 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDep-Search: Learning Dependency-Aware Reasoning Traces with Persistent Memory
Jan 26, 2026Large Language Models (LLMs) have demonstrated remarkable capabilities in complex reasoning tasks, particularly when augmented with search mechanisms that enable systematic exploration of external knowledge bases. The field has evolved from traditional retrieval-augmented generation (RAG) frameworks to more sophisticated search-based frameworks that orchestrate multi-step reasoning through explicit search strategies. However, existing search frameworks still rely heavily on implicit natural language reasoning to determine search strategies and how to leverage retrieved information across reasoning steps. This reliance on implicit reasoning creates fundamental challenges for managing dependencies between sub-questions, efficiently reusing previously retrieved knowledge, and learning optimal search strategies through reinforcement learning. To address these limitations, we propose Dep-Search, a dependency-aware search framework that advances beyond existing search frameworks by integrating structured reasoning, retrieval, and persistent memory through GRPO. Dep-Search introduces explicit control mechanisms that enable the model to decompose questions with dependency relationships, retrieve information when needed, access previously stored knowledge from memory, and summarize long reasoning contexts into reusable memory entries. Through extensive experiments on seven diverse question answering datasets, we demonstrate that Dep-Search significantly enhances LLMs' ability to tackle complex multi-hop reasoning tasks, achieving substantial improvements over strong baselines across different model scales.
ToolGate: Contract-Grounded and Verified Tool Execution for LLMs
Jan 08, 2026Large Language Models (LLMs) augmented with external tools have demonstrated remarkable capabilities in complex reasoning tasks. However, existing frameworks rely heavily on natural language reasoning to determine when tools can be invoked and whether their results should be committed, lacking formal guarantees for logical safety and verifiability. We present \textbf{ToolGate}, a forward execution framework that provides logical safety guarantees and verifiable state evolution for LLM tool calling. ToolGate maintains an explicit symbolic state space as a typed key-value mapping representing trusted world information throughout the reasoning process. Each tool is formalized as a Hoare-style contract consisting of a precondition and a postcondition, where the precondition gates tool invocation by checking whether the current state satisfies the required conditions, and the postcondition determines whether the tool's result can be committed to update the state through runtime verification. Our approach guarantees that the symbolic state evolves only through verified tool executions, preventing invalid or hallucinated results from corrupting the world representation. Experimental validation demonstrates that ToolGate significantly improves the reliability and verifiability of tool-augmented LLM systems while maintaining competitive performance on complex multi-step reasoning tasks. This work establishes a foundation for building more trustworthy and debuggable AI systems that integrate language models with external tools.
NC2C: Automated Convexification of Generic Non-Convex Optimization Problems
Jan 08, 2026Non-convex optimization problems are pervasive across mathematical programming, engineering design, and scientific computing, often posing intractable challenges for traditional solvers due to their complex objective functions and constrained landscapes. To address the inefficiency of manual convexification and the over-reliance on expert knowledge, we propose NC2C, an LLM-based end-to-end automated framework designed to transform generic non-convex optimization problems into solvable convex forms using large language models. NC2C leverages LLMs' mathematical reasoning capabilities to autonomously detect non-convex components, select optimal convexification strategies, and generate rigorous convex equivalents. The framework integrates symbolic reasoning, adaptive transformation techniques, and iterative validation, equipped with error correction loops and feasibility domain correction mechanisms to ensure the robustness and validity of transformed problems. Experimental results on a diverse dataset of 100 generic non-convex problems demonstrate that NC2C achieves an 89.3\% execution rate and a 76\% success rate in producing feasible, high-quality convex transformations. This outperforms baseline methods by a significant margin, highlighting NC2C's ability to leverage LLMs for automated non-convex to convex transformation, reduce expert dependency, and enable efficient deployment of convex solvers for previously intractable optimization tasks.
