 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDep-Search: Learning Dependency-Aware Reasoning Traces with Persistent Memory
Jan 26, 2026Large Language Models (LLMs) have demonstrated remarkable capabilities in complex reasoning tasks, particularly when augmented with search mechanisms that enable systematic exploration of external knowledge bases. The field has evolved from traditional retrieval-augmented generation (RAG) frameworks to more sophisticated search-based frameworks that orchestrate multi-step reasoning through explicit search strategies. However, existing search frameworks still rely heavily on implicit natural language reasoning to determine search strategies and how to leverage retrieved information across reasoning steps. This reliance on implicit reasoning creates fundamental challenges for managing dependencies between sub-questions, efficiently reusing previously retrieved knowledge, and learning optimal search strategies through reinforcement learning. To address these limitations, we propose Dep-Search, a dependency-aware search framework that advances beyond existing search frameworks by integrating structured reasoning, retrieval, and persistent memory through GRPO. Dep-Search introduces explicit control mechanisms that enable the model to decompose questions with dependency relationships, retrieve information when needed, access previously stored knowledge from memory, and summarize long reasoning contexts into reusable memory entries. Through extensive experiments on seven diverse question answering datasets, we demonstrate that Dep-Search significantly enhances LLMs' ability to tackle complex multi-hop reasoning tasks, achieving substantial improvements over strong baselines across different model scales.
Comparative Analysis of Large Language Models for Context-Aware Code Completion using SAFIM Framework
Feb 21, 2025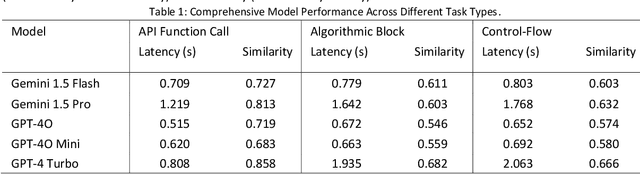
The advent of Large Language Models (LLMs) has revolutionized code completion, transforming it into a more intelligent and context-aware feature in modern integrated development environments. These advancements have significantly enhanced developers' ability to write efficient and error-free code. This study evaluates the performance of several chat-based LLMs, including Gemini 1.5 Flash, Gemini 1.5 Pro, GPT-4o, GPT-4o-mini, and GPT-4 Turbo, using the Syntax-Aware Fill-in-the-Middle (SAFIM) dataset. This benchmark is specifically designed to assess models' capabilities in syntax-sensitive code generation. Performance metrics, such as cosine similarity with ground-truth completions and latency, were employed to measure both accuracy and efficiency. The findings reveal substantial differences in the models' code completion abilities, offering valuable insights into their respective strengths and weaknesses. This work provides a comparative analysis that underscores the trade-offs between accuracy and speed, establishing a benchmark for future advancements in LLM-based code completion.
Deep Semantic Graph Learning via LLM based Node Enhancement
Feb 11, 2025Graph learning has attracted significant attention due to its widespread real-world applications. Current mainstream approaches rely on text node features and obtain initial node embeddings through shallow embedding learning using GNNs, which shows limitations in capturing deep textual semantics. Recent advances in Large Language Models (LLMs) have demonstrated superior capabilities in understanding text semantics, transforming traditional text feature processing. This paper proposes a novel framework that combines Graph Transformer architecture with LLM-enhanced node features. Specifically, we leverage LLMs to generate rich semantic representations of text nodes, which are then processed by a multi-head self-attention mechanism in the Graph Transformer to capture both local and global graph structural information. Our model utilizes the Transformer's attention mechanism to dynamically aggregate neighborhood information while preserving the semantic richness provided by LLM embeddings. Experimental results demonstrate that the LLM-enhanced node features significantly improve the performance of graph learning models on node classification tasks. This approach shows promising results across multiple graph learning tasks, offering a practical direction for combining graph networks with language models.
