 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Space Complexity of Learning-Unlearning Algorithms
Jun 16, 2025We study the memory complexity of machine unlearning algorithms that provide strong data deletion guarantees to the users. Formally, consider an algorithm for a particular learning task that initially receives a training dataset. Then, after learning, it receives data deletion requests from a subset of users (of arbitrary size), and the goal of unlearning is to perform the task as if the learner never received the data of deleted users. In this paper, we ask how many bits of storage are needed to be able to delete certain training samples at a later time. We focus on the task of realizability testing, where the goal is to check whether the remaining training samples are realizable within a given hypothesis class \(\mathcal{H}\). Toward that end, we first provide a negative result showing that the VC dimension is not a characterization of the space complexity of unlearning. In particular, we provide a hypothesis class with constant VC dimension (and Littlestone dimension), but for which any unlearning algorithm for realizability testing needs to store \(\Omega(n)\)-bits, where \(n\) denotes the size of the initial training dataset. In fact, we provide a stronger separation by showing that for any hypothesis class \(\mathcal{H}\), the amount of information that the learner needs to store, so as to perform unlearning later, is lower bounded by the \textit{eluder dimension} of \(\mathcal{H}\), a combinatorial notion always larger than the VC dimension. We complement the lower bound with an upper bound in terms of the star number of the underlying hypothesis class, albeit in a stronger ticketed-memory model proposed by Ghazi et al. (2023). Since the star number for a hypothesis class is never larger than its Eluder dimension, our work highlights a fundamental separation between central and ticketed memory models for machine unlearning.
UCD: Unlearning in LLMs via Contrastive Decoding
Jun 12, 2025Machine unlearning aims to remove specific information, e.g. sensitive or undesirable content, from large language models (LLMs) while preserving overall performance. We propose an inference-time unlearning algorithm that uses contrastive decoding, leveraging two auxiliary smaller models, one trained without the forget set and one trained with it, to guide the outputs of the original model using their difference during inference. Our strategy substantially improves the tradeoff between unlearning effectiveness and model utility. We evaluate our approach on two unlearning benchmarks, TOFU and MUSE. Results show notable gains in both forget quality and retained performance in comparison to prior approaches, suggesting that incorporating contrastive decoding can offer an efficient, practical avenue for unlearning concepts in large-scale models.
System-Aware Unlearning Algorithms: Use Lesser, Forget Faster
Jun 06, 2025Machine unlearning addresses the problem of updating a machine learning model/system trained on a dataset $S$ so that the influence of a set of deletion requests $U \subseteq S$ on the unlearned model is minimized. The gold standard definition of unlearning demands that the updated model, after deletion, be nearly identical to the model obtained by retraining. This definition is designed for a worst-case attacker (one who can recover not only the unlearned model but also the remaining data samples, i.e., $S \setminus U$). Such a stringent definition has made developing efficient unlearning algorithms challenging. However, such strong attackers are also unrealistic. In this work, we propose a new definition, system-aware unlearning, which aims to provide unlearning guarantees against an attacker that can at best only gain access to the data stored in the system for learning/unlearning requests and not all of $S\setminus U$. With this new definition, we use the simple intuition that if a system can store less to make its learning/unlearning updates, it can be more secure and update more efficiently against a system-aware attacker. Towards that end, we present an exact system-aware unlearning algorithm for linear classification using a selective sampling-based approach, and we generalize the method for classification with general function classes. We theoretically analyze the tradeoffs between deletion capacity, accuracy, memory, and computation time.
The Gaussian Mixing Mechanism: Renyi Differential Privacy via Gaussian Sketches
May 30, 2025Gaussian sketching, which consists of pre-multiplying the data with a random Gaussian matrix, is a widely used technique for multiple problems in data science and machine learning, with applications spanning computationally efficient optimization, coded computing, and federated learning. This operation also provides differential privacy guarantees due to its inherent randomness. In this work, we revisit this operation through the lens of Renyi Differential Privacy (RDP), providing a refined privacy analysis that yields significantly tighter bounds than prior results. We then demonstrate how this improved analysis leads to performance improvement in different linear regression settings, establishing theoretical utility guarantees. Empirically, our methods improve performance across multiple datasets and, in several cases, reduce runtime.
