 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
Generate Then Correct: Single Shot Global Correction for Aspect Sentiment Quad Prediction
Mar 14, 2026Aspect-based sentiment analysis (ABSA) extracts aspect-level sentiment signals from user-generated text, supports product analytics, experience monitoring, and public-opinion tracking, and is central to fine-grained opinion mining. A key challenge in ABSA is aspect sentiment quad prediction (ASQP), which requires identifying four elements: the aspect term, the aspect category, the opinion term, and the sentiment polarity. However, existing studies usually linearize the unordered quad set into a fixed-order template and decode it left-to-right. With teacher forcing training, the resulting training-inference mismatch (exposure bias) lets early prefix errors propagate to later elements. The linearization order determines which elements appear earlier in the prefix, so this propagation becomes order-sensitive and is hard to repair in a single pass. To address this, we propose a method, Generate-then-Correct (G2C): a generator drafts quads and a corrector performs a single-shot, sequence-level global correction trained on LLM-synthesized drafts with common error patterns. On the Rest15 and Rest16 datasets, G2C outperforms strong baseline models.
ClinConsensus: A Consensus-Based Benchmark for Evaluating Chinese Medical LLMs across Difficulty Levels
Mar 03, 2026Large language models (LLMs) are increasingly applied to health management, showing promise across disease prevention, clinical decision-making, and long-term care. However, existing medical benchmarks remain largely static and task-isolated, failing to capture the openness, longitudinal structure, and safety-critical complexity of real-world clinical workflows. We introduce ClinConsensus, a Chinese medical benchmark curated, validated, and quality-controlled by clinical experts. ClinConsensus comprises 2500 open-ended cases spanning the full continuum of care--from prevention and intervention to long-term follow-up--covering 36 medical specialties, 12 common clinical task types, and progressively increasing levels of complexity. To enable reliable evaluation of such complex scenarios, we adopt a rubric-based grading protocol and propose the Clinically Applicable Consistency Score (CACS@k). We further introduce a dual-judge evaluation framework, combining a high-capability LLM-as-judge with a distilled, locally deployable judge model trained via supervised fine-tuning, enabling scalable and reproducible evaluation aligned with physician judgment. Using ClinConsensus, we conduct a comprehensive assessment of several leading LLMs and reveal substantial heterogeneity across task themes, care stages, and medical specialties. While top-performing models achieve comparable overall scores, they differ markedly in reasoning, evidence use, and longitudinal follow-up capabilities, and clinically actionable treatment planning remains a key bottleneck. We release ClinConsensus as an extensible benchmark to support the development and evaluation of medical LLMs that are robust, clinically grounded, and ready for real-world deployment.
HLE-Verified: A Systematic Verification and Structured Revision of Humanity's Last Exam
Feb 17, 2026Humanity's Last Exam (HLE) has become a widely used benchmark for evaluating frontier large language models on challenging, multi-domain questions. However, community-led analyses have raised concerns that HLE contains a non-trivial number of noisy items, which can bias evaluation results and distort cross-model comparisons. To address this challenge, we introduce HLE-Verified, a verified and revised version of HLE with a transparent verification protocol and fine-grained error taxonomy. Our construction follows a two-stage validation-and-repair workflow resulting in a certified benchmark. In Stage I, each item undergoes binary validation of the problem and final answer through domain-expert review and model-based cross-checks, yielding 641 verified items. In Stage II, flawed but fixable items are revised under strict constraints preserving the original evaluation intent, through dual independent expert repairs, model-assisted auditing, and final adjudication, resulting in 1,170 revised-and-certified items. The remaining 689 items are released as a documented uncertain set with explicit uncertainty sources and expertise tags for future refinement. We evaluate seven state-of-the-art language models on HLE and HLE-Verified, observing an average absolute accuracy gain of 7--10 percentage points on HLE-Verified. The improvement is particularly pronounced on items where the original problem statement and/or reference answer is erroneous, with gains of 30--40 percentage points. Our analyses further reveal a strong association between model confidence and the presence of errors in the problem statement or reference answer, supporting the effectiveness of our revisions. Overall, HLE-Verified improves HLE-style evaluations by reducing annotation noise and enabling more faithful measurement of model capabilities. Data is available at: https://github.com/SKYLENAGE-AI/HLE-Verified
Accelerating Structured Chain-of-Thought in Autonomous Vehicles
Feb 02, 2026Chain-of-Thought (CoT) reasoning enhances the decision-making capabilities of vision-language-action models in autonomous driving, but its autoregressive nature introduces significant inference latency, making it impractical for real-time applications. To address this, we introduce FastDriveCoT, a novel parallel decoding method that accelerates template-structured CoT. Our approach decomposes the reasoning process into a dependency graph of distinct sub-tasks, such as identifying critical objects and summarizing traffic rules, some of which can be generated in parallel. By generating multiple independent reasoning steps concurrently within a single forward pass, we significantly reduce the number of sequential computations. Experiments demonstrate a 3-4$\times$ speedup in CoT generation and a substantial reduction in end-to-end latency across various model architectures, all while preserving the original downstream task improvements brought by incorporating CoT reasoning.
