 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoTrail-GUI: Building Actionable Memory for GUI Agents via Critic-Guided Self-Exploration
Dec 22, 2025Contemporary GUI agents, while increasingly capable due to advances in Large Vision-Language Models (VLMs), often operate with a critical limitation: they treat each task in isolation, lacking a mechanism to systematically learn from past successes. This digital ''amnesia'' results in sub-optimal performance, repeated errors, and poor generalization to novel challenges. To bridge this gap, we introduce EchoTrail-GUI, a novel framework designed to mimic human-like experiential learning by equipping agents with a dynamic, accessible memory. Our framework operates in three distinct stages. First, during Experience Exploration, an agent autonomously interacts with GUI environments to build a curated database of successful task trajectories, validated by a reward model. Crucially, the entire knowledge base construction is thus fully automated, requiring no human supervision. Second, in the Memory Injection stage, upon receiving a new task, our system efficiently retrieves the most relevant past trajectories to serve as actionable ''memories''. Finally, during GUI Task Inference, these memories are injected as in-context guidance to inform the agent's reasoning and decision-making process. We demonstrate the efficacy of our approach on benchmarks including Android World and AndroidLab. The results show that EchoTrail-GUI significantly improves the task success rate and operational efficiency of baseline agents, validating the power of structured memory in creating more robust and intelligent GUI automation.
Erase Diffusion: Empowering Object Removal Through Calibrating Diffusion Pathways
Mar 10, 2025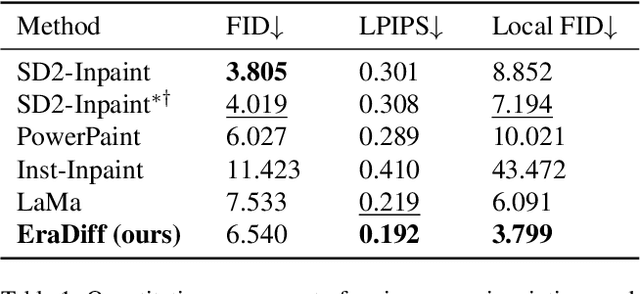
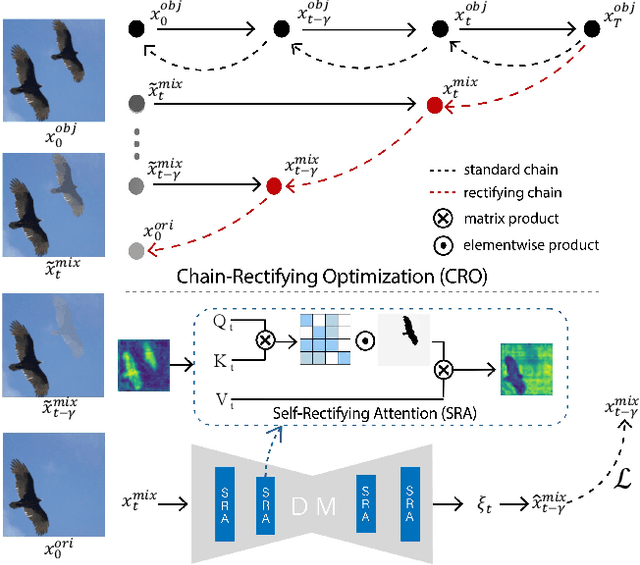
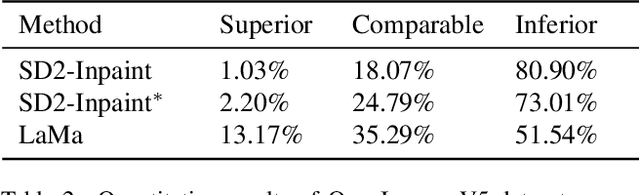

Erase inpainting, or object removal, aims to precisely remove target objects within masked regions while preserving the overall consistency of the surrounding content. Despite diffusion-based methods have made significant strides in the field of image inpainting, challenges remain regarding the emergence of unexpected objects or artifacts. We assert that the inexact diffusion pathways established by existing standard optimization paradigms constrain the efficacy of object removal. To tackle these challenges, we propose a novel Erase Diffusion, termed EraDiff, aimed at unleashing the potential power of standard diffusion in the context of object removal. In contrast to standard diffusion, the EraDiff adapts both the optimization paradigm and the network to improve the coherence and elimination of the erasure results. We first introduce a Chain-Rectifying Optimization (CRO) paradigm, a sophisticated diffusion process specifically designed to align with the objectives of erasure. This paradigm establishes innovative diffusion transition pathways that simulate the gradual elimination of objects during optimization, allowing the model to accurately capture the intent of object removal. Furthermore, to mitigate deviations caused by artifacts during the sampling pathways, we develop a simple yet effective Self-Rectifying Attention (SRA) mechanism. The SRA calibrates the sampling pathways by altering self-attention activation, allowing the model to effectively bypass artifacts while further enhancing the coherence of the generated content. With this design, our proposed EraDiff achieves state-of-the-art performance on the OpenImages V5 dataset and demonstrates significant superiority in real-world scenarios.
RAGDiffusion: Faithful Cloth Generation via External Knowledge Assimilation
Nov 29, 2024