The Role of Environment Access in Agnostic Reinforcement Learning
Apr 07, 2025We study Reinforcement Learning (RL) in environments with large state spaces, where function approximation is required for sample-efficient learning. Departing from a long history of prior work, we consider the weakest possible form of function approximation, called agnostic policy learning, where the learner seeks to find the best policy in a given class $\Pi$, with no guarantee that $\Pi$ contains an optimal policy for the underlying task. Although it is known that sample-efficient agnostic policy learning is not possible in the standard online RL setting without further assumptions, we investigate the extent to which this can be overcome with stronger forms of access to the environment. Specifically, we show that: 1. Agnostic policy learning remains statistically intractable when given access to a local simulator, from which one can reset to any previously seen state. This result holds even when the policy class is realizable, and stands in contrast to a positive result of [MFR24] showing that value-based learning under realizability is tractable with local simulator access. 2. Agnostic policy learning remains statistically intractable when given online access to a reset distribution with good coverage properties over the state space (the so-called $\mu$-reset setting). We also study stronger forms of function approximation for policy learning, showing that PSDP [BKSN03] and CPI [KL02] provably fail in the absence of policy completeness. 3. On a positive note, agnostic policy learning is statistically tractable for Block MDPs with access to both of the above reset models. We establish this via a new algorithm that carefully constructs a policy emulator: a tabular MDP with a small state space that approximates the value functions of all policies $\pi \in \Pi$. These values are approximated without any explicit value function class.
Unstable Unlearning: The Hidden Risk of Concept Resurgence in Diffusion Models
Oct 10, 2024
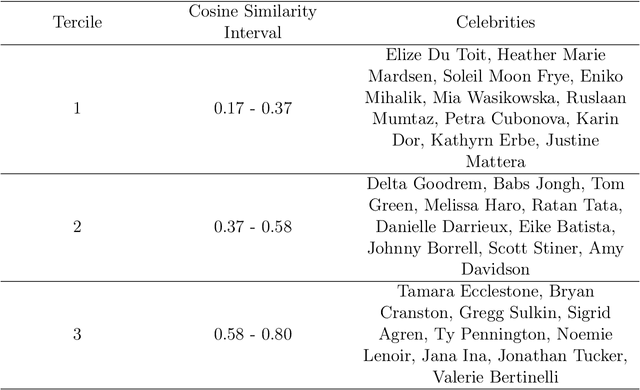
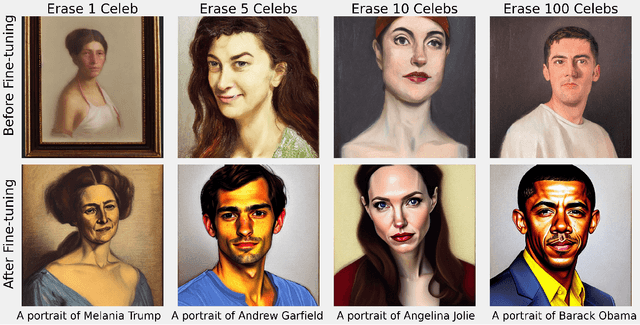
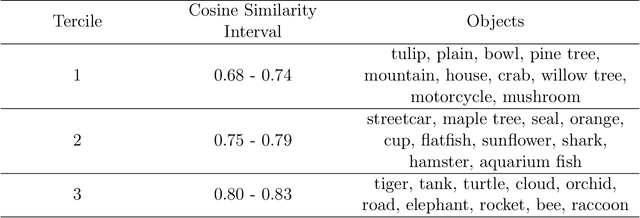
Text-to-image diffusion models rely on massive, web-scale datasets. Training them from scratch is computationally expensive, and as a result, developers often prefer to make incremental updates to existing models. These updates often compose fine-tuning steps (to learn new concepts or improve model performance) with "unlearning" steps (to "forget" existing concepts, such as copyrighted works or explicit content). In this work, we demonstrate a critical and previously unknown vulnerability that arises in this paradigm: even under benign, non-adversarial conditions, fine-tuning a text-to-image diffusion model on seemingly unrelated images can cause it to "relearn" concepts that were previously "unlearned." We comprehensively investigate the causes and scope of this phenomenon, which we term concept resurgence, by performing a series of experiments which compose "mass concept erasure" (the current state of the art for unlearning in text-to-image diffusion models (Lu et al., 2024)) with subsequent fine-tuning of Stable Diffusion v1.4. Our findings underscore the fragility of composing incremental model updates, and raise serious new concerns about current approaches to ensuring the safety and alignment of text-to-image diffusion models.