MFC-RFNet: A Multi-scale Guided Rectified Flow Network for Radar Sequence Prediction
Jan 07, 2026Accurate and high-resolution precipitation nowcasting from radar echo sequences is crucial for disaster mitigation and economic planning, yet it remains a significant challenge. Key difficulties include modeling complex multi-scale evolution, correcting inter-frame feature misalignment caused by displacement, and efficiently capturing long-range spatiotemporal context without sacrificing spatial fidelity. To address these issues, we present the Multi-scale Feature Communication Rectified Flow (RF) Network (MFC-RFNet), a generative framework that integrates multi-scale communication with guided feature fusion. To enhance multi-scale fusion while retaining fine detail, a Wavelet-Guided Skip Connection (WGSC) preserves high-frequency components, and a Feature Communication Module (FCM) promotes bidirectional cross-scale interaction. To correct inter-frame displacement, a Condition-Guided Spatial Transform Fusion (CGSTF) learns spatial transforms from conditioning echoes to align shallow features. The backbone adopts rectified flow training to learn near-linear probability-flow trajectories, enabling few-step sampling with stable fidelity. Additionally, lightweight Vision-RWKV (RWKV) blocks are placed at the encoder tail, the bottleneck, and the first decoder layer to capture long-range spatiotemporal dependencies at low spatial resolutions with moderate compute. Evaluations on four public datasets (SEVIR, MeteoNet, Shanghai, and CIKM) demonstrate consistent improvements over strong baselines, yielding clearer echo morphology at higher rain-rate thresholds and sustained skill at longer lead times. These results suggest that the proposed synergy of RF training with scale-aware communication, spatial alignment, and frequency-aware fusion presents an effective and robust approach for radar-based nowcasting.
Counterfactual VLA: Self-Reflective Vision-Language-Action Model with Adaptive Reasoning
Dec 30, 2025Recent reasoning-augmented Vision-Language-Action (VLA) models have improved the interpretability of end-to-end autonomous driving by generating intermediate reasoning traces. Yet these models primarily describe what they perceive and intend to do, rarely questioning whether their planned actions are safe or appropriate. This work introduces Counterfactual VLA (CF-VLA), a self-reflective VLA framework that enables the model to reason about and revise its planned actions before execution. CF-VLA first generates time-segmented meta-actions that summarize driving intent, and then performs counterfactual reasoning conditioned on both the meta-actions and the visual context. This step simulates potential outcomes, identifies unsafe behaviors, and outputs corrected meta-actions that guide the final trajectory generation. To efficiently obtain such self-reflective capabilities, we propose a rollout-filter-label pipeline that mines high-value scenes from a base (non-counterfactual) VLA's rollouts and labels counterfactual reasoning traces for subsequent training rounds. Experiments on large-scale driving datasets show that CF-VLA improves trajectory accuracy by up to 17.6%, enhances safety metrics by 20.5%, and exhibits adaptive thinking: it only enables counterfactual reasoning in challenging scenarios. By transforming reasoning traces from one-shot descriptions to causal self-correction signals, CF-VLA takes a step toward self-reflective autonomous driving agents that learn to think before they act.
