against Adversarial Attacks
Dec 22, 2024



The increasing deployment of Large Language Models (LLMs) in various applications necessitates a rigorous evaluation of their robustness against adversarial attacks. In this paper, we present a comprehensive study on the robustness of GPT LLM family. We employ two distinct evaluation methods to assess their resilience. The first method introduce character-level text attack in input prompts, testing the models on three sentiment classification datasets: StanfordNLP/IMDB, Yelp Reviews, and SST-2. The second method involves using jailbreak prompts to challenge the safety mechanisms of the LLMs. Our experiments reveal significant variations in the robustness of these models, demonstrating their varying degrees of vulnerability to both character-level and semantic-level adversarial attacks. These findings underscore the necessity for improved adversarial training and enhanced safety mechanisms to bolster the robustness of LLMs.
NEVLP: Noise-Robust Framework for Efficient Vision-Language Pre-training
Sep 15, 2024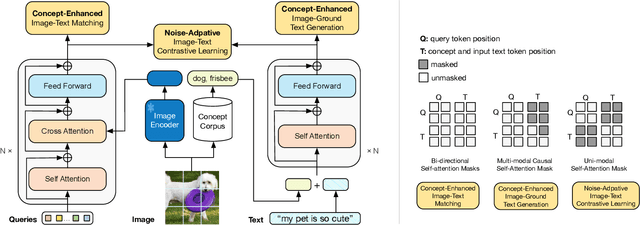
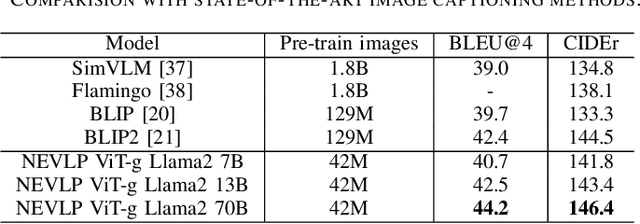
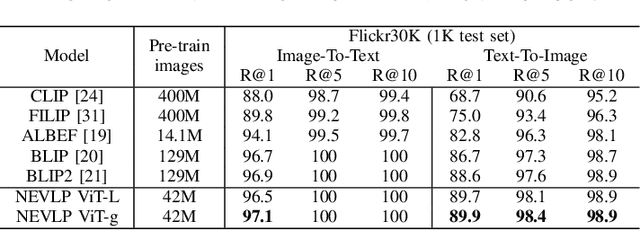
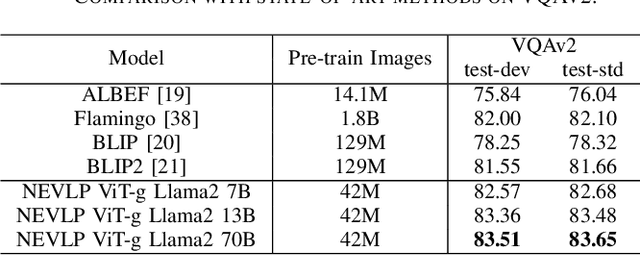
The success of Vision Language Models (VLMs) on various vision-language tasks heavily relies on pre-training with large scale web-crawled datasets. However, the noisy and incomplete nature of web data makes dataset scale crucial for performance, rendering end-to-end training increasingly prohibitive. In this paper, we propose NEVLP, a noise-robust framework for efficient vision-language pre-training that requires less pre-training data. Specifically, we bridge the modality gap between a frozen image encoder and a large language model with a transformer and introduce two innovative learning strategies: noise-adaptive learning and concept-enhanced learning to mitigate the impact of noise. In noise-adaptive learning, we estimate the noise probability of each image-text pair based on the transformer's memorization effect and employ noise-adaptive regularization on image-text contrastive learning to condition cross-modal alignment. In concept-enhanced learning, we enrich incomplete text by incorporating visual concepts (objects in the image) to provide prior information about existing objects for image-text matching and image-grounded text generation, thereby mitigating text incompletion. Our framework effectively utilizes noisy web data and achieves state-of-the-art performance with less pre-training data across a wide range of vision-language tasks, including image-text retrieval, image captioning, and visual question answering.
A Multiscale Gradient Fusion Method for Edge Detection in Color Images Utilizing the CBM3D Filter
Aug 26, 2024