Random Latent Exploration for Deep Reinforcement Learning
Jul 18, 2024



The ability to efficiently explore high-dimensional state spaces is essential for the practical success of deep Reinforcement Learning (RL). This paper introduces a new exploration technique called Random Latent Exploration (RLE), that combines the strengths of bonus-based and noise-based (two popular approaches for effective exploration in deep RL) exploration strategies. RLE leverages the idea of perturbing rewards by adding structured random rewards to the original task rewards in certain (random) states of the environment, to encourage the agent to explore the environment during training. RLE is straightforward to implement and performs well in practice. To demonstrate the practical effectiveness of RLE, we evaluate it on the challenging Atari and IsaacGym benchmarks and show that RLE exhibits higher overall scores across all the tasks than other approaches.
Langevin Dynamics: A Unified Perspective on Optimization via Lyapunov Potentials
Jul 05, 2024We study the problem of non-convex optimization using Stochastic Gradient Langevin Dynamics (SGLD). SGLD is a natural and popular variation of stochastic gradient descent where at each step, appropriately scaled Gaussian noise is added. To our knowledge, the only strategy for showing global convergence of SGLD on the loss function is to show that SGLD can sample from a stationary distribution which assigns larger mass when the function is small (the Gibbs measure), and then to convert these guarantees to optimization results. We employ a new strategy to analyze the convergence of SGLD to global minima, based on Lyapunov potentials and optimization. We convert the same mild conditions from previous works on SGLD into geometric properties based on Lyapunov potentials. This adapts well to the case with a stochastic gradient oracle, which is natural for machine learning applications where one wants to minimize population loss but only has access to stochastic gradients via minibatch training samples. Here we provide 1) improved rates in the setting of previous works studying SGLD for optimization, 2) the first finite gradient complexity guarantee for SGLD where the function is Lipschitz and the Gibbs measure defined by the function satisfies a Poincar\'e Inequality, and 3) prove if continuous-time Langevin Dynamics succeeds for optimization, then discrete-time SGLD succeeds under mild regularity assumptions.
Machine Unlearning Fails to Remove Data Poisoning Attacks
Jun 25, 2024We revisit the efficacy of several practical methods for approximate machine unlearning developed for large-scale deep learning. In addition to complying with data deletion requests, one often-cited potential application for unlearning methods is to remove the effects of training on poisoned data. We experimentally demonstrate that, while existing unlearning methods have been demonstrated to be effective in a number of evaluation settings (e.g., alleviating membership inference attacks), they fail to remove the effects of data poisoning, across a variety of types of poisoning attacks (indiscriminate, targeted, and a newly-introduced Gaussian poisoning attack) and models (image classifiers and LLMs); even when granted a relatively large compute budget. In order to precisely characterize unlearning efficacy, we introduce new evaluation metrics for unlearning based on data poisoning. Our results suggest that a broader perspective, including a wider variety of evaluations, is required to avoid a false sense of confidence in machine unlearning procedures for deep learning without provable guarantees. Moreover, while unlearning methods show some signs of being useful to efficiently remove poisoned datapoints without having to retrain, our work suggests that these methods are not yet "ready for prime time", and currently provide limited benefit over retraining.
Computationally Efficient RL under Linear Bellman Completeness for Deterministic Dynamics
Jun 17, 2024
We study computationally and statistically efficient Reinforcement Learning algorithms for the linear Bellman Complete setting, a setting that uses linear function approximation to capture value functions and unifies existing models like linear Markov Decision Processes (MDP) and Linear Quadratic Regulators (LQR). While it is known from the prior works that this setting is statistically tractable, it remained open whether a computationally efficient algorithm exists. Our work provides a computationally efficient algorithm for the linear Bellman complete setting that works for MDPs with large action spaces, random initial states, and random rewards but relies on the underlying dynamics to be deterministic. Our approach is based on randomization: we inject random noise into least square regression problems to perform optimistic value iteration. Our key technical contribution is to carefully design the noise to only act in the null space of the training data to ensure optimism while circumventing a subtle error amplification issue.