 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARFBench: Benchmarking Time Series Question Answering Ability for Software Incident Response
Apr 23, 2026Time series question-answering (TSQA), in which we ask natural language questions to infer and reason about properties of time series, is a promising yet underexplored capability of foundation models. In this work, we present ARFBench, a TSQA benchmark that evaluates the understanding of multimodal foundation models (FMs) on time series anomalies prevalent in software incident data. ARFBench consists of 750 questions across 142 time series and 5.38M data points from 63 production incidents sourced exclusively from internal telemetry at Datadog. We evaluate leading proprietary and open-source LLMs, VLMs, and time series FMs and observe that frontier VLMs perform markedly better than existing baselines; the leading model (GPT-5) achieves a 62.7% accuracy and 51.9% F1. We next demonstrate the promise of specialized multimodal approaches. We develop a novel TSFM + VLM hybrid prototype which we post-train on a small set of synthetic and real data that yields comparable overall F1 and accuracy with frontier models. Lastly, we find models and human domain experts exhibit complementary strengths. We define a model-expert oracle, a best-of-2 oracle selector over model and expert answers, yielding 82.8% F1 and 87.2% accuracy and establishing a new superhuman frontier for future TSQA models. The benchmark is available at https://huggingface.co/datasets/Datadog/ARFBench.
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Thinking vs. Doing: Agents that Reason by Scaling Test-Time Interaction
Jun 09, 2025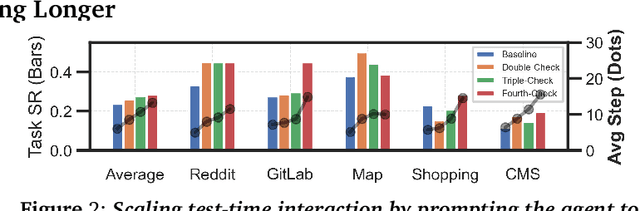
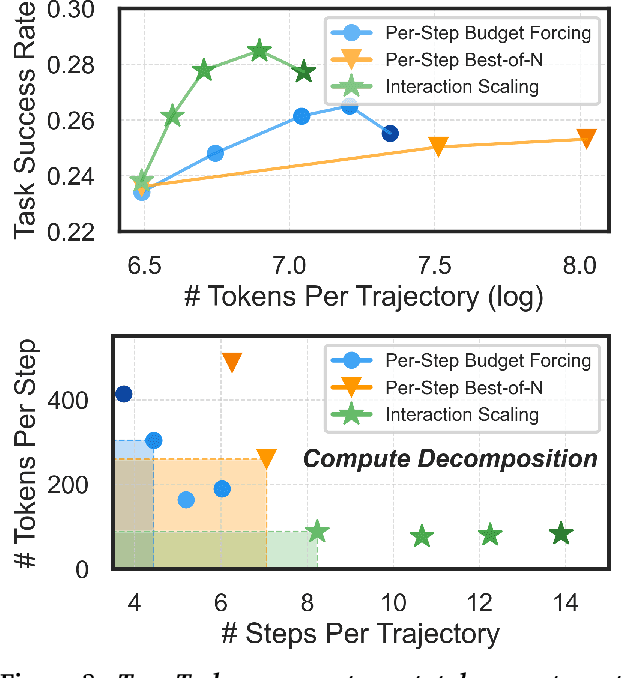
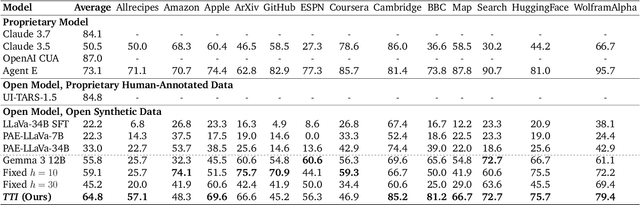
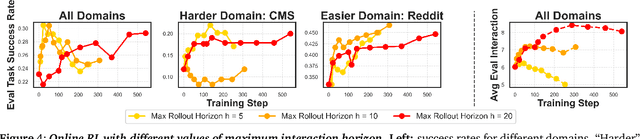
The current paradigm of test-time scaling relies on generating long reasoning traces ("thinking" more) before producing a response. In agent problems that require interaction, this can be done by generating thinking traces before acting in the world. However, this process does not allow agents to acquire new information from the environment or adapt their behavior over time. In this work, we propose to scale test-time interaction, an untapped dimension of test-time scaling that increases the agent's interaction horizon to enable running rich behaviors such as exploration, backtracking, and dynamic re-planning within a single rollout. To demonstrate the promise of this scaling dimension, we study the domain of web agents. We first show that even prompting-based interaction scaling without any training can improve task success on web benchmarks non-trivially. Building on this, we introduce TTI (Test-Time Interaction), a curriculum-based online reinforcement learning (RL) approach that trains agents by adaptively adjusting their rollout lengths. Using a Gemma 3 12B model, TTI produces state-of-the-art open-source, open-data web agents on WebVoyager and WebArena benchmarks. We further show that TTI enables agents to balance exploration and exploitation adaptively. Our results establish interaction scaling as a powerful, complementary axis to scaling per-step compute, offering new avenues for training adaptive agents.
CodePDE: An Inference Framework for LLM-driven PDE Solver Generation
May 13, 2025Partial differential equations (PDEs) are fundamental to modeling physical systems, yet solving them remains a complex challenge. Traditional numerical solvers rely on expert knowledge to implement and are computationally expensive, while neural-network-based solvers require large training datasets and often lack interpretability. In this work, we frame PDE solving as a code generation task and introduce CodePDE, the first inference framework for generating PDE solvers using large language models (LLMs). Leveraging advanced inference-time algorithms and scaling strategies, CodePDE unlocks critical capacities of LLM for PDE solving: reasoning, debugging, selfrefinement, and test-time scaling -- all without task-specific tuning. CodePDE achieves superhuman performance across a range of representative PDE problems. We also present a systematic empirical analysis of LLM generated solvers, analyzing their accuracy, efficiency, and numerical scheme choices. Our findings highlight the promise and the current limitations of LLMs in PDE solving, offering a new perspective on solver design and opportunities for future model development. Our code is available at https://github.com/LithiumDA/CodePDE.
Mixture-of-Mamba: Enhancing Multi-Modal State-Space Models with Modality-Aware Sparsity
Jan 27, 2025



