 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason with Curriculum I: Provable Benefits of Autocurriculum
Mar 18, 2026Chain-of-thought reasoning, where language models expend additional computation by producing thinking tokens prior to final responses, has driven significant advances in model capabilities. However, training these reasoning models is extremely costly in terms of both data and compute, as it involves collecting long traces of reasoning behavior from humans or synthetic generators and further post-training the model via reinforcement learning. Are these costs fundamental, or can they be reduced through better algorithmic design? We show that autocurriculum, where the model uses its own performance to decide which problems to focus training on, provably improves upon standard training recipes for both supervised fine-tuning (SFT) and reinforcement learning (RL). For SFT, we show that autocurriculum requires exponentially fewer reasoning demonstrations than non-adaptive fine-tuning, by focusing teacher supervision on prompts where the current model struggles. For RL fine-tuning, autocurriculum decouples the computational cost from the quality of the reference model, reducing the latter to a burn-in cost that is nearly independent of the target accuracy. These improvements arise purely from adaptive data selection, drawing on classical techniques from boosting and learning from counterexamples, and requiring no assumption on the distribution or difficulty of prompts.
Reject, Resample, Repeat: Understanding Parallel Reasoning in Language Model Inference
Mar 09, 2026Inference-time methods that aggregate and prune multiple samples have emerged as a powerful paradigm for steering large language models, yet we lack any principled understanding of their accuracy-cost tradeoffs. In this paper, we introduce a route to rigorously study such approaches using the lens of *particle filtering* algorithms such as Sequential Monte Carlo (SMC). Given a base language model and a *process reward model* estimating expected terminal rewards, we ask: *how accurately can we sample from a target distribution given some number of process reward evaluations?* Theoretically, we identify (1) simple criteria enabling non-asymptotic guarantees for SMC; (2) algorithmic improvements to SMC; and (3) a fundamental limit faced by all particle filtering methods. Empirically, we demonstrate that our theoretical criteria effectively govern the *sampling error* of SMC, though not necessarily its final *accuracy*, suggesting that theoretical perspectives beyond sampling may be necessary.
A Unifying View of Coverage in Linear Off-Policy Evaluation
Jan 26, 2026Off-policy evaluation (OPE) is a fundamental task in reinforcement learning (RL). In the classic setting of linear OPE, finite-sample guarantees often take the form $$ \textrm{Evaluation error} \le \textrm{poly}(C^π, d, 1/n,\log(1/δ)), $$ where $d$ is the dimension of the features and $C^π$ is a coverage parameter that characterizes the degree to which the visited features lie in the span of the data distribution. While such guarantees are well-understood for several popular algorithms under stronger assumptions (e.g. Bellman completeness), the understanding is lacking and fragmented in the minimal setting where only the target value function is linearly realizable in the features. Despite recent interest in tight characterizations of the statistical rate in this setting, the right notion of coverage remains unclear, and candidate definitions from prior analyses have undesirable properties and are starkly disconnected from more standard definitions in the literature. We provide a novel finite-sample analysis of a canonical algorithm for this setting, LSTDQ. Inspired by an instrumental-variable view, we develop error bounds that depend on a novel coverage parameter, the feature-dynamics coverage, which can be interpreted as linear coverage in an induced dynamical system for feature evolution. With further assumptions -- such as Bellman-completeness -- our definition successfully recovers the coverage parameters specialized to those settings, finally yielding a unified understanding for coverage in linear OPE.
Wait, Wait, Wait... Why Do Reasoning Models Loop?
Dec 15, 2025Reasoning models (e.g., DeepSeek-R1) generate long chains of thought to solve harder problems, but they often loop, repeating the same text at low temperatures or with greedy decoding. We study why this happens and what role temperature plays. With open reasoning models, we find that looping is common at low temperature. Larger models tend to loop less, and distilled students loop significantly even when their teachers rarely do. This points to mismatches between the training distribution and the learned model, which we refer to as errors in learning, as a key cause. To understand how such errors cause loops, we introduce a synthetic graph reasoning task and demonstrate two mechanisms. First, risk aversion caused by hardness of learning: when the correct progress-making action is hard to learn but an easy cyclic action is available, the model puts relatively more probability on the cyclic action and gets stuck. Second, even when there is no hardness, Transformers show an inductive bias toward temporally correlated errors, so the same few actions keep being chosen and loops appear. Higher temperature reduces looping by promoting exploration, but it does not fix the errors in learning, so generations remain much longer than necessary at high temperature; in this sense, temperature is a stopgap rather than a holistic solution. We end with a discussion of training-time interventions aimed at directly reducing errors in learning.
