 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Probe: Generated Image Result Prediction Using CNN Probes
Mar 05, 2026Text-to-image (T2I) diffusion models lack an efficient mechanism for early quality assessment, leading to costly trial-and-error in multi-generation scenarios such as prompt iteration, agent-based generation, and flow-grpo. We reveal a strong correlation between early diffusion cross-attention distributions and final image quality. Based on this finding, we introduce Diffusion Probe, a framework that leverages internal cross-attention maps as predictive signals. We design a lightweight predictor that maps statistical properties of early-stage cross-attention extracted from initial denoising steps to the final image's overall quality. This enables accurate forecasting of image quality across diverse evaluation metrics long before full synthesis is complete. We validate Diffusion Probe across a wide range of settings. On multiple T2I models, across early denoising windows, resolutions, and quality metrics, it achieves strong correlation (PCC > 0.7) and high classification performance (AUC-ROC > 0.9). Its reliability translates into practical gains. By enabling early quality-aware decisions in workflows such as prompt optimization, seed selection, and accelerated RL training, the probe supports more targeted sampling and avoids computation on low-potential generations. This reduces computational overhead while improving final output quality.Diffusion Probe is model-agnostic, efficient, and broadly applicable, offering a practical solution for improving T2I generation efficiency through early quality prediction.
TC-Padé: Trajectory-Consistent Padé Approximation for Diffusion Acceleration
Mar 03, 2026Despite achieving state-of-the-art generation quality, diffusion models are hindered by the substantial computational burden of their iterative sampling process. While feature caching techniques achieve effective acceleration at higher step counts (e.g., 50 steps), they exhibit critical limitations in the practical low-step regime of 20-30 steps. As the interval between steps increases, polynomial-based extrapolators like TaylorSeer suffer from error accumulation and trajectory drift. Meanwhile, conventional caching strategies often overlook the distinct dynamical properties of different denoising phases. To address these challenges, we propose Trajectory-Consistent Padé approximation, a feature prediction framework grounded in Padé approximation. By modeling feature evolution through rational functions, our approach captures asymptotic and transitional behaviors more accurately than Taylor-based methods. To enable stable and trajectory-consistent sampling under reduced step counts, TC-Padé incorporates (1) adaptive coefficient modulation that leverages historical cached residuals to detect subtle trajectory transitions, and (2) step-aware prediction strategies tailored to the distinct dynamics of early, mid, and late sampling stages. Extensive experiments on DiT-XL/2, FLUX.1-dev, and Wan2.1 across both image and video generation demonstrate the effectiveness of TC-Padé. For instance, TC-Padé achieves 2.88x acceleration on FLUX.1-dev and 1.72x on Wan2.1 while maintaining high quality across FID, CLIP, Aesthetic, and VBench-2.0 metrics, substantially outperforming existing feature caching methods.
CME-CAD: Heterogeneous Collaborative Multi-Expert Reinforcement Learning for CAD Code Generation
Dec 29, 2025Computer-Aided Design (CAD) is essential in industrial design, but the complexity of traditional CAD modeling and workflows presents significant challenges for automating the generation of high-precision, editable CAD models. Existing methods that reconstruct 3D models from sketches often produce non-editable and approximate models that fall short of meeting the stringent requirements for precision and editability in industrial design. Moreover, the reliance on text or image-based inputs often requires significant manual annotation, limiting their scalability and applicability in industrial settings. To overcome these challenges, we propose the Heterogeneous Collaborative Multi-Expert Reinforcement Learning (CME-CAD) paradigm, a novel training paradigm for CAD code generation. Our approach integrates the complementary strengths of these models, facilitating collaborative learning and improving the model's ability to generate accurate, constraint-compatible, and fully editable CAD models. We introduce a two-stage training process: Multi-Expert Fine-Tuning (MEFT), and Multi-Expert Reinforcement Learning (MERL). Additionally, we present CADExpert, an open-source benchmark consisting of 17,299 instances, including orthographic projections with precise dimension annotations, expert-generated Chain-of-Thought (CoT) processes, executable CADQuery code, and rendered 3D models.
