 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Agents "Misremember" Collectively: Exploring the Mandela Effect in LLM-based Multi-Agent Systems
Jan 31, 2026Recent advancements in large language models (LLMs) have significantly enhanced the capabilities of collaborative multi-agent systems, enabling them to address complex challenges. However, within these multi-agent systems, the susceptibility of agents to collective cognitive biases remains an underexplored issue. A compelling example is the Mandela effect, a phenomenon where groups collectively misremember past events as a result of false details reinforced through social influence and internalized misinformation. This vulnerability limits our understanding of memory bias in multi-agent systems and raises ethical concerns about the potential spread of misinformation. In this paper, we conduct a comprehensive study on the Mandela effect in LLM-based multi-agent systems, focusing on its existence, causing factors, and mitigation strategies. We propose MANBENCH, a novel benchmark designed to evaluate agent behaviors across four common task types that are susceptible to the Mandela effect, using five interaction protocols that vary in agent roles and memory timescales. We evaluate agents powered by several LLMs on MANBENCH to quantify the Mandela effect and analyze how different factors affect it. Moreover, we propose strategies to mitigate this effect, including prompt-level defenses (e.g., cognitive anchoring and source scrutiny) and model-level alignment-based defense, achieving an average 74.40% reduction in the Mandela effect compared to the baseline. Our findings provide valuable insights for developing more resilient and ethically aligned collaborative multi-agent systems.
FraudShield: Knowledge Graph Empowered Defense for LLMs against Fraud Attacks
Jan 30, 2026Large language models (LLMs) have been widely integrated into critical automated workflows, including contract review and job application processes. However, LLMs are susceptible to manipulation by fraudulent information, which can lead to harmful outcomes. Although advanced defense methods have been developed to address this issue, they often exhibit limitations in effectiveness, interpretability, and generalizability, particularly when applied to LLM-based applications. To address these challenges, we introduce FraudShield, a novel framework designed to protect LLMs from fraudulent content by leveraging a comprehensive analysis of fraud tactics. Specifically, FraudShield constructs and refines a fraud tactic-keyword knowledge graph to capture high-confidence associations between suspicious text and fraud techniques. The structured knowledge graph augments the original input by highlighting keywords and providing supporting evidence, guiding the LLM toward more secure responses. Extensive experiments show that FraudShield consistently outperforms state-of-the-art defenses across four mainstream LLMs and five representative fraud types, while also offering interpretable clues for the model's generations.
Bridging the Copyright Gap: Do Large Vision-Language Models Recognize and Respect Copyrighted Content?
Dec 26, 2025Large vision-language models (LVLMs) have achieved remarkable advancements in multimodal reasoning tasks. However, their widespread accessibility raises critical concerns about potential copyright infringement. Will LVLMs accurately recognize and comply with copyright regulations when encountering copyrighted content (i.e., user input, retrieved documents) in the context? Failure to comply with copyright regulations may lead to serious legal and ethical consequences, particularly when LVLMs generate responses based on copyrighted materials (e.g., retrieved book experts, news reports). In this paper, we present a comprehensive evaluation of various LVLMs, examining how they handle copyrighted content -- such as book excerpts, news articles, music lyrics, and code documentation when they are presented as visual inputs. To systematically measure copyright compliance, we introduce a large-scale benchmark dataset comprising 50,000 multimodal query-content pairs designed to evaluate how effectively LVLMs handle queries that could lead to copyright infringement. Given that real-world copyrighted content may or may not include a copyright notice, the dataset includes query-content pairs in two distinct scenarios: with and without a copyright notice. For the former, we extensively cover four types of copyright notices to account for different cases. Our evaluation reveals that even state-of-the-art closed-source LVLMs exhibit significant deficiencies in recognizing and respecting the copyrighted content, even when presented with the copyright notice. To solve this limitation, we introduce a novel tool-augmented defense framework for copyright compliance, which reduces infringement risks in all scenarios. Our findings underscore the importance of developing copyright-aware LVLMs to ensure the responsible and lawful use of copyrighted content.
The Eminence in Shadow: Exploiting Feature Boundary Ambiguity for Robust Backdoor Attacks
Dec 17, 2025Deep neural networks (DNNs) underpin critical applications yet remain vulnerable to backdoor attacks, typically reliant on heuristic brute-force methods. Despite significant empirical advancements in backdoor research, the lack of rigorous theoretical analysis limits understanding of underlying mechanisms, constraining attack predictability and adaptability. Therefore, we provide a theoretical analysis targeting backdoor attacks, focusing on how sparse decision boundaries enable disproportionate model manipulation. Based on this finding, we derive a closed-form, ambiguous boundary region, wherein negligible relabeled samples induce substantial misclassification. Influence function analysis further quantifies significant parameter shifts caused by these margin samples, with minimal impact on clean accuracy, formally grounding why such low poison rates suffice for efficacious attacks. Leveraging these insights, we propose Eminence, an explainable and robust black-box backdoor framework with provable theoretical guarantees and inherent stealth properties. Eminence optimizes a universal, visually subtle trigger that strategically exploits vulnerable decision boundaries and effectively achieves robust misclassification with exceptionally low poison rates (< 0.1%, compared to SOTA methods typically requiring > 1%). Comprehensive experiments validate our theoretical discussions and demonstrate the effectiveness of Eminence, confirming an exponential relationship between margin poisoning and adversarial boundary manipulation. Eminence maintains > 90% attack success rate, exhibits negligible clean-accuracy loss, and demonstrates high transferability across diverse models, datasets and scenarios.