Latent Chain-of-Thought World Modeling for End-to-End Driving
Dec 11, 2025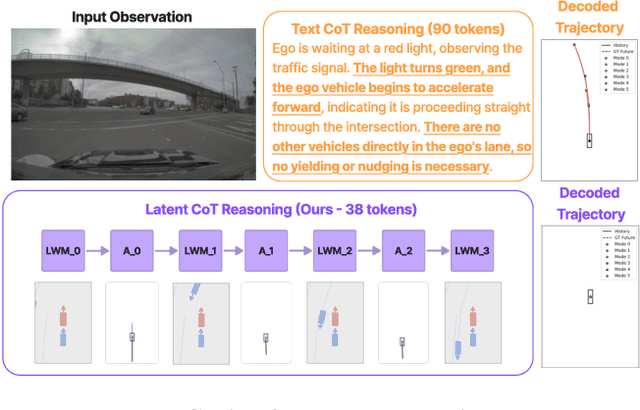
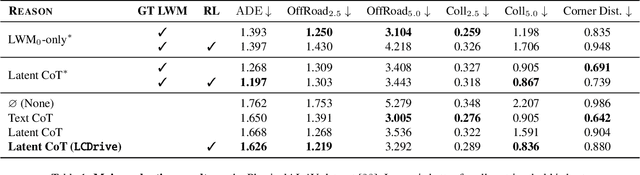
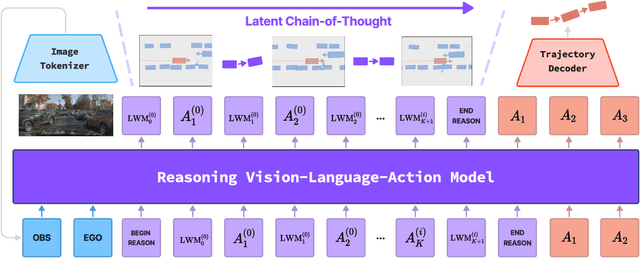
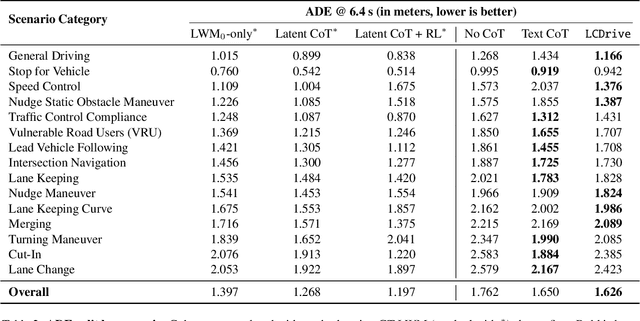
Recent Vision-Language-Action (VLA) models for autonomous driving explore inference-time reasoning as a way to improve driving performance and safety in challenging scenarios. Most prior work uses natural language to express chain-of-thought (CoT) reasoning before producing driving actions. However, text may not be the most efficient representation for reasoning. In this work, we present Latent-CoT-Drive (LCDrive): a model that expresses CoT in a latent language that captures possible outcomes of the driving actions being considered. Our approach unifies CoT reasoning and decision making by representing both in an action-aligned latent space. Instead of natural language, the model reasons by interleaving (1) action-proposal tokens, which use the same vocabulary as the model's output actions; and (2) world model tokens, which are grounded in a learned latent world model and express future outcomes of these actions. We cold start latent CoT by supervising the model's action proposals and world model tokens based on ground-truth future rollouts of the scene. We then post-train with closed-loop reinforcement learning to strengthen reasoning capabilities. On a large-scale end-to-end driving benchmark, LCDrive achieves faster inference, better trajectory quality, and larger improvements from interactive reinforcement learning compared to both non-reasoning and text-reasoning baselines.