LLM-OptiRA: LLM-Driven Optimization of Resource Allocation for Non-Convex Problems in Wireless Communications
May 04, 2025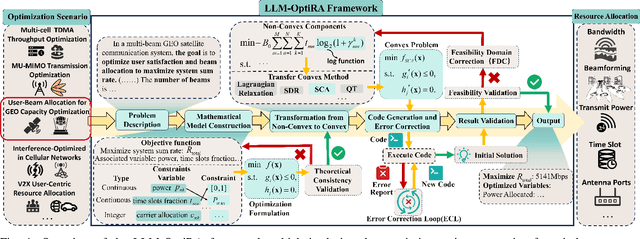
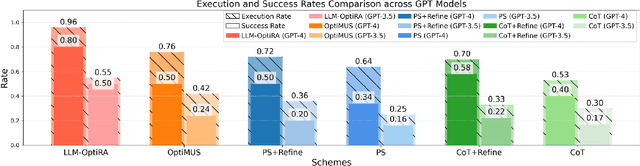
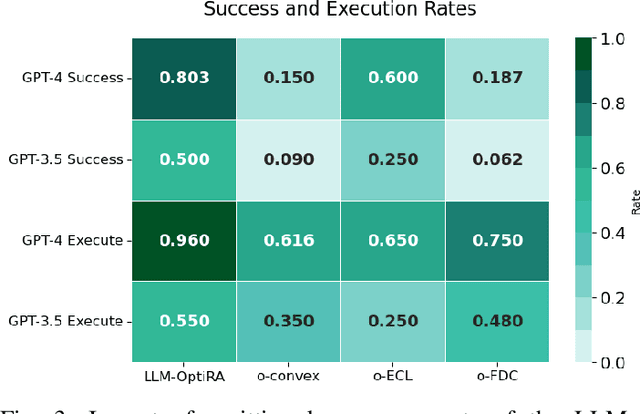
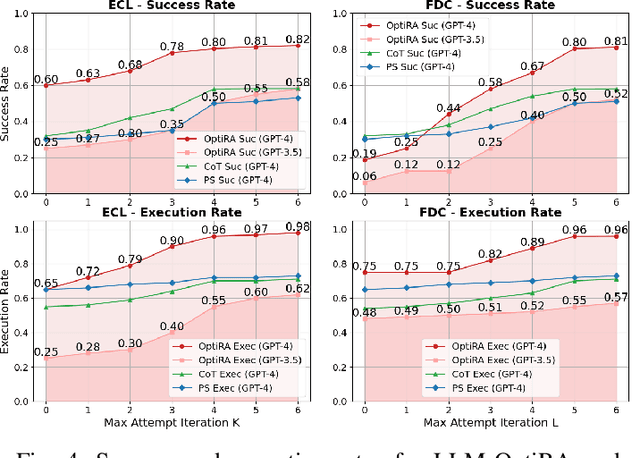
Solving non-convex resource allocation problems poses significant challenges in wireless communication systems, often beyond the capability of traditional optimization techniques. To address this issue, we propose LLM-OptiRA, the first framework that leverages large language models (LLMs) to automatically detect and transform non-convex components into solvable forms, enabling fully automated resolution of non-convex resource allocation problems in wireless communication systems. LLM-OptiRA not only simplifies problem-solving by reducing reliance on expert knowledge, but also integrates error correction and feasibility validation mechanisms to ensure robustness. Experimental results show that LLM-OptiRA achieves an execution rate of 96% and a success rate of 80% on GPT-4, significantly outperforming baseline approaches in complex optimization tasks across diverse scenarios.
Bridging Context Gaps: Leveraging Coreference Resolution for Long Contextual Understanding
Oct 02, 2024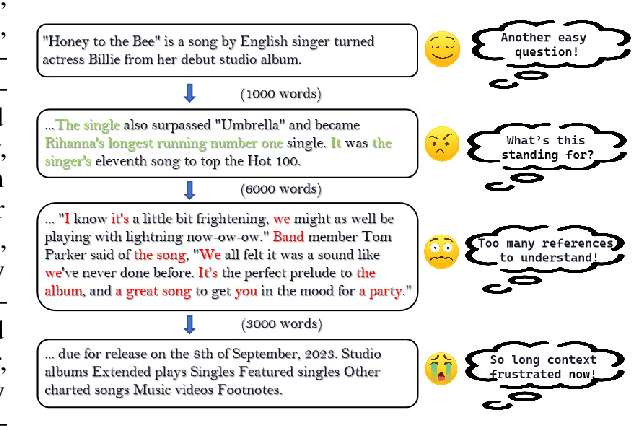
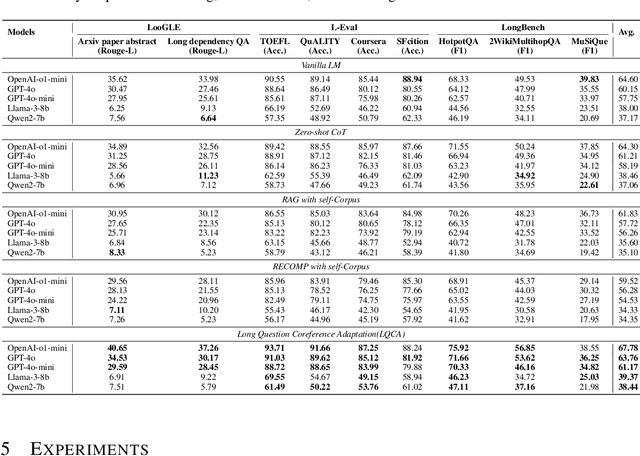
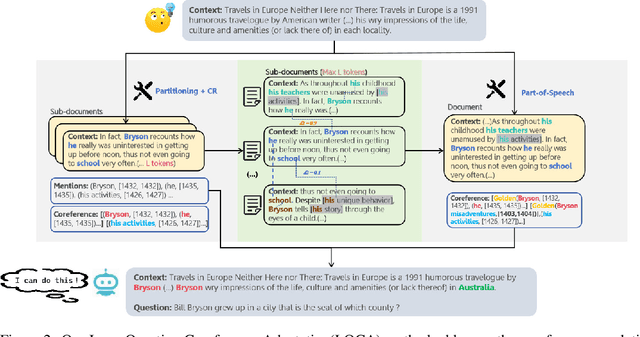
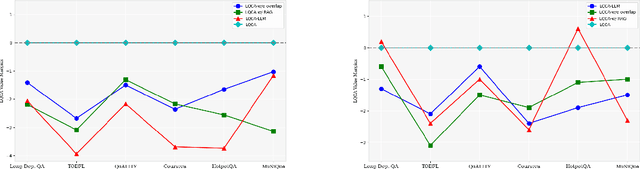
Large language models (LLMs) have shown remarkable capabilities in natural language processing; however, they still face difficulties when tasked with understanding lengthy contexts and executing effective question answering. These challenges often arise due to the complexity and ambiguity present in longer texts. To enhance the performance of LLMs in such scenarios, we introduce the Long Question Coreference Adaptation (LQCA) method. This innovative framework focuses on coreference resolution tailored to long contexts, allowing the model to identify and