State Space Models (SSMs) have emerged as efficient alternatives to Transformers for sequential modeling, but their inability to leverage modality-specific features limits their performance in multi-modal pretraining. Here, we propose Mixture-of-Mamba, a novel SSM architecture that introduces modality-aware sparsity through modality-specific parameterization of the Mamba block. Building on Mixture-of-Transformers (W. Liang et al. arXiv:2411.04996; 2024), we extend the benefits of modality-aware sparsity to SSMs while preserving their computational efficiency. We evaluate Mixture-of-Mamba across three multi-modal pretraining settings: Transfusion (interleaved text and continuous image tokens with diffusion loss), Chameleon (interleaved text and discrete image tokens), and an extended three-modality framework incorporating speech. Mixture-of-Mamba consistently reaches the same loss values at earlier training steps with significantly reduced computational costs. In the Transfusion setting, Mixture-of-Mamba achieves equivalent image loss using only 34.76% of the training FLOPs at the 1.4B scale. In the Chameleon setting, Mixture-of-Mamba reaches similar image loss with just 42.50% of the FLOPs at the 1.4B scale, and similar text loss with just 65.40% of the FLOPs. In the three-modality setting, MoM matches speech loss at 24.80% of the FLOPs at the 1.4B scale. Our ablation study highlights the synergistic effects of decoupling projection components, where joint decoupling yields greater gains than individual modifications. These results establish modality-aware sparsity as a versatile and effective design principle, extending its impact from Transformers to SSMs and setting new benchmarks in multi-modal pretraining. Our code can be accessed at https://github.com/Weixin-Liang/Mixture-of-Mamba
CAT: Content-Adaptive Image Tokenization
Jan 06, 2025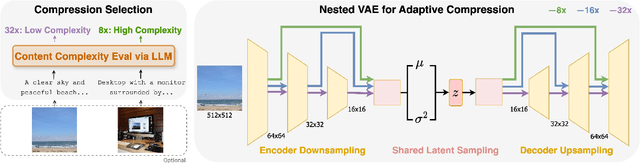



Most existing image tokenizers encode images into a fixed number of tokens or patches, overlooking the inherent variability in image complexity. To address this, we introduce Content-Adaptive Tokenizer (CAT), which dynamically adjusts representation capacity based on the image content and encodes simpler images into fewer tokens. We design a caption-based evaluation system that leverages large language models (LLMs) to predict content complexity and determine the optimal compression ratio for a given image, taking into account factors critical to human perception. Trained on images with diverse compression ratios, CAT demonstrates robust performance in image reconstruction. We also utilize its variable-length latent representations to train Diffusion Transformers (DiTs) for ImageNet generation. By optimizing token allocation, CAT improves the FID score over fixed-ratio baselines trained with the same flops and boosts the inference throughput by 18.5%.
ScribeAgent: Towards Specialized Web Agents Using Production-Scale Workflow Data
Nov 22, 2024



