 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocus-LIME: Surgical Interpretation of Long-Context Large Language Models via Proxy-Based Neighborhood Selection
Feb 04, 2026As Large Language Models (LLMs) scale to handle massive context windows, achieving surgical feature-level interpretation is essential for high-stakes tasks like legal auditing and code debugging. However, existing local model-agnostic explanation methods face a critical dilemma in these scenarios: feature-based methods suffer from attribution dilution due to high feature dimensionality, thus failing to provide faithful explanations. In this paper, we propose Focus-LIME, a coarse-to-fine framework designed to restore the tractability of surgical interpretation. Focus-LIME utilizes a proxy model to curate the perturbation neighborhood, allowing the target model to perform fine-grained attribution exclusively within the optimized context. Empirical evaluations on long-context benchmarks demonstrate that our method makes surgical explanations practicable and provides faithful explanations to users.
DeepFeature: Iterative Context-aware Feature Generation for Wearable Biosignals
Dec 09, 2025Biosignals collected from wearable devices are widely utilized in healthcare applications. Machine learning models used in these applications often rely on features extracted from biosignals due to their effectiveness, lower data dimensionality, and wide compatibility across various model architectures. However, existing feature extraction methods often lack task-specific contextual knowledge, struggle to identify optimal feature extraction settings in high-dimensional feature space, and are prone to code generation and automation errors. In this paper, we propose DeepFeature, the first LLM-empowered, context-aware feature generation framework for wearable biosignals. DeepFeature introduces a multi-source feature generation mechanism that integrates expert knowledge with task settings. It also employs an iterative feature refinement process that uses feature assessment-based feedback for feature re-selection. Additionally, DeepFeature utilizes a robust multi-layer filtering and verification approach for robust feature-to-code translation to ensure that the extraction functions run without crashing. Experimental evaluation results show that DeepFeature achieves an average AUROC improvement of 4.21-9.67% across eight diverse tasks compared to baseline methods. It outperforms state-of-the-art approaches on five tasks while maintaining comparable performance on the remaining tasks.
ContextAgent: Context-Aware Proactive LLM Agents with Open-World Sensory Perceptions
May 20, 2025Recent advances in Large Language Models (LLMs) have propelled intelligent agents from reactive responses to proactive support. While promising, existing proactive agents either rely exclusively on observations from enclosed environments (e.g., desktop UIs) with direct LLM inference or employ rule-based proactive notifications, leading to suboptimal user intent understanding and limited functionality for proactive service. In this paper, we introduce ContextAgent, the first context-aware proactive agent that incorporates extensive sensory contexts to enhance the proactive capabilities of LLM agents. ContextAgent first extracts multi-dimensional contexts from massive sensory perceptions on wearables (e.g., video and audio) to understand user intentions. ContextAgent then leverages the sensory contexts and the persona contexts from historical data to predict the necessity for proactive services. When proactive assistance is needed, ContextAgent further automatically calls the necessary tools to assist users unobtrusively. To evaluate this new task, we curate ContextAgentBench, the first benchmark for evaluating context-aware proactive LLM agents, covering 1,000 samples across nine daily scenarios and twenty tools. Experiments on ContextAgentBench show that ContextAgent outperforms baselines by achieving up to 8.5% and 6.0% higher accuracy in proactive predictions and tool calling, respectively. We hope our research can inspire the development of more advanced, human-centric, proactive AI assistants.