manage references effectively. The LQCA method encompasses four key steps: resolving coreferences within sub-documents, computing the distances between mentions, defining a representative mention for coreference, and answering questions through mention replacement. By processing information systematically, the framework provides easier-to-handle partitions for LLMs, promoting better understanding. Experimental evaluations on a range of LLMs and datasets have yielded positive results, with a notable improvements on OpenAI-o1-mini and GPT-4o models, highlighting the effectiveness of leveraging coreference resolution to bridge context gaps in question answering.
MemDPT: Differential Privacy for Memory Efficient Language Models
Jun 16, 2024
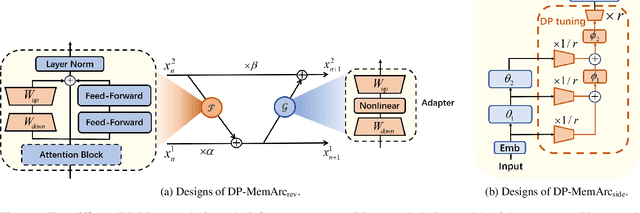
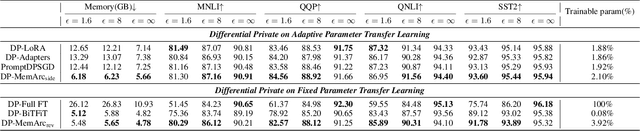
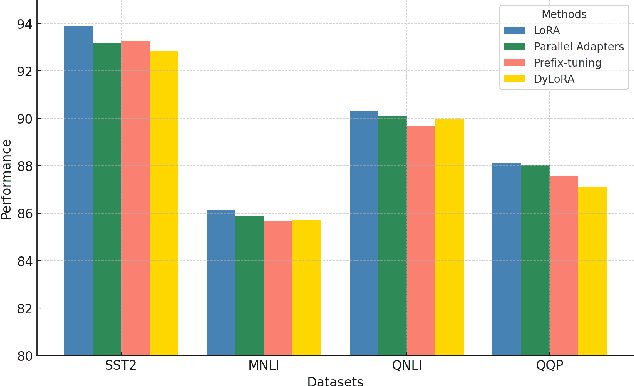
Large language models have consistently demonstrated remarkable performance across a wide spectrum of applications. Nonetheless, the deployment of these models can inadvertently expose user privacy to potential risks. The substantial memory demands of these models during training represent a significant resource consumption challenge. The sheer size of these models imposes a considerable burden on memory resources, which is a matter of significant concern in practice. In this paper, we present an innovative training framework MemDPT that not only reduces the memory cost of large language models but also places a strong emphasis on safeguarding user data privacy. MemDPT provides edge network and reverse network designs to accommodate various differential privacy memory-efficient fine-tuning schemes. Our approach not only achieves $2 \sim 3 \times$ memory optimization but also provides robust privacy protection, ensuring that user data remains secure and confidential. Extensive experiments have demonstrated that MemDPT can effectively provide differential privacy efficient fine-tuning across various task scenarios.