Large Language Model (LLM) agents are rapidly improving to handle increasingly complex web-based tasks. Most of these agents rely on general-purpose, proprietary models like GPT-4 and focus on designing better prompts to improve their planning abilities. However, general-purpose LLMs are not specifically trained to understand specialized web contexts such as HTML, and they often struggle with long-horizon planning. We explore an alternative approach that fine-tunes open-source LLMs using production-scale workflow data collected from over 250 domains corresponding to 6 billion tokens. This simple yet effective approach shows substantial gains over prompting-based agents on existing benchmarks -- ScribeAgent achieves state-of-the-art direct generation performance on Mind2Web and improves the task success rate by 14.1% over the previous best text-only web agents on WebArena. We further perform detailed ablation studies on various fine-tuning design choices and provide insights into LLM selection, training recipes, context window optimization, and effect of dataset sizes.
Specialized Foundation Models Struggle to Beat Supervised Baselines
Nov 05, 2024



Following its success for vision and text, the "foundation model" (FM) paradigm -- pretraining large models on massive data, then fine-tuning on target tasks -- has rapidly expanded to domains in the sciences, engineering, healthcare, and beyond. Has this achieved what the original FMs accomplished, i.e. the supplanting of traditional supervised learning in their domains? To answer we look at three modalities -- genomics, satellite imaging, and time series -- with multiple recent FMs and compare them to a standard supervised learning workflow: model development, hyperparameter tuning, and training, all using only data from the target task. Across these three specialized domains, we find that it is consistently possible to train simple supervised models -- no more complicated than a lightly modified wide ResNet or UNet -- that match or even outperform the latest foundation models. Our work demonstrates that the benefits of large-scale pretraining have yet to be realized in many specialized areas, reinforces the need to compare new FMs to strong, well-tuned baselines, and introduces two new, easy-to-use, open-source, and automated workflows for doing so.
UPS: Towards Foundation Models for PDE Solving via Cross-Modal Adaptation
Mar 11, 2024



We introduce UPS (Unified PDE Solver), an effective and data-efficient approach to solve diverse spatiotemporal PDEs defined over various domains, dimensions, and resolutions. UPS unifies different PDEs into a consistent representation space and processes diverse collections of PDE data using a unified network architecture that combines LLMs with domain-specific neural operators. We train the network via a two-stage cross-modal adaptation process, leveraging ideas of modality alignment and multi-task learning. By adapting from pretrained LLMs and exploiting text-form meta information, we are able to use considerably fewer training samples than previous methods while obtaining strong empirical results. UPS outperforms existing baselines, often by a large margin, on a wide range of 1D and 2D datasets in PDEBench, achieving state-of-the-art results on 8 of 10 tasks considered. Meanwhile, it is capable of few-shot transfer to different PDE families, coefficients, and resolutions.
Tag-LLM: Repurposing General-Purpose LLMs for Specialized Domains
Feb 06, 2024


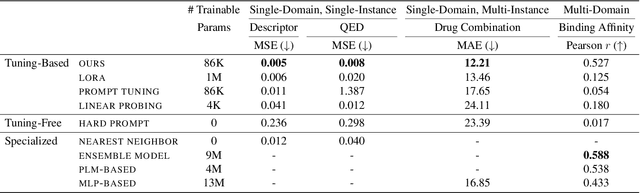
Large Language Models (LLMs) have demonstrated remarkable proficiency in understanding and generating natural language. However, their capabilities wane in highly specialized domains underrepresented in the pretraining corpus, such as physical and biomedical sciences. This work explores how to repurpose general LLMs into effective task solvers for specialized domains. We introduce a novel, model-agnostic framework for learning custom input tags, which are parameterized as continuous vectors appended to the LLM's embedding layer, to condition the LLM. We design two types of input tags: domain tags are used to delimit specialized representations (e.g., chemical formulas) and provide domain-relevant context; function tags are used to represent specific functions (e.g., predicting molecular properties) and compress function-solving instructions. We develop a three-stage protocol to learn these tags using auxiliary data and domain knowledge. By explicitly disentangling task domains from task functions, our method enables zero-shot generalization to unseen problems through diverse combinations of the input tags. It also boosts LLM's performance in various specialized domains, such as predicting protein or chemical properties and modeling drug-target interactions, outperforming expert models tailored to these tasks.