Erase Diffusion: Empowering Object Removal Through Calibrating Diffusion Pathways
Mar 10, 2025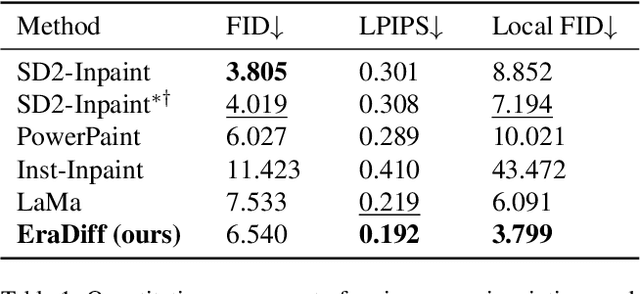
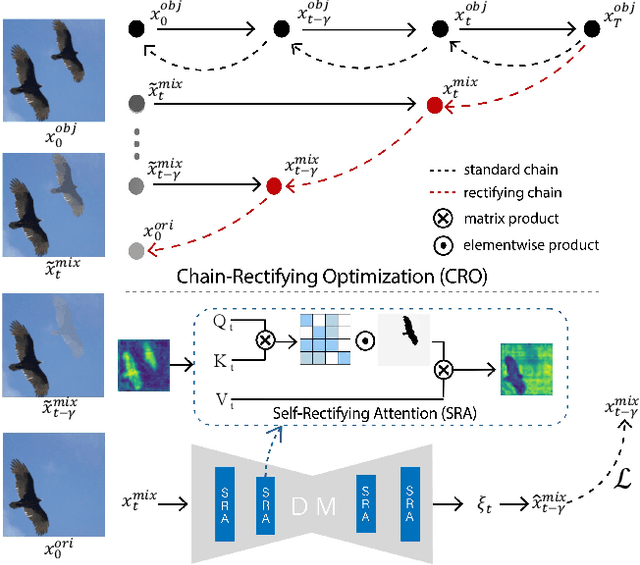
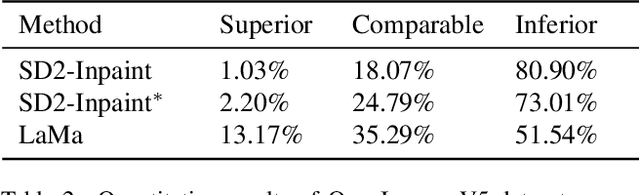

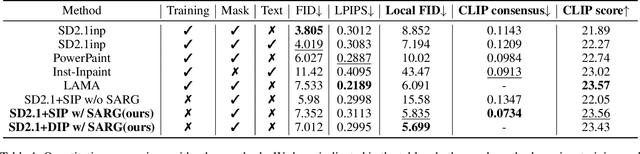
Erase inpainting, or object removal, aims to precisely remove target objects within masked regions while preserving the overall consistency of the surrounding content. Despite diffusion-based methods have made significant strides in the field of image inpainting, challenges remain regarding the emergence of unexpected objects or artifacts. We assert that the inexact diffusion pathways established by existing standard optimization paradigms constrain the efficacy of object removal. To tackle these challenges, we propose a novel Erase Diffusion, termed EraDiff, aimed at unleashing the potential power of standard diffusion in the context of object removal. In contrast to standard diffusion, the EraDiff adapts both the optimization paradigm and the network to improve the coherence and elimination of the erasure results. We first introduce a Chain-Rectifying Optimization (CRO) paradigm, a sophisticated diffusion process specifically designed to align with the objectives of erasure. This paradigm establishes innovative diffusion transition pathways that simulate the gradual elimination of objects during optimization, allowing the model to accurately capture the intent of object removal. Furthermore, to mitigate deviations caused by artifacts during the sampling pathways, we develop a simple yet effective Self-Rectifying Attention (SRA) mechanism. The SRA calibrates the sampling pathways by altering self-attention activation, allowing the model to effectively bypass artifacts while further enhancing the coherence of the generated content. With this design, our proposed EraDiff achieves state-of-the-art performance on the OpenImages V5 dataset and demonstrates significant superiority in real-world scenarios.
