 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalizable Robotic Data Flywheel: High-Dimensional Factorization and Composition
Mar 26, 2026The lack of sufficiently diverse data, coupled with limited data efficiency, remains a major bottleneck for generalist robotic models, yet systematic strategies for collecting and curating such data are not fully explored. Task diversity arises from implicit factors that are sparsely distributed across multiple dimensions and are difficult to define explicitly. To address this challenge, we propose F-ACIL, a heuristic factor-aware compositional iterative learning framework that enables structured data factorization and promotes compositional generalization. F-ACIL decomposes the data distribution into structured factor spaces such as object, action, and environment. Based on the factorized formulation, we develop a factor-wise data collection and an iterative training paradigm that promotes compositional generalization over the high-dimensional factor space, leading to more effective utilization of real-world robotic demonstrations. With extensive real-world experiments, we show that F-ACIL can achieve more than 45% performance gains with 5-10$\times$ fewer demonstrations comparing to that of which without the strategy. The results suggest that structured factorization offers a practical pathway toward efficient compositional generalization in real-world robotic learning. We believe F-ACIL can inspire more systematic research on building generalizable robotic data flywheel strategies. More demonstrations can be found at: https://f-acil.github.io/
GR-Dexter Technical Report
Dec 30, 2025Vision-language-action (VLA) models have enabled language-conditioned, long-horizon robot manipulation, but most existing systems are limited to grippers. Scaling VLA policies to bimanual robots with high degree-of-freedom (DoF) dexterous hands remains challenging due to the expanded action space, frequent hand-object occlusions, and the cost of collecting real-robot data. We present GR-Dexter, a holistic hardware-model-data framework for VLA-based generalist manipulation on a bimanual dexterous-hand robot. Our approach combines the design of a compact 21-DoF robotic hand, an intuitive bimanual teleoperation system for real-robot data collection, and a training recipe that leverages teleoperated robot trajectories together with large-scale vision-language and carefully curated cross-embodiment datasets. Across real-world evaluations spanning long-horizon everyday manipulation and generalizable pick-and-place, GR-Dexter achieves strong in-domain performance and improved robustness to unseen objects and unseen instructions. We hope GR-Dexter serves as a practical step toward generalist dexterous-hand robotic manipulation.
FactorHD: A Hyperdimensional Computing Model for Multi-Object Multi-Class Representation and Factorization
Jul 16, 2025Neuro-symbolic artificial intelligence (neuro-symbolic AI) excels in logical analysis and reasoning. Hyperdimensional Computing (HDC), a promising brain-inspired computational model, is integral to neuro-symbolic AI. Various HDC models have been proposed to represent class-instance and class-class relations, but when representing the more complex class-subclass relation, where multiple objects associate different levels of classes and subclasses, they face challenges for factorization, a crucial task for neuro-symbolic AI systems. In this article, we propose FactorHD, a novel HDC model capable of representing and factorizing the complex class-subclass relation efficiently. FactorHD features a symbolic encoding method that embeds an extra memorization clause, preserving more information for multiple objects. In addition, it employs an efficient factorization algorithm that selectively eliminates redundant classes by identifying the memorization clause of the target class. Such model significantly enhances computing efficiency and accuracy in representing and factorizing multiple objects with class-subclass relation, overcoming limitations of existing HDC models such as "superposition catastrophe" and "the problem of 2". Evaluations show that FactorHD achieves approximately 5667x speedup at a representation size of 10^9 compared to existing HDC models. When integrated with the ResNet-18 neural network, FactorHD achieves 92.48% factorization accuracy on the Cifar-10 dataset.