Zero-Shot End-to-End Relation Extraction in Chinese: A Comparative Study of Gemini, LLaMA and ChatGPT
Feb 08, 2025



This study investigates the performance of various large language models (LLMs) on zero-shot end-to-end relation extraction (RE) in Chinese, a task that integrates entity recognition and relation extraction without requiring annotated data. While LLMs show promise for RE, most prior work focuses on English or assumes pre-annotated entities, leaving their effectiveness in Chinese RE largely unexplored. To bridge this gap, we evaluate ChatGPT, Gemini, and LLaMA based on accuracy, efficiency, and adaptability. ChatGPT demonstrates the highest overall performance, balancing precision and recall, while Gemini achieves the fastest inference speed, making it suitable for real-time applications. LLaMA underperforms in both accuracy and latency, highlighting the need for further adaptation. Our findings provide insights into the strengths and limitations of LLMs for zero-shot Chinese RE, shedding light on trade-offs between accuracy and efficiency. This study serves as a foundation for future research aimed at improving LLM adaptability to complex linguistic tasks in Chinese NLP.
AltGen: AI-Driven Alt Text Generation for Enhancing EPUB Accessibility
Dec 30, 2024



Digital accessibility is a cornerstone of inclusive content delivery, yet many EPUB files fail to meet fundamental accessibility standards, particularly in providing descriptive alt text for images. Alt text plays a critical role in enabling visually impaired users to understand visual content through assistive technologies. However, generating high-quality alt text at scale is a resource-intensive process, creating significant challenges for organizations aiming to ensure accessibility compliance. This paper introduces AltGen, a novel AI-driven pipeline designed to automate the generation of alt text for images in EPUB files. By integrating state-of-the-art generative models, including advanced transformer-based architectures, AltGen achieves contextually relevant and linguistically coherent alt text descriptions. The pipeline encompasses multiple stages, starting with data preprocessing to extract and prepare relevant content, followed by visual analysis using computer vision models such as CLIP and ViT. The extracted visual features are enriched with contextual information from surrounding text, enabling the fine-tuned language models to generate descriptive and accurate alt text. Validation of the generated output employs both quantitative metrics, such as cosine similarity and BLEU scores, and qualitative feedback from visually impaired users. Experimental results demonstrate the efficacy of AltGen across diverse datasets, achieving a 97.5% reduction in accessibility errors and high scores in similarity and linguistic fidelity metrics. User studies highlight the practical impact of AltGen, with participants reporting significant improvements in document usability and comprehension. Furthermore, comparative analyses reveal that AltGen outperforms existing approaches in terms of accuracy, relevance, and scalability.
Comparative Analysis of Listwise Reranking with Large Language Models in Limited-Resource Language Contexts
Dec 28, 2024Large Language Models (LLMs) have demonstrated significant effectiveness across various NLP tasks, including text ranking. This study assesses the performance of large language models (LLMs) in listwise reranking for limited-resource African languages. We compare proprietary models RankGPT3.5, Rank4o-mini, RankGPTo1-mini and RankClaude-sonnet in cross-lingual contexts. Results indicate that these LLMs significantly outperform traditional baseline methods such as BM25-DT in most evaluation metrics, particularly in nDCG@10 and MRR@100. These findings highlight the potential of LLMs in enhancing reranking tasks for low-resource languages and offer insights into cost-effective solutions.
Robustness of Large Language Models Against Adversarial Attacks
Dec 22, 2024



The increasing deployment of Large Language Models (LLMs) in various applications necessitates a rigorous evaluation of their robustness against adversarial attacks. In this paper, we present a comprehensive study on the robustness of GPT LLM family. We employ two distinct evaluation methods to assess their resilience. The first method introduce character-level text attack in input prompts, testing the models on three sentiment classification datasets: StanfordNLP/IMDB, Yelp Reviews, and SST-2. The second method involves using jailbreak prompts to challenge the safety mechanisms of the LLMs. Our experiments reveal significant variations in the robustness of these models, demonstrating their varying degrees of vulnerability to both character-level and semantic-level adversarial attacks. These findings underscore the necessity for improved adversarial training and enhanced safety mechanisms to bolster the robustness of LLMs.