An LLM-Empowered Low-Resolution Vision System for On-Device Human Behavior Understanding
May 03, 2025The rapid advancements in Large Vision Language Models (LVLMs) offer the potential to surpass conventional labeling by generating richer, more detailed descriptions of on-device human behavior understanding (HBU) in low-resolution vision systems, such as depth, thermal, and infrared. However, existing large vision language model (LVLM) approaches are unable to understand low-resolution data well as they are primarily designed for high-resolution data, such as RGB images. A quick fixing approach is to caption a large amount of low-resolution data, but it requires a significant amount of labor-intensive annotation efforts. In this paper, we propose a novel, labor-saving system, Llambda, designed to support low-resolution HBU. The core idea is to leverage limited labeled data and a large amount of unlabeled data to guide LLMs in generating informative captions, which can be combined with raw data to effectively fine-tune LVLM models for understanding low-resolution videos in HBU. First, we propose a Contrastive-Oriented Data Labeler, which can capture behavior-relevant information from long, low-resolution videos and generate high-quality pseudo labels for unlabeled data via contrastive learning. Second, we propose a Physical-Knowledge Guided Captioner, which utilizes spatial and temporal consistency checks to mitigate errors in pseudo labels. Therefore, it can improve LLMs' understanding of sequential data and then generate high-quality video captions. Finally, to ensure on-device deployability, we employ LoRA-based efficient fine-tuning to adapt LVLMs for low-resolution data. We evaluate Llambda using a region-scale real-world testbed and three distinct low-resolution datasets, and the experiments show that Llambda outperforms several state-of-the-art LVLM systems up to $40.03\%$ on average Bert-Score.
MMLNB: Multi-Modal Learning for Neuroblastoma Subtyping Classification Assisted with Textual Description Generation
Mar 17, 2025Neuroblastoma (NB), a leading cause of childhood cancer mortality, exhibits significant histopathological variability, necessitating precise subtyping for accurate prognosis and treatment. Traditional diagnostic methods rely on subjective evaluations that are time-consuming and inconsistent. To address these challenges, we introduce MMLNB, a multi-modal learning (MML) model that integrates pathological images with generated textual descriptions to improve classification accuracy and interpretability. The approach follows a two-stage process. First, we fine-tune a Vision-Language Model (VLM) to enhance pathology-aware text generation. Second, the fine-tuned VLM generates textual descriptions, using a dual-branch architecture to independently extract visual and textual features. These features are fused via Progressive Robust Multi-Modal Fusion (PRMF) Block for stable training. Experimental results show that the MMLNB model is more accurate than the single modal model. Ablation studies demonstrate the importance of multi-modal fusion, fine-tuning, and the PRMF mechanism. This research creates a scalable AI-driven framework for digital pathology, enhancing reliability and interpretability in NB subtyping classification. Our source code is available at https://github.com/HovChen/MMLNB.
SocialMind: LLM-based Proactive AR Social Assistive System with Human-like Perception for In-situ Live Interactions
Dec 05, 2024

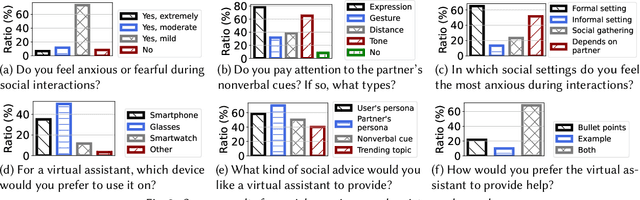
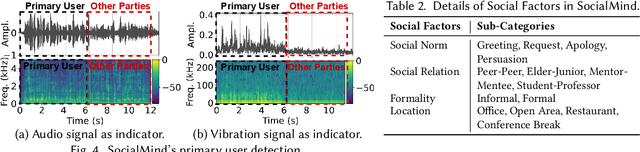
Social interactions are fundamental to human life. The recent emergence of large language models (LLMs)-based virtual assistants has demonstrated their potential to revolutionize human interactions and lifestyles. However, existing assistive systems mainly provide reactive services to individual users, rather than offering in-situ assistance during live social interactions with conversational partners. In this study, we introduce SocialMind, the first LLM-based proactive AR social assistive system that provides users with in-situ social assistance. SocialMind employs human-like perception leveraging multi-modal sensors to extract both verbal and nonverbal cues, social factors, and implicit personas, incorporating these social cues into LLM reasoning for social suggestion generation. Additionally, SocialMind employs a multi-tier collaborative generation strategy and proactive update mechanism to display social suggestions on Augmented Reality (AR) glasses, ensuring that suggestions are timely provided to users without disrupting the natural flow of conversation. Evaluations on three public datasets and a user study with 20 participants show that SocialMind achieves 38.3% higher engagement compared to baselines, and 95% of participants are willing to use SocialMind in their live social interactions.