Standard clothing asset generation involves creating forward-facing flat-lay garment images displayed on a clear background by extracting clothing information from diverse real-world contexts, which presents significant challenges due to highly standardized sampling distributions and precise structural requirements in the generated images. Existing models have limited spatial perception and often exhibit structural hallucinations in this high-specification generative task. To address this issue, we propose a novel Retrieval-Augmented Generation (RAG) framework, termed RAGDiffusion, to enhance structure determinacy and mitigate hallucinations by assimilating external knowledge from LLM and databases. RAGDiffusion consists of two core processes: (1) Retrieval-based structure aggregation, which employs contrastive learning and a Structure Locally Linear Embedding (SLLE) to derive global structure and spatial landmarks, providing both soft and hard guidance to counteract structural ambiguities; and (2) Omni-level faithful garment generation, which introduces a three-level alignment that ensures fidelity in structural, pattern, and decoding components within the diffusing. Extensive experiments on challenging real-world datasets demonstrate that RAGDiffusion synthesizes structurally and detail-faithful clothing assets with significant performance improvements, representing a pioneering effort in high-specification faithful generation with RAG to confront intrinsic hallucinations and enhance fidelity.
TextMaster: Universal Controllable Text Edit
Oct 13, 2024In image editing tasks, high-quality text editing capabilities can significantly reduce human and material resource costs. Current methods rely heavily on training data based on OCR text segment detection, where the text is tightly aligned with the mask area. This reliance creates a strong dependency on the mask area and lacks modules for adjusting text spacing and size in various scenarios. When the amount of text to be edited does not match the modification area or when the mask area is too large, significant issues may arise. Furthermore, no existing methods have explored controllable style transfer for text editing.To address these challenges, we propose TextMaster, a solution capable of accurately editing text with high realism and proper layout in any scenario and image area. Our approach employs adaptive standard letter spacing as guidance during training and uses adaptive mask boosting to prevent the leakage of text position and size information. We also utilize an attention mechanism to calculate the bounding box regression loss for each character, making text layout methods learnable across different scenarios. By injecting high-resolution standard font information and applying perceptual loss in the text editing area, we further enhance text rendering accuracy and fidelity. Additionally, we achieve style consistency between the modified and target text through a novel style injection method. Extensive qualitative and quantitative evaluations demonstrate that our method outperforms all existing approaches.
AnyFit: Controllable Virtual Try-on for Any Combination of Attire Across Any Scenario
May 28, 2024



While image-based virtual try-on has made significant strides, emerging approaches still fall short of delivering high-fidelity and robust fitting images across various scenarios, as their models suffer from issues of ill-fitted garment styles and quality degrading during the training process, not to mention the lack of support for various combinations of attire. Therefore, we first propose a lightweight, scalable, operator known as Hydra Block for attire combinations. This is achieved through a parallel attention mechanism that facilitates the feature injection of multiple garments from conditionally encoded branches into the main network. Secondly, to significantly enhance the model's robustness and expressiveness in real-world scenarios, we evolve its potential across diverse settings by synthesizing the residuals of multiple models, as well as implementing a mask region boost strategy to overcome the instability caused by information leakage in existing models. Equipped with the above design, AnyFit surpasses all baselines on high-resolution benchmarks and real-world data by a large gap, excelling in producing well-fitting garments replete with photorealistic and rich details. Furthermore, AnyFit's impressive performance on high-fidelity virtual try-ons in any scenario from any image, paves a new path for future research within the fashion community.
Conifer: Improving Complex Constrained Instruction-Following Ability of Large Language Models
Apr 03, 2024The ability of large language models (LLMs) to follow instructions is crucial to real-world applications. Despite recent advances, several studies have highlighted that LLMs struggle when faced with challenging instructions, especially those that include complex constraints, hindering their effectiveness in various tasks. To address this challenge, we introduce Conifer, a novel instruction tuning dataset, designed to enhance LLMs to follow multi-level instructions with complex constraints. Utilizing GPT-4, we curate the dataset by a series of LLM-driven refinement processes to ensure high quality. We also propose a progressive learning scheme that emphasizes an easy-to-hard progression, and learning from process feedback. Models trained with Conifer exhibit remarkable improvements in instruction-following abilities, especially for instructions with complex constraints. On several instruction-following benchmarks, our 7B model outperforms the state-of-the-art open-source 7B models, even exceeds the performance of models 10 times larger on certain metrics. All the code and Conifer dataset are available at https://www.github.com/ConiferLM/Conifer.