Attentive Eraser: Unleashing Diffusion Model's Object Removal Potential via Self-Attention Redirection Guidance
Dec 17, 2024
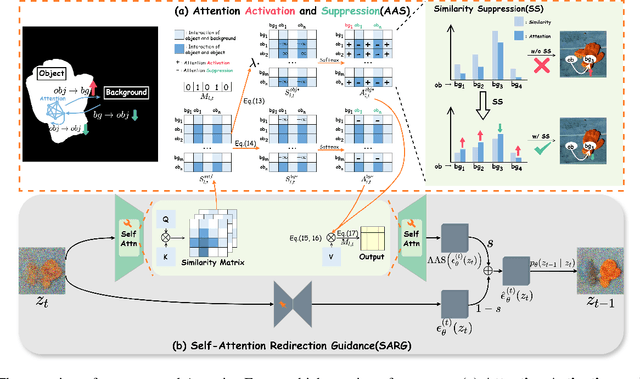
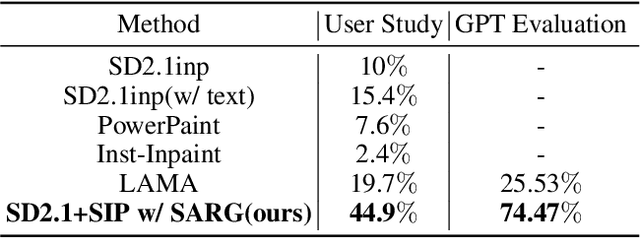
Recently, diffusion models have emerged as promising newcomers in the field of generative models, shining brightly in image generation. However, when employed for object removal tasks, they still encounter issues such as generating random artifacts and the incapacity to repaint foreground object areas with appropriate content after removal. To tackle these problems, we propose Attentive Eraser, a tuning-free method to empower pre-trained diffusion models for stable and effective object removal. Firstly, in light of the observation that the self-attention maps influence the structure and shape details of the generated images, we propose Attention Activation and Suppression (ASS), which re-engineers the self-attention mechanism within the pre-trained diffusion models based on the given mask, thereby prioritizing the background over the foreground object during the reverse generation process. Moreover, we introduce Self-Attention Redirection Guidance (SARG), which utilizes the self-attention redirected by ASS to guide the generation process, effectively removing foreground objects within the mask while simultaneously generating content that is both plausible and coherent. Experiments demonstrate the stability and effectiveness of Attentive Eraser in object removal across a variety of pre-trained diffusion models, outperforming even training-based methods. Furthermore, Attentive Eraser can be implemented in various diffusion model architectures and checkpoints, enabling excellent scalability. Code is available at https://github.com/Anonym0u3/AttentiveEraser.
