 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Analysis of Large Language Models for Context-Aware Code Completion using SAFIM Framework
Paper and Code
Feb 21, 2025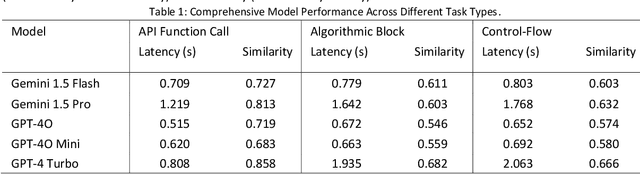
The advent of Large Language Models (LLMs) has revolutionized code completion, transforming it into a more intelligent and context-aware feature in modern integrated development environments. These advancements have significantly enhanced developers' ability to write efficient and error-free code. This study evaluates the performance of several chat-based LLMs, including Gemini 1.5 Flash, Gemini 1.5 Pro, GPT-4o, GPT-4o-mini, and GPT-4 Turbo, using the Syntax-Aware Fill-in-the-Middle (SAFIM) dataset. This benchmark is specifically designed to assess models' capabilities in syntax-sensitive code generation. Performance metrics, such as cosine similarity with ground-truth completions and latency, were employed to measure both accuracy and efficiency. The findings reveal substantial differences in the models' code completion abilities, offering valuable insights into their respective strengths and weaknesses. This work provides a comparative analysis that underscores the trade-offs between accuracy and speed, establishing a benchmark for future advancements in LLM-based code completion.