Thinking vs. Doing: Agents that Reason by Scaling Test-Time Interaction
Jun 09, 2025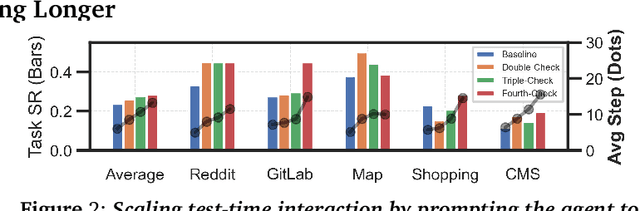
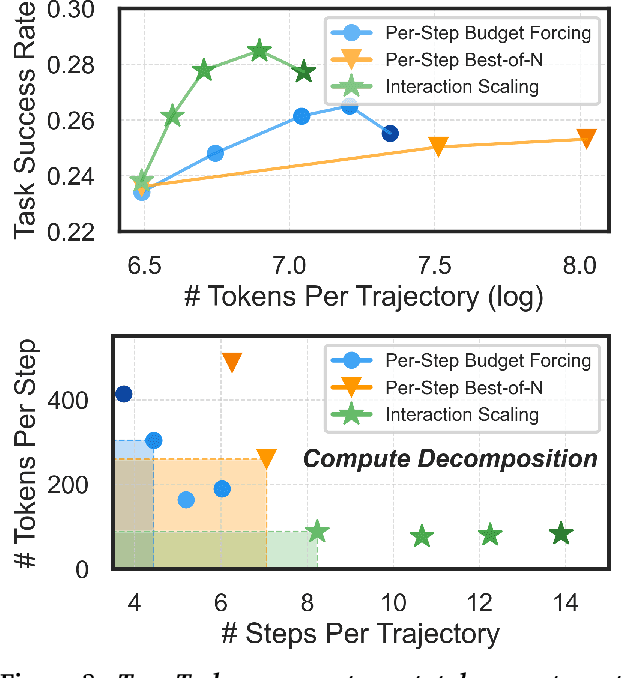
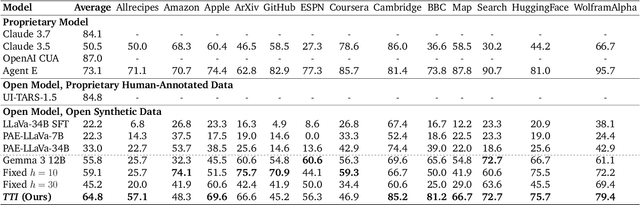
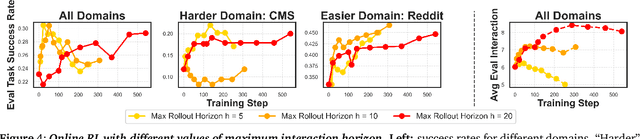
The current paradigm of test-time scaling relies on generating long reasoning traces ("thinking" more) before producing a response. In agent problems that require interaction, this can be done by generating thinking traces before acting in the world. However, this process does not allow agents to acquire new information from the environment or adapt their behavior over time. In this work, we propose to scale test-time interaction, an untapped dimension of test-time scaling that increases the agent's interaction horizon to enable running rich behaviors such as exploration, backtracking, and dynamic re-planning within a single rollout. To demonstrate the promise of this scaling dimension, we study the domain of web agents. We first show that even prompting-based interaction scaling without any training can improve task success on web benchmarks non-trivially. Building on this, we introduce TTI (Test-Time Interaction), a curriculum-based online reinforcement learning (RL) approach that trains agents by adaptively adjusting their rollout lengths. Using a Gemma 3 12B model, TTI produces state-of-the-art open-source, open-data web agents on WebVoyager and WebArena benchmarks. We further show that TTI enables agents to balance exploration and exploitation adaptively. Our results establish interaction scaling as a powerful, complementary axis to scaling per-step compute, offering new avenues for training adaptive agents.