In this paper, a color edge detection strategy based on collaborative filtering combined with multiscale gradient fusion is proposed. The block-matching and 3D (BM3D) filter are used to enhance the sparse representation in the transform domain and achieve the effect of denoising, whereas the multiscale gradient fusion makes up for the defect of loss of details in single-scale edge detection and improves the edge detection resolution and quality. First, the RGB images in the dataset are converted to XYZ color space images through mathematical operations. Second, the colored block-matching and 3D (CBM3D) filter are used on the sparse images and to remove noise interference. Then, the vector gradients of the color image and the anisotropic Gaussian directional derivative of the two scale parameters are calculated and averaged pixel-by-pixel to obtain a new edge strength map. Finally, the edge features are enhanced by image normalization and non-maximum suppression technology, and on that basis, the edge contour is obtained by double threshold selection and a new morphological refinement method. Through an experimental analysis of the edge detection dataset, the method proposed has good noise robustness and high edge quality, which is better than the Color Sobel, Color Canny, SE and Color AGDD as shown by the PR curve, AUC, PSNR, MSE, and FOM indicators.
The FacT: Taming Latent Factor Models for Explainability with Factorization Trees
Jun 03, 2019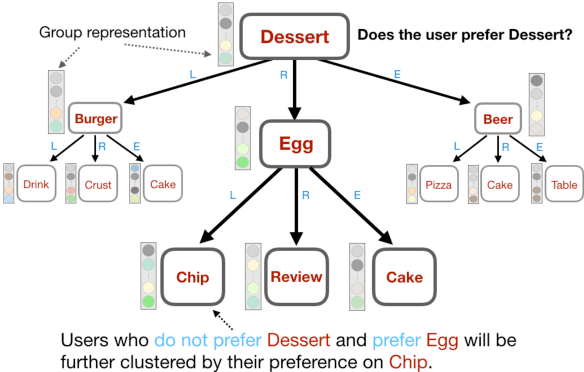

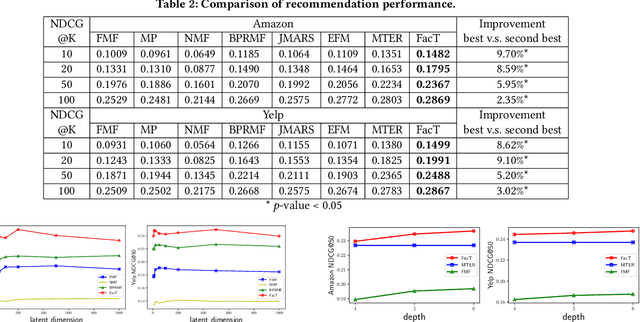
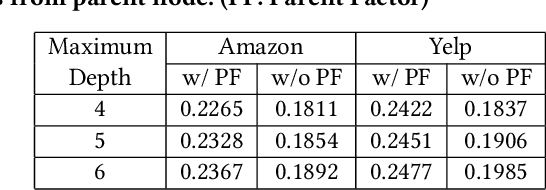
Latent factor models have achieved great success in personalized recommendations, but they are also notoriously difficult to explain. In this work, we integrate regression trees to guide the learning of latent factor models for recommendation, and use the learnt tree structure to explain the resulting latent factors. Specifically, we build regression trees on users and items respectively with user-generated reviews, and associate a latent profile to each node on the trees to represent users and items. With the growth of regression tree, the latent factors are gradually refined under the regularization imposed by the tree structure. As a result, we are able to track the creation of latent profiles by looking into the path of each factor on regression trees, which thus serves as an explanation for the resulting recommendations. Extensive experiments on two large collections of Amazon and Yelp reviews demonstrate the advantage of our model over several competitive baseline algorithms. Besides, our extensive user study also confirms the practical value of explainable recommendations generated by our model.