NeuroBreak: Unveil Internal Jailbreak Mechanisms in Large Language Models
Sep 04, 2025In deployment and application, large language models (LLMs) typically undergo safety alignment to prevent illegal and unethical outputs. However, the continuous advancement of jailbreak attack techniques, designed to bypass safety mechanisms with adversarial prompts, has placed increasing pressure on the security defenses of LLMs. Strengthening resistance to jailbreak attacks requires an in-depth understanding of the security mechanisms and vulnerabilities of LLMs. However, the vast number of parameters and complex structure of LLMs make analyzing security weaknesses from an internal perspective a challenging task. This paper presents NeuroBreak, a top-down jailbreak analysis system designed to analyze neuron-level safety mechanisms and mitigate vulnerabilities. We carefully design system requirements through collaboration with three experts in the field of AI security. The system provides a comprehensive analysis of various jailbreak attack methods. By incorporating layer-wise representation probing analysis, NeuroBreak offers a novel perspective on the model's decision-making process throughout its generation steps. Furthermore, the system supports the analysis of critical neurons from both semantic and functional perspectives, facilitating a deeper exploration of security mechanisms. We conduct quantitative evaluations and case studies to verify the effectiveness of our system, offering mechanistic insights for developing next-generation defense strategies against evolving jailbreak attacks.
Scalable Multi-Stage Influence Function for Large Language Models via Eigenvalue-Corrected Kronecker-Factored Parameterization
May 08, 2025Pre-trained large language models (LLMs) are commonly fine-tuned to adapt to downstream tasks. Since the majority of knowledge is acquired during pre-training, attributing the predictions of fine-tuned LLMs to their pre-training data may provide valuable insights. Influence functions have been proposed as a means to explain model predictions based on training data. However, existing approaches fail to compute ``multi-stage'' influence and lack scalability to billion-scale LLMs. In this paper, we propose the multi-stage influence function to attribute the downstream predictions of fine-tuned LLMs to pre-training data under the full-parameter fine-tuning paradigm. To enhance the efficiency and practicality of our multi-stage influence function, we leverage Eigenvalue-corrected Kronecker-Factored (EK-FAC) parameterization for efficient approximation. Empirical results validate the superior scalability of EK-FAC approximation and the effectiveness of our multi-stage influence function. Additionally, case studies on a real-world LLM, dolly-v2-3b, demonstrate its interpretive power, with exemplars illustrating insights provided by multi-stage influence estimates. Our code is public at https://github.com/colored-dye/multi_stage_influence_function.
RAID: An In-Training Defense against Attribute Inference Attacks in Recommender Systems
Apr 15, 2025In various networks and mobile applications, users are highly susceptible to attribute inference attacks, with particularly prevalent occurrences in recommender systems. Attackers exploit partially exposed user profiles in recommendation models, such as user embeddings, to infer private attributes of target users, such as gender and political views. The goal of defenders is to mitigate the effectiveness of these attacks while maintaining recommendation performance. Most existing defense methods, such as differential privacy and attribute unlearning, focus on post-training settings, which limits their capability of utilizing training data to preserve recommendation performance. Although adversarial training extends defenses to in-training settings, it often struggles with convergence due to unstable training processes. In this paper, we propose RAID, an in-training defense method against attribute inference attacks in recommender systems. In addition to the recommendation objective, we define a defensive objective to ensure that the distribution of protected attributes becomes independent of class labels, making users indistinguishable from attribute inference attacks. Specifically, this defensive objective aims to solve a constrained Wasserstein barycenter problem to identify the centroid distribution that makes the attribute indistinguishable while complying with recommendation performance constraints. To optimize our proposed objective, we use optimal transport to align users with the centroid distribution. We conduct extensive experiments on four real-world datasets to evaluate RAID. The experimental results validate the effectiveness of RAID and demonstrate its significant superiority over existing methods in multiple aspects.