Efficient Multi-Camera Tokenization with Triplanes for End-to-End Driving
Jun 13, 2025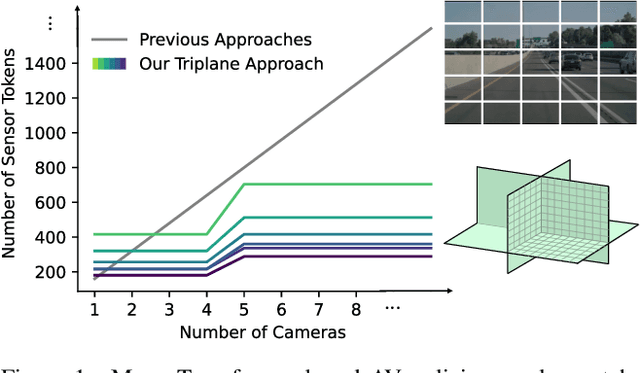
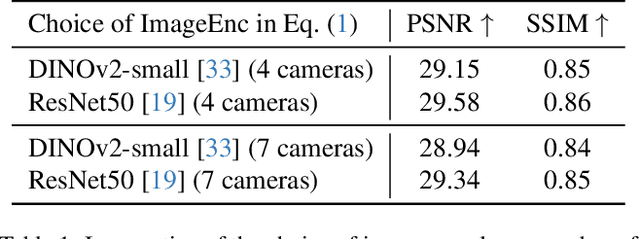
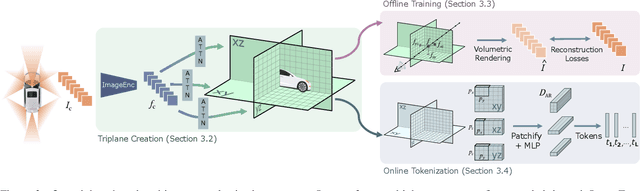
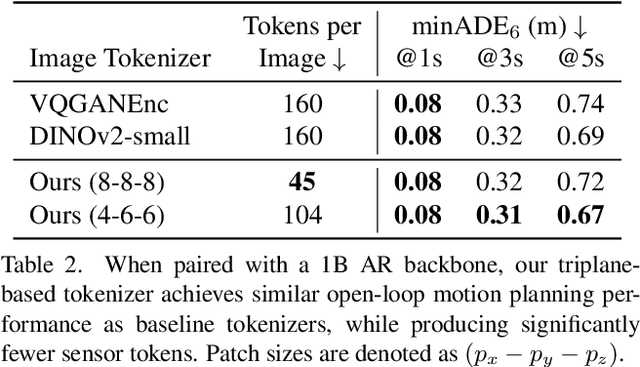
Autoregressive Transformers are increasingly being deployed as end-to-end robot and autonomous vehicle (AV) policy architectures, owing to their scalability and potential to leverage internet-scale pretraining for generalization. Accordingly, tokenizing sensor data efficiently is paramount to ensuring the real-time feasibility of such architectures on embedded hardware. To this end, we present an efficient triplane-based multi-camera tokenization strategy that leverages recent advances in 3D neural reconstruction and rendering to produce sensor tokens that are agnostic to the number of input cameras and their resolution, while explicitly accounting for their geometry around an AV. Experiments on a large-scale AV dataset and state-of-the-art neural simulator demonstrate that our approach yields significant savings over current image patch-based tokenization strategies, producing up to 72% fewer tokens, resulting in up to 50% faster policy inference while achieving the same open-loop motion planning accuracy and improved offroad rates in closed-loop driving simulations.
CopyrightMeter: Revisiting Copyright Protection in Text-to-image Models
Nov 20, 2024



Text-to-image diffusion models have emerged as powerful tools for generating high-quality images from textual descriptions. However, their increasing popularity has raised significant copyright concerns, as these models can be misused to reproduce copyrighted content without authorization. In response, recent studies have proposed various copyright protection methods, including adversarial perturbation, concept erasure, and watermarking techniques. However, their effectiveness and robustness against advanced attacks remain largely unexplored. Moreover, the lack of unified evaluation frameworks has hindered systematic comparison and fair assessment of different approaches. To bridge this gap, we systematize existing copyright protection methods and attacks, providing a unified taxonomy of their design spaces. We then develop CopyrightMeter, a unified evaluation framework that incorporates 17 state-of-the-art protections and 16 representative attacks. Leveraging CopyrightMeter, we comprehensively evaluate protection methods across multiple dimensions, thereby uncovering how different design choices impact fidelity, efficacy, and resilience under attacks. Our analysis reveals several key findings: (i) most protections (16/17) are not resilient against attacks; (ii) the "best" protection varies depending on the target priority; (iii) more advanced attacks significantly promote the upgrading of protections. These insights provide concrete guidance for developing more robust protection methods, while its unified evaluation protocol establishes a standard benchmark for future copyright protection research in text-to-image generation.