 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Sim2Real Gap in User Simulation for Agentic Tasks
Mar 11, 2026As NLP evaluation shifts from static benchmarks to multi-turn interactive settings, LLM-based simulators have become widely used as user proxies, serving two roles: generating user turns and providing evaluation signals. Yet, these simulations are frequently assumed to be faithful to real human behaviors, often without rigorous verification. We formalize the Sim2Real gap in user simulation and present the first study running the full $τ$-bench protocol with real humans (451 participants, 165 tasks), benchmarking 31 LLM simulators across proprietary, open-source, and specialized families using the User-Sim Index (USI), a metric we introduce to quantify how well LLM simulators resemble real user interactive behaviors and feedback. Behaviorally, LLM simulators are excessively cooperative, stylistically uniform, and lack realistic frustration or ambiguity, creating an "easy mode" that inflates agent success rates above the human baseline. In evaluations, real humans provide nuanced judgments across eight quality dimensions while simulated users produce uniformly more positive feedback; rule-based rewards are failing to capture rich feedback signals generated by human users. Overall, higher general model capability does not necessarily yield more faithful user simulation. These findings highlight the importance of human validation when using LLM-based user simulators in the agent development cycle and motivate improved models for user simulation.
GradAlign: Gradient-Aligned Data Selection for LLM Reinforcement Learning
Feb 25, 2026Reinforcement learning (RL) has become a central post-training paradigm for large language models (LLMs), but its performance is highly sensitive to the quality of training problems. This sensitivity stems from the non-stationarity of RL: rollouts are generated by an evolving policy, and learning is shaped by exploration and reward feedback, unlike supervised fine-tuning (SFT) with fixed trajectories. As a result, prior work often relies on manual curation or simple heuristic filters (e.g., accuracy), which can admit incorrect or low-utility problems. We propose GradAlign, a gradient-aligned data selection method for LLM reinforcement learning that uses a small, trusted validation set to prioritize training problems whose policy gradients align with validation gradients, yielding an adaptive curriculum. We evaluate GradAlign across three challenging data regimes: unreliable reward signals, distribution imbalance, and low-utility training corpus, showing that GradAlign consistently outperforms existing baselines, underscoring the importance of directional gradient signals in navigating non-stationary policy optimization and yielding more stable training and improved final performance. We release our implementation at https://github.com/StigLidu/GradAlign
Cross-view Domain Generalization via Geometric Consistency for LiDAR Semantic Segmentation
Feb 16, 2026Domain-generalized LiDAR semantic segmentation (LSS) seeks to train models on source-domain point clouds that generalize reliably to multiple unseen target domains, which is essential for real-world LiDAR applications. However, existing approaches assume similar acquisition views (e.g., vehicle-mounted) and struggle in cross-view scenarios, where observations differ substantially due to viewpoint-dependent structural incompleteness and non-uniform point density. Accordingly, we formulate cross-view domain generalization for LiDAR semantic segmentation and propose a novel framework, termed CVGC (Cross-View Geometric Consistency). Specifically, we introduce a cross-view geometric augmentation module that models viewpoint-induced variations in visibility and sampling density, generating multiple cross-view observations of the same scene. Subsequently, a geometric consistency module enforces consistent semantic and occupancy predictions across geometrically augmented point clouds of the same scene. Extensive experiments on six public LiDAR datasets establish the first systematic evaluation of cross-view domain generalization for LiDAR semantic segmentation, demonstrating that CVGC consistently outperforms state-of-the-art methods when generalizing from a single source domain to multiple target domains with heterogeneous acquisition viewpoints. The source code will be publicly available at https://github.com/KintomZi/CVGC-DG
ReasonRank: Empowering Passage Ranking with Strong Reasoning Ability
Aug 09, 2025Large Language Model (LLM) based listwise ranking has shown superior performance in many passage ranking tasks. With the development of Large Reasoning Models, many studies have demonstrated that step-by-step reasoning during test-time helps improve listwise ranking performance. However, due to the scarcity of reasoning-intensive training data, existing rerankers perform poorly in many complex ranking scenarios and the ranking ability of reasoning-intensive rerankers remains largely underdeveloped. In this paper, we first propose an automated reasoning-intensive training data synthesis framework, which sources training queries and passages from diverse domains and applies DeepSeek-R1 to generate high-quality training labels. A self-consistency data filtering mechanism is designed to ensure the data quality. To empower the listwise reranker with strong reasoning ability, we further propose a two-stage post-training approach, which includes a cold-start supervised fine-tuning (SFT) stage for reasoning pattern learning and a reinforcement learning (RL) stage for further ranking ability enhancement. During the RL stage, based on the nature of listwise ranking, we design a multi-view ranking reward, which is more effective than a ranking metric-based reward. Extensive experiments demonstrate that our trained reasoning-intensive reranker \textbf{ReasonRank} outperforms existing baselines significantly and also achieves much lower latency than pointwise reranker Rank1. \textbf{Through further experiments, our ReasonRank has achieved state-of-the-art (SOTA) performance 40.6 on the BRIGHT leaderboard\footnote{https://brightbenchmark.github.io/}.} Our codes are available at https://github.com/8421BCD/ReasonRank.