TextMaster: Universal Controllable Text Edit
Oct 13, 2024In image editing tasks, high-quality text editing capabilities can significantly reduce human and material resource costs. Current methods rely heavily on training data based on OCR text segment detection, where the text is tightly aligned with the mask area. This reliance creates a strong dependency on the mask area and lacks modules for adjusting text spacing and size in various scenarios. When the amount of text to be edited does not match the modification area or when the mask area is too large, significant issues may arise. Furthermore, no existing methods have explored controllable style transfer for text editing.To address these challenges, we propose TextMaster, a solution capable of accurately editing text with high realism and proper layout in any scenario and image area. Our approach employs adaptive standard letter spacing as guidance during training and uses adaptive mask boosting to prevent the leakage of text position and size information. We also utilize an attention mechanism to calculate the bounding box regression loss for each character, making text layout methods learnable across different scenarios. By injecting high-resolution standard font information and applying perceptual loss in the text editing area, we further enhance text rendering accuracy and fidelity. Additionally, we achieve style consistency between the modified and target text through a novel style injection method. Extensive qualitative and quantitative evaluations demonstrate that our method outperforms all existing approaches.
AnomalySD: Few-Shot Multi-Class Anomaly Detection with Stable Diffusion Model
Aug 04, 2024



Anomaly detection is a critical task in industrial manufacturing, aiming to identify defective parts of products. Most industrial anomaly detection methods assume the availability of sufficient normal data for training. This assumption may not hold true due to the cost of labeling or data privacy policies. Additionally, mainstream methods require training bespoke models for different objects, which incurs heavy costs and lacks flexibility in practice. To address these issues, we seek help from Stable Diffusion (SD) model due to its capability of zero/few-shot inpainting, which can be leveraged to inpaint anomalous regions as normal. In this paper, a few-shot multi-class anomaly detection framework that adopts Stable Diffusion model is proposed, named AnomalySD. To adapt SD to anomaly detection task, we design different hierarchical text descriptions and the foreground mask mechanism for fine-tuning SD. In the inference stage, to accurately mask anomalous regions for inpainting, we propose multi-scale mask strategy and prototype-guided mask strategy to handle diverse anomalous regions. Hierarchical text prompts are also utilized to guide the process of inpainting in the inference stage. The anomaly score is estimated based on inpainting result of all masks. Extensive experiments on the MVTec-AD and VisA datasets demonstrate the superiority of our approach. We achieved anomaly classification and segmentation results of 93.6%/94.8% AUROC on the MVTec-AD dataset and 86.1%/96.5% AUROC on the VisA dataset under multi-class and one-shot settings.
DrHouse: An LLM-empowered Diagnostic Reasoning System through Harnessing Outcomes from Sensor Data and Expert Knowledge
May 21, 2024Large language models (LLMs) have the potential to transform digital healthcare, as evidenced by recent advances in LLM-based virtual doctors. However, current approaches rely on patient's subjective descriptions of symptoms, causing increased misdiagnosis. Recognizing the value of daily data from smart devices, we introduce a novel LLM-based multi-turn consultation virtual doctor system, DrHouse, which incorporates three significant contributions: 1) It utilizes sensor data from smart devices in the diagnosis process, enhancing accuracy and reliability. 2) DrHouse leverages continuously updating medical databases such as Up-to-Date and PubMed to ensure our model remains at diagnostic standard's forefront. 3) DrHouse introduces a novel diagnostic algorithm that concurrently evaluates potential diseases and their likelihood, facilitating more nuanced and informed medical assessments. Through multi-turn interactions, DrHouse determines the next steps, such as accessing daily data from smart devices or requesting in-lab tests, and progressively refines its diagnoses. Evaluations on three public datasets and our self-collected datasets show that DrHouse can achieve up to an 18.8% increase in diagnosis accuracy over the state-of-the-art baselines. The results of a 32-participant user study show that 75% medical experts and 91.7% patients are willing to use DrHouse.