The Role of Environment Access in Agnostic Reinforcement Learning
Apr 07, 2025

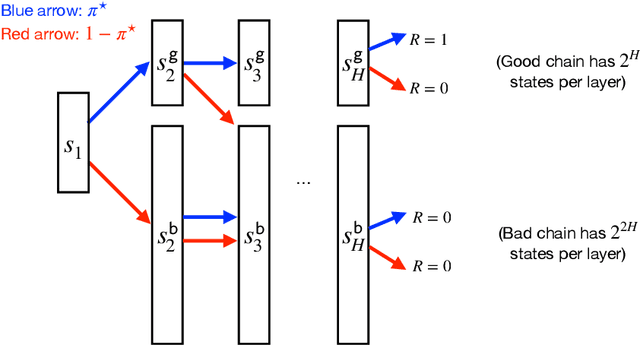

We study Reinforcement Learning (RL) in environments with large state spaces, where function approximation is required for sample-efficient learning. Departing from a long history of prior work, we consider the weakest possible form of function approximation, called agnostic policy learning, where the learner seeks to find the best policy in a given class $\Pi$, with no guarantee that $\Pi$ contains an optimal policy for the underlying task. Although it is known that sample-efficient agnostic policy learning is not possible in the standard online RL setting without further assumptions, we investigate the extent to which this can be overcome with stronger forms of access to the environment. Specifically, we show that: 1. Agnostic policy learning remains statistically intractable when given access to a local simulator, from which one can reset to any previously seen state. This result holds even when the policy class is realizable, and stands in contrast to a positive result of [MFR24] showing that value-based learning under realizability is tractable with local simulator access. 2. Agnostic policy learning remains statistically intractable when given online access to a reset distribution with good coverage properties over the state space (the so-called $\mu$-reset setting). We also study stronger forms of function approximation for policy learning, showing that PSDP [BKSN03] and CPI [KL02] provably fail in the absence of policy completeness. 3. On a positive note, agnostic policy learning is statistically tractable for Block MDPs with access to both of the above reset models. We establish this via a new algorithm that carefully constructs a policy emulator: a tabular MDP with a small state space that approximates the value functions of all policies $\pi \in \Pi$. These values are approximated without any explicit value function class.
Is Best-of-N the Best of Them? Coverage, Scaling, and Optimality in Inference-Time Alignment
Mar 27, 2025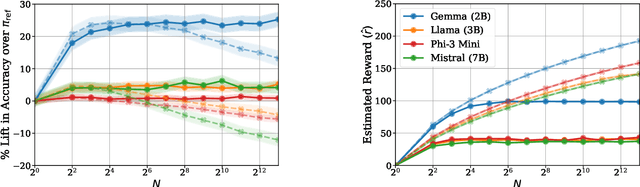
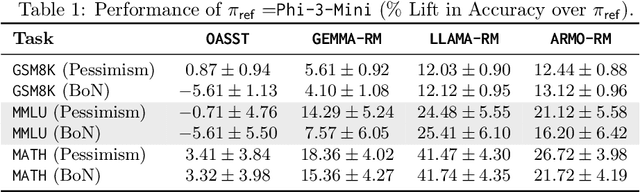
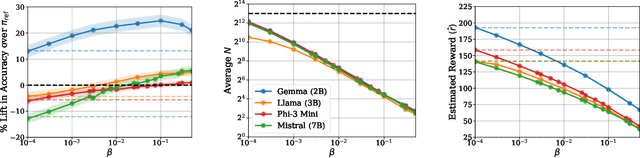
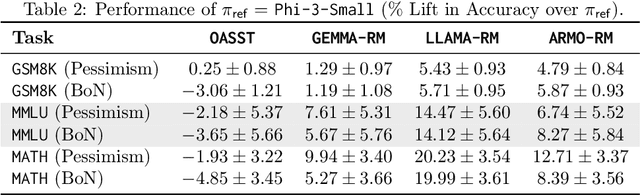
Inference-time computation provides an important axis for scaling language model performance, but naively scaling compute through techniques like Best-of-$N$ sampling can cause performance to degrade due to reward hacking. Toward a theoretical understanding of how to best leverage additional computation, we focus on inference-time alignment which we formalize as the problem of improving a pre-trained policy's responses for a prompt of interest, given access to an imperfect reward model. We analyze the performance of inference-time alignment algorithms in terms of (i) response quality, and (ii) compute, and provide new results that highlight the importance of the pre-trained policy's coverage over high-quality responses for performance and compute scaling: 1. We show that Best-of-$N$ alignment with an ideal choice for $N$ can achieve optimal performance under stringent notions of coverage, but provably suffers from reward hacking when $N$ is large, and fails to achieve tight guarantees under more realistic coverage conditions. 2. We introduce $\texttt{InferenceTimePessimism}$, a new algorithm which mitigates reward hacking through deliberate use of inference-time compute, implementing the principle of pessimism in the face of uncertainty via rejection sampling; we prove that its performance is optimal and does not degrade with $N$, meaning it is scaling-monotonic. We complement our theoretical results with an experimental evaluation that demonstrate the benefits of $\texttt{InferenceTimePessimism}$ across a variety of tasks and models.