Towards Community-Driven Agents for Machine Learning Engineering
Jun 25, 2025Large language model-based machine learning (ML) agents have shown great promise in automating ML research. However, existing agents typically operate in isolation on a given research problem, without engaging with the broader research community, where human researchers often gain insights and contribute by sharing knowledge. To bridge this gap, we introduce MLE-Live, a live evaluation framework designed to assess an agent's ability to communicate with and leverage collective knowledge from a simulated Kaggle research community. Building on this framework, we propose CoMind, a novel agent that excels at exchanging insights and developing novel solutions within a community context. CoMind achieves state-of-the-art performance on MLE-Live and outperforms 79.2% human competitors on average across four ongoing Kaggle competitions. Our code is released at https://github.com/comind-ml/CoMind.
Enhancing Training Data Attribution with Representational Optimization
May 24, 2025Training data attribution (TDA) methods aim to measure how training data impacts a model's predictions. While gradient-based attribution methods, such as influence functions, offer theoretical grounding, their computational costs make them impractical for large-scale applications. Representation-based approaches are far more scalable, but typically rely on heuristic embeddings that are not optimized for attribution, limiting their fidelity. To address these challenges, we propose AirRep, a scalable, representation-based approach that closes this gap by learning task-specific and model-aligned representations optimized explicitly for TDA. AirRep introduces two key innovations: a trainable encoder tuned for attribution quality, and an attention-based pooling mechanism that enables accurate estimation of group-wise influence. We train AirRep using a ranking objective over automatically constructed training subsets labeled by their empirical effect on target predictions. Experiments on instruction-tuned LLMs demonstrate that AirRep achieves performance on par with state-of-the-art gradient-based approaches while being nearly two orders of magnitude more efficient at inference time. Further analysis highlights its robustness and generalization across tasks and models. Our code is available at https://github.com/sunnweiwei/AirRep.
A Comprehensive Evaluation of Contemporary ML-Based Solvers for Combinatorial Optimization
May 22, 2025Machine learning (ML) has demonstrated considerable potential in supporting model design and optimization for combinatorial optimization (CO) problems. However, much of the progress to date has been evaluated on small-scale, synthetic datasets, raising concerns about the practical effectiveness of ML-based solvers in real-world, large-scale CO scenarios. Additionally, many existing CO benchmarks lack sufficient training data, limiting their utility for evaluating data-driven approaches. To address these limitations, we introduce FrontierCO, a comprehensive benchmark that covers eight canonical CO problem types and evaluates 16 representative ML-based solvers--including graph neural networks and large language model (LLM) agents. FrontierCO features challenging instances drawn from industrial applications and frontier CO research, offering both realistic problem difficulty and abundant training data. Our empirical results provide critical insights into the strengths and limitations of current ML methods, helping to guide more robust and practically relevant advances at the intersection of machine learning and combinatorial optimization. Our data is available at https://huggingface.co/datasets/CO-Bench/FrontierCO.
Solving Normalized Cut Problem with Constrained Action Space
May 20, 2025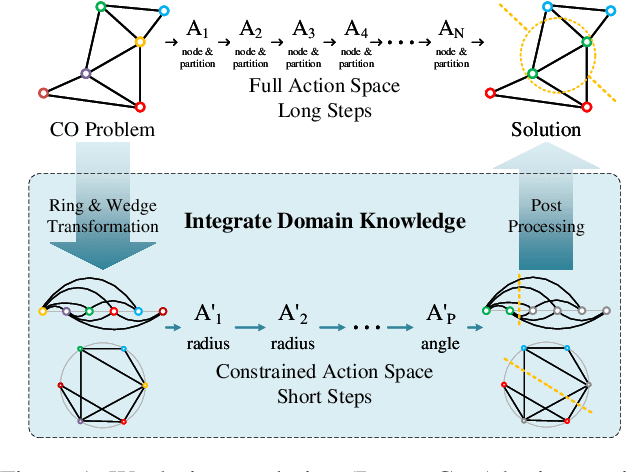
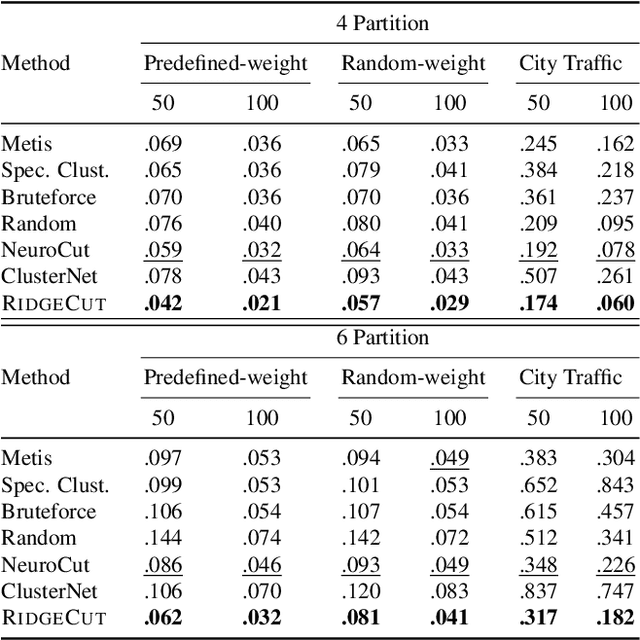
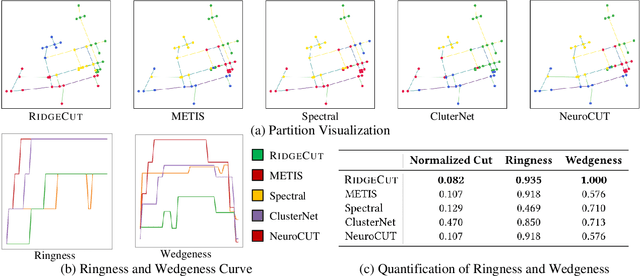
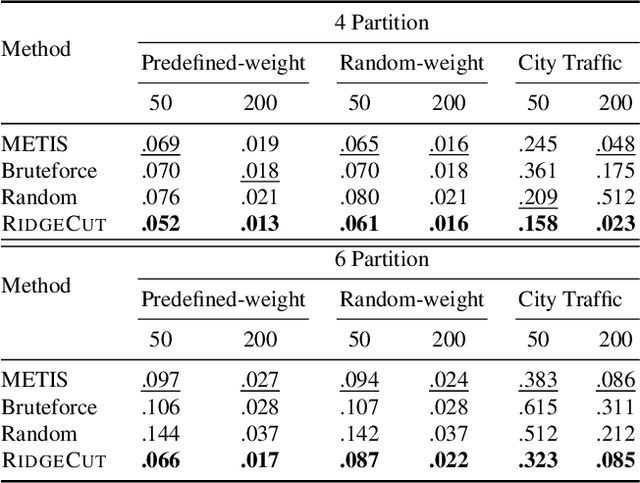