Tool-Planner: Dynamic Solution Tree Planning for Large Language Model with Tool Clustering
Jun 06, 2024



Large language models (LLMs) have demonstrated exceptional reasoning capabilities, enabling them to solve various complex problems. Recently, this ability has been applied to the paradigm of tool learning. Tool learning involves providing examples of tool usage and their corresponding functions, allowing LLMs to formulate plans and demonstrate the process of invoking and executing each tool. LLMs can address tasks that they cannot complete independently, thereby enhancing their potential across different tasks. However, this approach faces two key challenges. First, redundant error correction leads to unstable planning and long execution time. Additionally, designing a correct plan among multiple tools is also a challenge in tool learning. To address these issues, we propose Tool-Planner, a task-processing framework based on toolkits. Tool-Planner groups tools based on the API functions with the same function into a toolkit and allows LLMs to implement planning across the various toolkits. When a tool error occurs, the language model can reselect and adjust tools based on the toolkit. Experiments show that our approach demonstrates a high pass and win rate across different datasets and optimizes the planning scheme for tool learning in models such as GPT-4 and Claude 3, showcasing the potential of our method.
CPA-Enhancer: Chain-of-Thought Prompted Adaptive Enhancer for Object Detection under Unknown Degradations
Mar 22, 2024


Object detection methods under known single degradations have been extensively investigated. However, existing approaches require prior knowledge of the degradation type and train a separate model for each, limiting their practical applications in unpredictable environments. To address this challenge, we propose a chain-of-thought (CoT) prompted adaptive enhancer, CPA-Enhancer, for object detection under unknown degradations. Specifically, CPA-Enhancer progressively adapts its enhancement strategy under the step-by-step guidance of CoT prompts, that encode degradation-related information. To the best of our knowledge, it's the first work that exploits CoT prompting for object detection tasks. Overall, CPA-Enhancer is a plug-and-play enhancement model that can be integrated into any generic detectors to achieve substantial gains on degraded images, without knowing the degradation type priorly. Experimental results demonstrate that CPA-Enhancer not only sets the new state of the art for object detection but also boosts the performance of other downstream vision tasks under unknown degradations.
SPA: Towards A Computational Friendly Cloud-Base and On-Devices Collaboration Seq2seq Personalized Generation
Mar 11, 2024Large language models(LLMs) have shown its outperforming ability on various tasks and question answering. However, LLMs require high computation cost and large memory cost. At the same time, LLMs may cause privacy leakage when training or prediction procedure contains sensitive information. In this paper, we propose SPA(Side Plugin Adaption), a lightweight architecture for fast on-devices inference and privacy retaining on the constraints of strict on-devices computation and memory constraints. Compared with other on-devices seq2seq generation, SPA could make a fast and stable inference on low-resource constraints, allowing it to obtain cost effiency. Our method establish an interaction between a pretrained LLMs on-cloud and additive parameters on-devices, which could provide the knowledge on both pretrained LLMs and private personal feature.Further more, SPA provides a framework to keep feature-base parameters on private guaranteed but low computational devices while leave the parameters containing general information on the high computational devices.
RA-ISF: Learning to Answer and Understand from Retrieval Augmentation via Iterative Self-Feedback
Mar 11, 2024Large language models (LLMs) demonstrate exceptional performance in numerous tasks but still heavily rely on knowledge stored in their parameters. Moreover, updating this knowledge incurs high training costs. Retrieval-augmented generation (RAG) methods address this issue by integrating external knowledge. The model can answer questions it couldn't previously by retrieving knowledge relevant to the query. This approach improves performance in certain scenarios for specific tasks. However, if irrelevant texts are retrieved, it may impair model performance. In this paper, we propose Retrieval Augmented Iterative Self-Feedback (RA-ISF), a framework that iteratively decomposes tasks and processes them in three submodules to enhance the model's problem-solving capabilities. Experiments show that our method outperforms existing benchmarks, performing well on models like GPT3.5, Llama2, significantly enhancing factual reasoning capabilities and reducing hallucinations.