Computational-Statistical Tradeoffs at the Next-Token Prediction Barrier: Autoregressive and Imitation Learning under Misspecification
Feb 18, 2025Next-token prediction with the logarithmic loss is a cornerstone of autoregressive sequence modeling, but, in practice, suffers from error amplification, where errors in the model compound and generation quality degrades as sequence length $H$ increases. From a theoretical perspective, this phenomenon should not appear in well-specified settings, and, indeed, a growing body of empirical work hypothesizes that misspecification, where the learner is not sufficiently expressive to represent the target distribution, may be the root cause. Under misspecification -- where the goal is to learn as well as the best-in-class model up to a multiplicative approximation factor $C\geq 1$ -- we confirm that $C$ indeed grows with $H$ for next-token prediction, lending theoretical support to this empirical hypothesis. We then ask whether this mode of error amplification is avoidable algorithmically, computationally, or information-theoretically, and uncover inherent computational-statistical tradeoffs. We show: (1) Information-theoretically, one can avoid error amplification and achieve $C=O(1)$. (2) Next-token prediction can be made robust so as to achieve $C=\tilde O(H)$, representing moderate error amplification, but this is an inherent barrier: any next-token prediction-style objective must suffer $C=\Omega(H)$. (3) For the natural testbed of autoregressive linear models, no computationally efficient algorithm can achieve sub-polynomial approximation factor $C=e^{(\log H)^{1-\Omega(1)}}$; however, at least for binary token spaces, one can smoothly trade compute for statistical power and improve on $C=\Omega(H)$ in sub-exponential time. Our results have consequences in the more general setting of imitation learning, where the widely-used behavior cloning algorithm generalizes next-token prediction.
Self-Improvement in Language Models: The Sharpening Mechanism
Dec 02, 2024



Recent work in language modeling has raised the possibility of self-improvement, where a language models evaluates and refines its own generations to achieve higher performance without external feedback. It is impossible for this self-improvement to create information that is not already in the model, so why should we expect that this will lead to improved capabilities? We offer a new perspective on the capabilities of self-improvement through a lens we refer to as sharpening. Motivated by the observation that language models are often better at verifying response quality than they are at generating correct responses, we formalize self-improvement as using the model itself as a verifier during post-training in order to ``sharpen'' the model to one placing large mass on high-quality sequences, thereby amortizing the expensive inference-time computation of generating good sequences. We begin by introducing a new statistical framework for sharpening in which the learner aims to sharpen a pre-trained base policy via sample access, and establish fundamental limits. Then we analyze two natural families of self-improvement algorithms based on SFT and RLHF.
Reinforcement Learning under Latent Dynamics: Toward Statistical and Algorithmic Modularity
Oct 23, 2024
Real-world applications of reinforcement learning often involve environments where agents operate on complex, high-dimensional observations, but the underlying (''latent'') dynamics are comparatively simple. However, outside of restrictive settings such as small latent spaces, the fundamental statistical requirements and algorithmic principles for reinforcement learning under latent dynamics are poorly understood. This paper addresses the question of reinforcement learning under $\textit{general}$ latent dynamics from a statistical and algorithmic perspective. On the statistical side, our main negative result shows that most well-studied settings for reinforcement learning with function approximation become intractable when composed with rich observations; we complement this with a positive result, identifying latent pushforward coverability as a general condition that enables statistical tractability. Algorithmically, we develop provably efficient observable-to-latent reductions -- that is, reductions that transform an arbitrary algorithm for the latent MDP into an algorithm that can operate on rich observations -- in two settings: one where the agent has access to hindsight observations of the latent dynamics [LADZ23], and one where the agent can estimate self-predictive latent models [SAGHCB20]. Together, our results serve as a first step toward a unified statistical and algorithmic theory for reinforcement learning under latent dynamics.
Correcting the Mythos of KL-Regularization: Direct Alignment without Overparameterization via Chi-squared Preference Optimization
Jul 18, 2024


Language model alignment methods, such as reinforcement learning from human feedback (RLHF), have led to impressive advances in language model capabilities, but existing techniques are limited by a widely observed phenomenon known as overoptimization, where the quality of the language model plateaus or degrades over the course of the alignment process. Overoptimization is often attributed to overfitting to an inaccurate reward model, and while it can be mitigated through online data collection, this is infeasible in many settings. This raises a fundamental question: Do existing offline alignment algorithms make the most of the data they have, or can their sample-efficiency be improved further? We address this question with a new algorithm for offline alignment, $\chi^2$-Preference Optimization ($\chi$PO). $\chi$PO is a one-line change to Direct Preference Optimization (DPO; Rafailov et al., 2023), which only involves modifying the logarithmic link function in the DPO objective. Despite this minimal change, $\chi$PO implicitly implements the principle of pessimism in the face of uncertainty via regularization with the $\chi^2$-divergence -- which quantifies uncertainty more effectively than KL-regularization -- and provably alleviates overoptimization, achieving sample-complexity guarantees based on single-policy concentrability -- the gold standard in offline reinforcement learning. $\chi$PO's simplicity and strong guarantees make it the first practical and general-purpose offline alignment algorithm that is provably robust to overoptimization.