Learning Adaptive Parallel Reasoning with Language Models
Apr 21, 2025Scaling inference-time computation has substantially improved the reasoning capabilities of language models. However, existing methods have significant limitations: serialized chain-of-thought approaches generate overly long outputs, leading to increased latency and exhausted context windows, while parallel methods such as self-consistency suffer from insufficient coordination, resulting in redundant computations and limited performance gains. To address these shortcomings, we propose Adaptive Parallel Reasoning (APR), a novel reasoning framework that enables language models to orchestrate both serialized and parallel computations end-to-end. APR generalizes existing reasoning methods by enabling adaptive multi-threaded inference using spawn() and join() operations. A key innovation is our end-to-end reinforcement learning strategy, optimizing both parent and child inference threads to enhance task success rate without requiring predefined reasoning structures. Experiments on the Countdown reasoning task demonstrate significant benefits of APR: (1) higher performance within the same context window (83.4% vs. 60.0% at 4k context); (2) superior scalability with increased computation (80.1% vs. 66.6% at 20k total tokens); (3) improved accuracy at equivalent latency (75.2% vs. 57.3% at approximately 5,000ms). APR represents a step towards enabling language models to autonomously optimize their reasoning processes through adaptive allocation of computation.
SWEET-RL: Training Multi-Turn LLM Agents on Collaborative Reasoning Tasks
Mar 19, 2025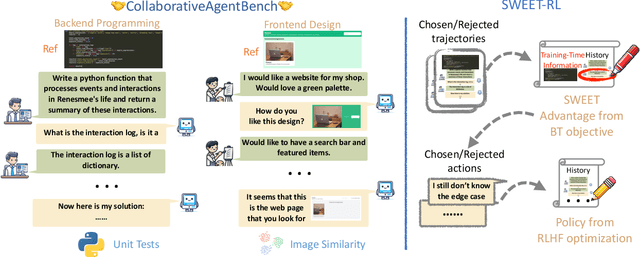
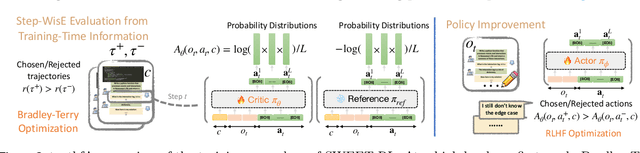
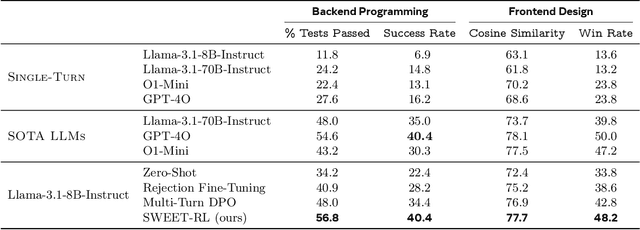
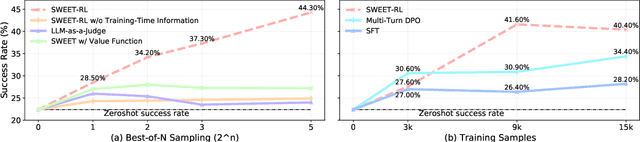
Large language model (LLM) agents need to perform multi-turn interactions in real-world tasks. However, existing multi-turn RL algorithms for optimizing LLM agents fail to perform effective credit assignment over multiple turns while leveraging the generalization capabilities of LLMs and it remains unclear how to develop such algorithms. To study this, we first introduce a new benchmark, ColBench, where an LLM agent interacts with a human collaborator over multiple turns to solve realistic tasks in backend programming and frontend design. Building on this benchmark, we propose a novel RL algorithm, SWEET-RL (RL with Step-WisE Evaluation from Training-time information), that uses a carefully designed optimization objective to train a critic model with access to additional training-time information. The critic provides step-level rewards for improving the policy model. Our experiments demonstrate that SWEET-RL achieves a 6% absolute improvement in success and win rates on ColBench compared to other state-of-the-art multi-turn RL algorithms, enabling Llama-3.1-8B to match or exceed the performance of GPT4-o in realistic collaborative content creation.