Soar: Design and Deployment of A Smart Roadside Infrastructure System for Autonomous Driving
Apr 21, 2024
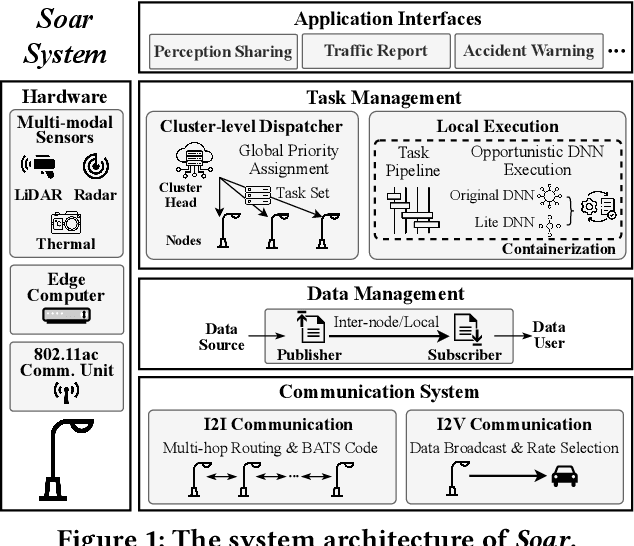
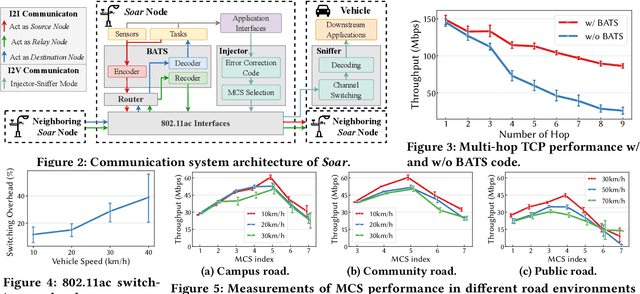
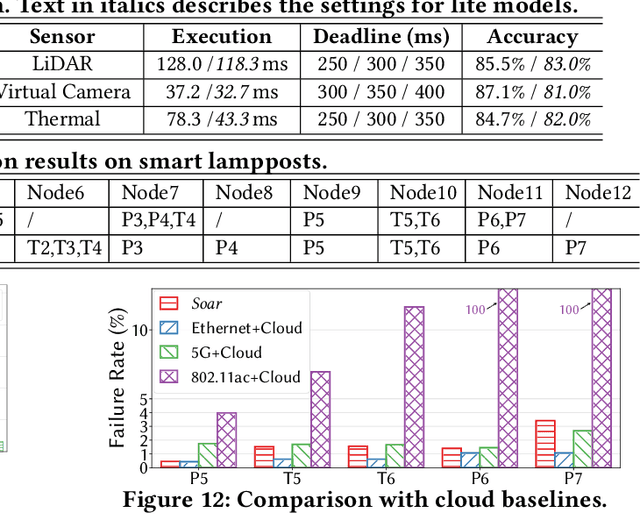
Recently,smart roadside infrastructure (SRI) has demonstrated the potential of achieving fully autonomous driving systems. To explore the potential of infrastructure-assisted autonomous driving, this paper presents the design and deployment of Soar, the first end-to-end SRI system specifically designed to support autonomous driving systems. Soar consists of both software and hardware components carefully designed to overcome various system and physical challenges. Soar can leverage the existing operational infrastructure like street lampposts for a lower barrier of adoption. Soar adopts a new communication architecture that comprises a bi-directional multi-hop I2I network and a downlink I2V broadcast service, which are designed based on off-the-shelf 802.11ac interfaces in an integrated manner. Soar also features a hierarchical DL task management framework to achieve desirable load balancing among nodes and enable them to collaborate efficiently to run multiple data-intensive autonomous driving applications. We deployed a total of 18 Soar nodes on existing lampposts on campus, which have been operational for over two years. Our real-world evaluation shows that Soar can support a diverse set of autonomous driving applications and achieve desirable real-time performance and high communication reliability. Our findings and experiences in this work offer key insights into the development and deployment of next-generation smart roadside infrastructure and autonomous driving systems.