Financial Sentiment Analysis on News and Reports Using Large Language Models and FinBERT
Oct 02, 2024
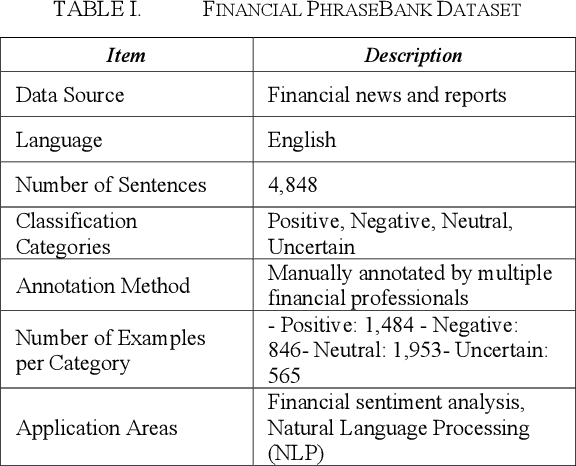
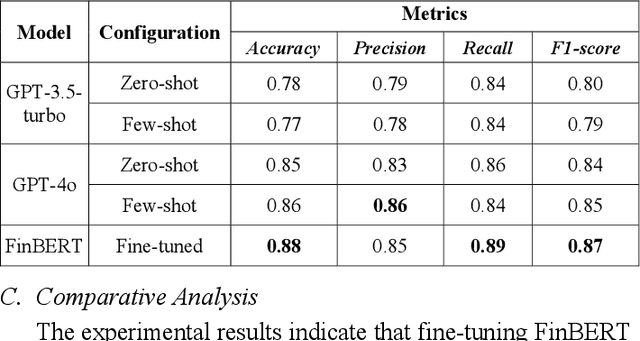
Financial sentiment analysis (FSA) is crucial for evaluating market sentiment and making well-informed financial decisions. The advent of large language models (LLMs) such as BERT and its financial variant, FinBERT, has notably enhanced sentiment analysis capabilities. This paper investigates the application of LLMs and FinBERT for FSA, comparing their performance on news articles, financial reports and company announcements. The study emphasizes the advantages of prompt engineering with zero-shot and few-shot strategy to improve sentiment classification accuracy. Experimental results indicate that GPT-4o, with few-shot examples of financial texts, can be as competent as a well fine-tuned FinBERT in this specialized field.
Bridging Context Gaps: Leveraging Coreference Resolution for Long Contextual Understanding
Oct 02, 2024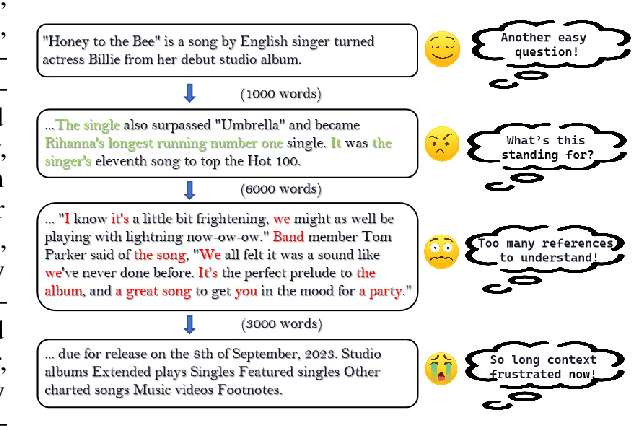
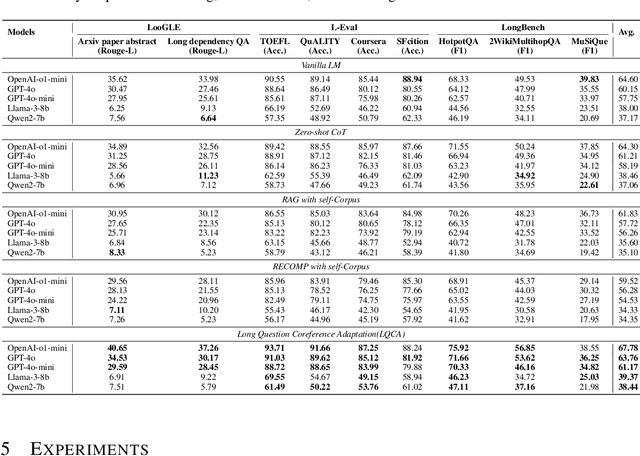
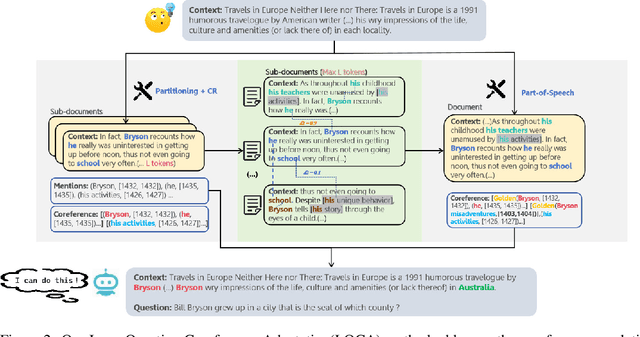
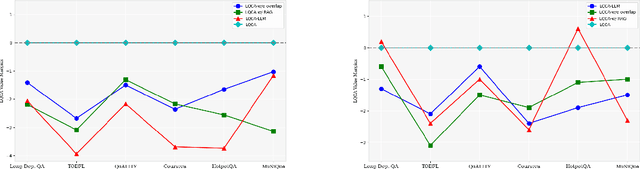
Large language models (LLMs) have shown remarkable capabilities in natural language processing; however, they still face difficulties when tasked with understanding lengthy contexts and executing effective question answering. These challenges often arise due to the complexity and ambiguity present in longer texts. To enhance the performance of LLMs in such scenarios, we introduce the Long Question Coreference Adaptation (LQCA) method. This innovative framework focuses on coreference resolution tailored to long contexts, allowing the model to identify and manage references effectively. The LQCA method encompasses four key steps: resolving coreferences within sub-documents, computing the distances between mentions, defining a representative mention for coreference, and answering questions through mention replacement. By processing information systematically, the framework provides easier-to-handle partitions for LLMs, promoting better understanding. Experimental evaluations on a range of LLMs and datasets have yielded positive results, with a notable improvements on OpenAI-o1-mini and GPT-4o models, highlighting the effectiveness of leveraging coreference resolution to bridge context gaps in question answering.