LiteDepthwiseNet: An Extreme Lightweight Network for Hyperspectral Image Classification
Oct 15, 2020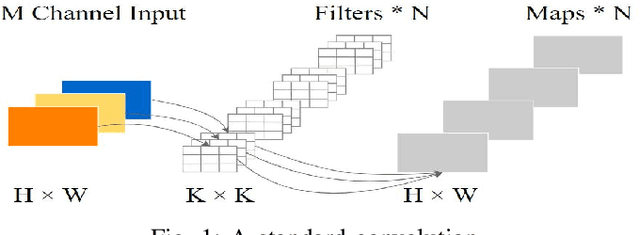
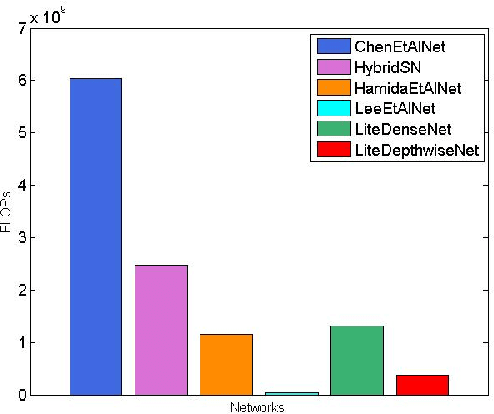
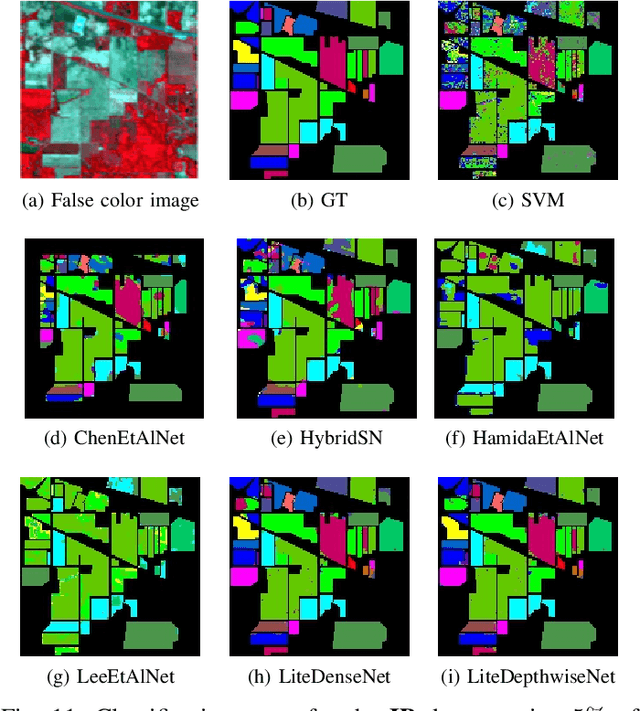
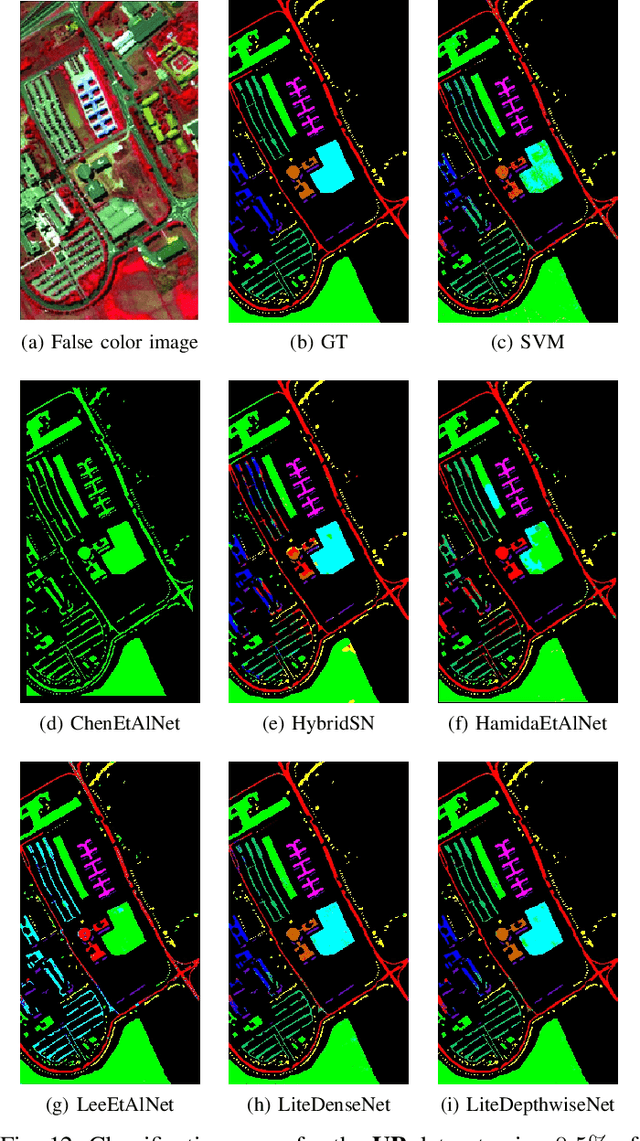
Deep learning methods have shown considerable potential for hyperspectral image (HSI) classification, which can achieve high accuracy compared with traditional methods. However, they often need a large number of training samples and have a lot of parameters and high computational overhead. To solve these problems, this paper proposes a new network architecture, LiteDepthwiseNet, for HSI classification. Based on 3D depthwise convolution, LiteDepthwiseNet can decompose standard convolution into depthwise convolution and pointwise convolution, which can achieve high classification performance with minimal parameters. Moreover, we remove the ReLU layer and Batch Normalization layer in the original 3D depthwise convolution, which significantly improves the overfitting phenomenon of the model on small sized datasets. In addition, focal loss is used as the loss function to improve the model's attention on difficult samples and unbalanced data, and its training performance is significantly better than that of cross-entropy loss or balanced cross-entropy loss. Experiment results on three benchmark hyperspectral datasets show that LiteDepthwiseNet achieves state-of-the-art performance with a very small number of parameters and low computational cost.