Proposer-Agent-Evaluator(PAE): Autonomous Skill Discovery For Foundation Model Internet Agents
Dec 17, 2024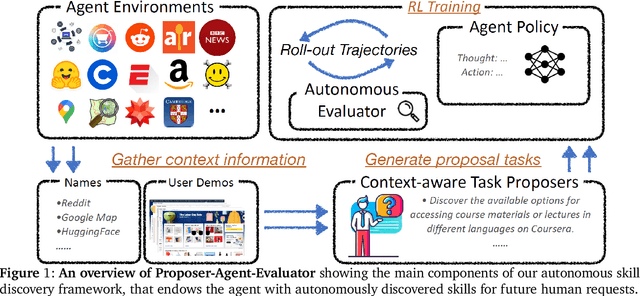
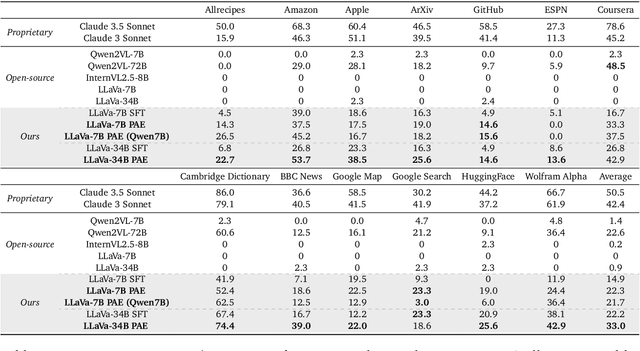
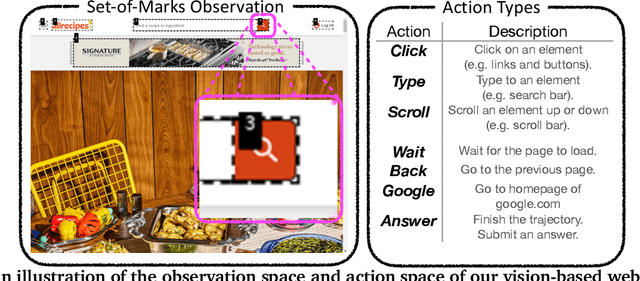
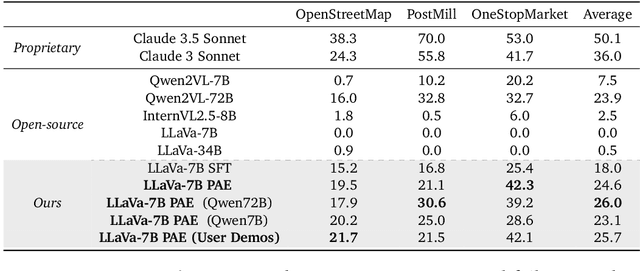
The vision of a broadly capable and goal-directed agent, such as an Internet-browsing agent in the digital world and a household humanoid in the physical world, has rapidly advanced, thanks to the generalization capability of foundation models. Such a generalist agent needs to have a large and diverse skill repertoire, such as finding directions between two travel locations and buying specific items from the Internet. If each skill needs to be specified manually through a fixed set of human-annotated instructions, the agent's skill repertoire will necessarily be limited due to the quantity and diversity of human-annotated instructions. In this work, we address this challenge by proposing Proposer-Agent-Evaluator, an effective learning system that enables foundation model agents to autonomously discover and practice skills in the wild. At the heart of PAE is a context-aware task proposer that autonomously proposes tasks for the agent to practice with context information of the environment such as user demos or even just the name of the website itself for Internet-browsing agents. Then, the agent policy attempts those tasks with thoughts and actual grounded operations in the real world with resulting trajectories evaluated by an autonomous VLM-based success evaluator. The success evaluation serves as the reward signal for the agent to refine its policies through RL. We validate PAE on challenging vision-based web navigation, using both real-world and self-hosted websites from WebVoyager and WebArena.To the best of our knowledge, this work represents the first effective learning system to apply autonomous task proposal with RL for agents that generalizes real-world human-annotated benchmarks with SOTA performances. Our open-source checkpoints and code can be found in https://yanqval.github.io/PAE/
KALIE: Fine-Tuning Vision-Language Models for Open-World Manipulation without Robot Data
Sep 21, 2024
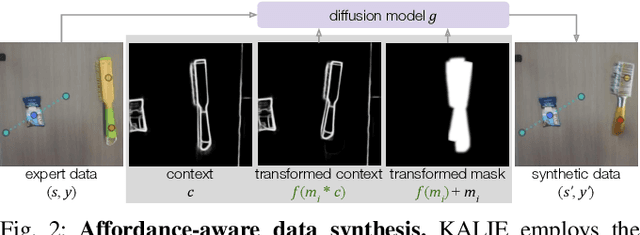


Building generalist robotic systems involves effectively endowing robots with the capabilities to handle novel objects in an open-world setting. Inspired by the advances of large pre-trained models, we propose Keypoint Affordance Learning from Imagined Environments (KALIE), which adapts pre-trained Vision Language Models (VLMs) for robotic control in a scalable manner. Instead of directly producing motor commands, KALIE controls the robot by predicting point-based affordance representations based on natural language instructions and visual observations of the scene. The VLM is trained on 2D images with affordances labeled by humans, bypassing the need for training data collected on robotic systems. Through an affordance-aware data synthesis pipeline, KALIE automatically creates massive high-quality training data based on limited example data manually collected by humans. We demonstrate that KALIE can learn to robustly solve new manipulation tasks with unseen objects given only 50 example data points. Compared to baselines using pre-trained VLMs, our approach consistently achieves superior performance.