DELTA: Dual Consistency Delving with Topological Uncertainty for Active Graph Domain Adaptation
Sep 13, 2024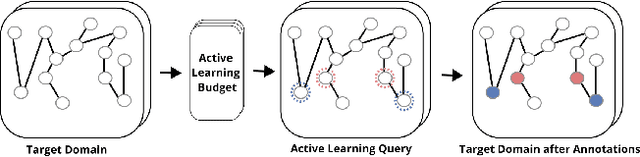
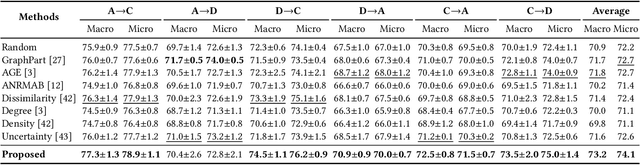
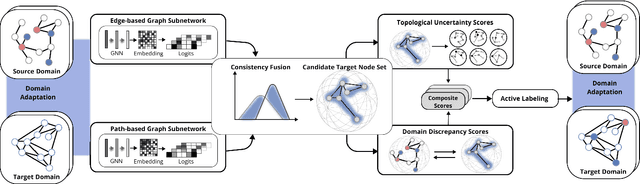

Graph domain adaptation has recently enabled knowledge transfer across different graphs. However, without the semantic information on target graphs, the performance on target graphs is still far from satisfactory. To address the issue, we study the problem of active graph domain adaptation, which selects a small quantitative of informative nodes on the target graph for extra annotation. This problem is highly challenging due to the complicated topological relationships and the distribution discrepancy across graphs. In this paper, we propose a novel approach named Dual Consistency Delving with Topological Uncertainty (DELTA) for active graph domain adaptation. Our DELTA consists of an edge-oriented graph subnetwork and a path-oriented graph subnetwork, which can explore topological semantics from complementary perspectives. In particular, our edge-oriented graph subnetwork utilizes the message passing mechanism to learn neighborhood information, while our path-oriented graph subnetwork explores high-order relationships from substructures. To jointly learn from two subnetworks, we roughly select informative candidate nodes with the consideration of consistency across two subnetworks. Then, we aggregate local semantics from its K-hop subgraph based on node degrees for topological uncertainty estimation. To overcome potential distribution shifts, we compare target nodes and their corresponding source nodes for discrepancy scores as an additional component for fine selection. Extensive experiments on benchmark datasets demonstrate that DELTA outperforms various state-of-the-art approaches.