Bridging the Gap Between Preference Alignment and Machine Unlearning
Apr 09, 2025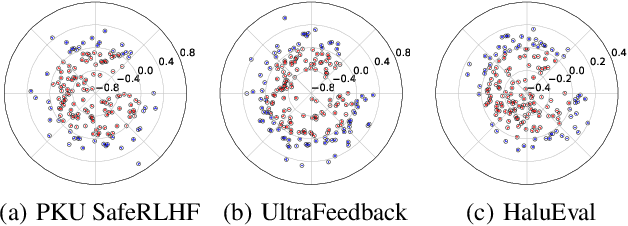
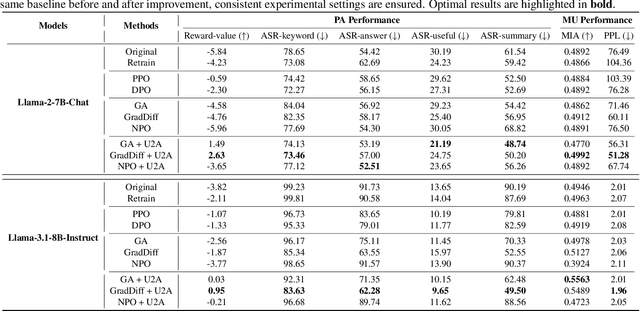
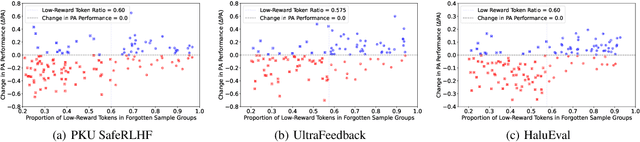

Despite advances in Preference Alignment (PA) for Large Language Models (LLMs), mainstream methods like Reinforcement Learning with Human Feedback (RLHF) face notable challenges. These approaches require high-quality datasets of positive preference examples, which are costly to obtain and computationally intensive due to training instability, limiting their use in low-resource scenarios. LLM unlearning technique presents a promising alternative, by directly removing the influence of negative examples. However, current research has primarily focused on empirical validation, lacking systematic quantitative analysis. To bridge this gap, we propose a framework to explore the relationship between PA and LLM unlearning. Specifically, we introduce a bi-level optimization-based method to quantify the impact of unlearning specific negative examples on PA performance. Our analysis reveals that not all negative examples contribute equally to alignment improvement when unlearned, and the effect varies significantly across examples. Building on this insight, we pose a crucial question: how can we optimally select and weight negative examples for unlearning to maximize PA performance? To answer this, we propose a framework called Unlearning to Align (U2A), which leverages bi-level optimization to efficiently select and unlearn examples for optimal PA performance. We validate the proposed method through extensive experiments, with results confirming its effectiveness.
CopyrightMeter: Revisiting Copyright Protection in Text-to-image Models
Nov 20, 2024



Text-to-image diffusion models have emerged as powerful tools for generating high-quality images from textual descriptions. However, their increasing popularity has raised significant copyright concerns, as these models can be misused to reproduce copyrighted content without authorization. In response, recent studies have proposed various copyright protection methods, including adversarial perturbation, concept erasure, and watermarking techniques. However, their effectiveness and robustness against advanced attacks remain largely unexplored. Moreover, the lack of unified evaluation frameworks has hindered systematic comparison and fair assessment of different approaches. To bridge this gap, we systematize existing copyright protection methods and attacks, providing a unified taxonomy of their design spaces. We then develop CopyrightMeter, a unified evaluation framework that incorporates 17 state-of-the-art protections and 16 representative attacks. Leveraging CopyrightMeter, we comprehensively evaluate protection methods across multiple dimensions, thereby uncovering how different design choices impact fidelity, efficacy, and resilience under attacks. Our analysis reveals several key findings: (i) most protections (16/17) are not resilient against attacks; (ii) the "best" protection varies depending on the target priority; (iii) more advanced attacks significantly promote the upgrading of protections. These insights provide concrete guidance for developing more robust protection methods, while its unified evaluation protocol establishes a standard benchmark for future copyright protection research in text-to-image generation.
HijackRAG: Hijacking Attacks against Retrieval-Augmented Large Language Models
Oct 30, 2024



Retrieval-Augmented Generation (RAG) systems enhance large language models (LLMs) by integrating external knowledge, making them adaptable and cost-effective for various applications. However, the growing reliance on these systems also introduces potential security risks. In this work, we reveal a novel vulnerability, the retrieval prompt hijack attack (HijackRAG), which enables attackers to manipulate the retrieval mechanisms of RAG systems by injecting malicious texts into the knowledge database. When the RAG system encounters target questions, it generates the attacker's pre-determined answers instead of the correct ones, undermining the integrity and trustworthiness of the system. We formalize HijackRAG as an optimization problem and propose both black-box and white-box attack strategies tailored to different levels of the attacker's knowledge. Extensive experiments on multiple benchmark datasets show that HijackRAG consistently achieves high attack success rates, outperforming existing baseline attacks. Furthermore, we demonstrate that the attack is transferable across different retriever models, underscoring the widespread risk it poses to RAG systems. Lastly, our exploration of various defense mechanisms reveals that they are insufficient to counter HijackRAG, emphasizing the urgent need for more robust security measures to protect RAG systems in real-world deployments.