DigiRL: Training In-The-Wild Device-Control Agents with Autonomous Reinforcement Learning
Jun 14, 2024Training corpuses for vision language models (VLMs) typically lack sufficient amounts of decision-centric data. This renders off-the-shelf VLMs sub-optimal for decision-making tasks such as in-the-wild device control through graphical user interfaces (GUIs). While training with static demonstrations has shown some promise, we show that such methods fall short for controlling real GUIs due to their failure to deal with real-world stochasticity and non-stationarity not captured in static observational data. This paper introduces a novel autonomous RL approach, called DigiRL, for training in-the-wild device control agents through fine-tuning a pre-trained VLM in two stages: offline RL to initialize the model, followed by offline-to-online RL. To do this, we build a scalable and parallelizable Android learning environment equipped with a VLM-based evaluator and develop a simple yet effective RL approach for learning in this domain. Our approach runs advantage-weighted RL with advantage estimators enhanced to account for stochasticity along with an automatic curriculum for deriving maximal learning signal. We demonstrate the effectiveness of DigiRL using the Android-in-the-Wild (AitW) dataset, where our 1.3B VLM trained with RL achieves a 49.5% absolute improvement -- from 17.7 to 67.2% success rate -- over supervised fine-tuning with static human demonstration data. These results significantly surpass not only the prior best agents, including AppAgent with GPT-4V (8.3% success rate) and the 17B CogAgent trained with AitW data (38.5%), but also the prior best autonomous RL approach based on filtered behavior cloning (57.8%), thereby establishing a new state-of-the-art for digital agents for in-the-wild device control.
Fine-Tuning Large Vision-Language Models as Decision-Making Agents via Reinforcement Learning
May 17, 2024



Large vision-language models (VLMs) fine-tuned on specialized visual instruction-following data have exhibited impressive language reasoning capabilities across various scenarios. However, this fine-tuning paradigm may not be able to efficiently learn optimal decision-making agents in multi-step goal-directed tasks from interactive environments. To address this challenge, we propose an algorithmic framework that fine-tunes VLMs with reinforcement learning (RL). Specifically, our framework provides a task description and then prompts the VLM to generate chain-of-thought (CoT) reasoning, enabling the VLM to efficiently explore intermediate reasoning steps that lead to the final text-based action. Next, the open-ended text output is parsed into an executable action to interact with the environment to obtain goal-directed task rewards. Finally, our framework uses these task rewards to fine-tune the entire VLM with RL. Empirically, we demonstrate that our proposed framework enhances the decision-making capabilities of VLM agents across various tasks, enabling 7b models to outperform commercial models such as GPT4-V or Gemini. Furthermore, we find that CoT reasoning is a crucial component for performance improvement, as removing the CoT reasoning results in a significant decrease in the overall performance of our method.