Reinforcement Learning (RL) has emerged as an important paradigm to solve combinatorial optimization problems primarily due to its ability to learn heuristics that can generalize across problem instances. However, integrating external knowledge that will steer combinatorial optimization problem solutions towards domain appropriate outcomes remains an extremely challenging task. In this paper, we propose the first RL solution that uses constrained action spaces to guide the normalized cut problem towards pre-defined template instances. Using transportation networks as an example domain, we create a Wedge and Ring Transformer that results in graph partitions that are shaped in form of Wedges and Rings and which are likely to be closer to natural optimal partitions. However, our approach is general as it is based on principles that can be generalized to other domains.
Learning Spatio-Temporal Dynamics for Trajectory Recovery via Time-Aware Transformer
May 20, 2025In real-world applications, GPS trajectories often suffer from low sampling rates, with large and irregular intervals between consecutive GPS points. This sparse characteristic presents challenges for their direct use in GPS-based systems. This paper addresses the task of map-constrained trajectory recovery, aiming to enhance trajectory sampling rates of GPS trajectories. Previous studies commonly adopt a sequence-to-sequence framework, where an encoder captures the trajectory patterns and a decoder reconstructs the target trajectory. Within this framework, effectively representing the road network and extracting relevant trajectory features are crucial for overall performance. Despite advancements in these models, they fail to fully leverage the complex spatio-temporal dynamics present in both the trajectory and the road network. To overcome these limitations, we categorize the spatio-temporal dynamics of trajectory data into two distinct aspects: spatial-temporal traffic dynamics and trajectory dynamics. Furthermore, We propose TedTrajRec, a novel method for trajectory recovery. To capture spatio-temporal traffic dynamics, we introduce PD-GNN, which models periodic patterns and learns topologically aware dynamics concurrently for each road segment. For spatio-temporal trajectory dynamics, we present TedFormer, a time-aware Transformer that incorporates temporal dynamics for each GPS location by integrating closed-form neural ordinary differential equations into the attention mechanism. This allows TedFormer to effectively handle irregularly sampled data. Extensive experiments on three real-world datasets demonstrate the superior performance of TedTrajRec. The code is publicly available at https://github.com/ysygMhdxw/TEDTrajRec/.
CodePDE: An Inference Framework for LLM-driven PDE Solver Generation
May 13, 2025Partial differential equations (PDEs) are fundamental to modeling physical systems, yet solving them remains a complex challenge. Traditional numerical solvers rely on expert knowledge to implement and are computationally expensive, while neural-network-based solvers require large training datasets and often lack interpretability. In this work, we frame PDE solving as a code generation task and introduce CodePDE, the first inference framework for generating PDE solvers using large language models (LLMs). Leveraging advanced inference-time algorithms and scaling strategies, CodePDE unlocks critical capacities of LLM for PDE solving: reasoning, debugging, selfrefinement, and test-time scaling -- all without task-specific tuning. CodePDE achieves superhuman performance across a range of representative PDE problems. We also present a systematic empirical analysis of LLM generated solvers, analyzing their accuracy, efficiency, and numerical scheme choices. Our findings highlight the promise and the current limitations of LLMs in PDE solving, offering a new perspective on solver design and opportunities for future model development. Our code is available at https://github.com/LithiumDA/CodePDE.