 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Behavior Cloning with Action Quantization
Mar 20, 2026Behavior cloning is a fundamental paradigm in machine learning, enabling policy learning from expert demonstrations across robotics, autonomous driving, and generative models. Autoregressive models like transformer have proven remarkably effective, from large language models (LLMs) to vision-language-action systems (VLAs). However, applying autoregressive models to continuous control requires discretizing actions through quantization, a practice widely adopted yet poorly understood theoretically. This paper provides theoretical foundations for this practice. We analyze how quantization error propagates along the horizon and interacts with statistical sample complexity. We show that behavior cloning with quantized actions and log-loss achieves optimal sample complexity, matching existing lower bounds, and incurs only polynomial horizon dependence on quantization error, provided the dynamics are stable and the policy satisfies a probabilistic smoothness condition. We further characterize when different quantization schemes satisfy or violate these requirements, and propose a model-based augmentation that provably improves the error bound without requiring policy smoothness. Finally, we establish fundamental limits that jointly capture the effects of quantization error and statistical complexity.
Breaking the Capability Ceiling of LLM Post-Training by Reintroducing Markov States
Mar 20, 2026Reinforcement learning (RL) has become a standard paradigm for post-training and aligning Large Language Models (LLMs), yet recent evidence suggests it faces a persistent "capability ceiling": unlike classical RL systems that discover novel strategies, RL for LLMs often acts as a mere refiner of patterns already latent in pre-trained weights. In this work, we identify a fundamental structural bottleneck: while classical RL relies on compact, informative Markov states, current LLM post-training formulations are tethered to an ever-expanding history of actions. We revisit a classical principle long central to RL yet absent from LLM post-training: explicit Markov states. Theoretically, we provide rigorous guarantees demonstrating that leveraging estimated Markov states can significantly reduce sample complexity. Empirically, we show that introducing Markov states consistently breaks the performance boundaries of standard RL post-training across a suite of complex logic puzzles. Our findings suggest that moving beyond "history-as-state" modeling in favor of structured Markovian representations is essential for unlocking open-ended discovery and genuinely new reasoning capabilities in Generative AI.
POLCA: Stochastic Generative Optimization with LLM
Mar 16, 2026Optimizing complex systems, ranging from LLM prompts to multi-turn agents, traditionally requires labor-intensive manual iteration. We formalize this challenge as a stochastic generative optimization problem where a generative language model acts as the optimizer, guided by numerical rewards and text feedback to discover the best system. We introduce Prioritized Optimization with Local Contextual Aggregation (POLCA), a scalable framework designed to handle stochasticity in optimization -- such as noisy feedback, sampling minibatches, and stochastic system behaviors -- while effectively managing the unconstrained expansion of solution space. POLCA maintains a priority queue to manage the exploration-exploitation tradeoff, systematically tracking candidate solutions and their evaluation histories. To enhance efficiency, we integrate an $\varepsilon$-Net mechanism to maintain parameter diversity and an LLM Summarizer to perform meta-learning across historical trials. We theoretically prove that POLCA converges to near-optimal candidate solutions under stochasticity. We evaluate our framework on diverse benchmarks, including $τ$-bench, HotpotQA (agent optimization), VeriBench (code translation) and KernelBench (CUDA kernel generation). Experimental results demonstrate that POLCA achieves robust, sample and time-efficient performance, consistently outperforming state-of-the-art algorithms in both deterministic and stochastic problems. The codebase for this work is publicly available at https://github.com/rlx-lab/POLCA.
Reinforce LLM Reasoning through Multi-Agent Reflection
Jun 10, 2025



Leveraging more test-time computation has proven to be an effective way to boost the reasoning capabilities of large language models (LLMs). Among various methods, the verify-and-improve paradigm stands out for enabling dynamic solution exploration and feedback incorporation. However, existing approaches often suffer from restricted feedback spaces and lack of coordinated training of different parties, leading to suboptimal performance. To address this, we model this multi-turn refinement process as a Markov Decision Process and introduce DPSDP (Direct Policy Search by Dynamic Programming), a reinforcement learning algorithm that trains an actor-critic LLM system to iteratively refine answers via direct preference learning on self-generated data. Theoretically, DPSDP can match the performance of any policy within the training distribution. Empirically, we instantiate DPSDP with various base models and show improvements on both in- and out-of-distribution benchmarks. For example, on benchmark MATH 500, majority voting over five refinement steps increases first-turn accuracy from 58.2% to 63.2% with Ministral-based models. An ablation study further confirms the benefits of multi-agent collaboration and out-of-distribution generalization.
Outcome-Based Online Reinforcement Learning: Algorithms and Fundamental Limits
May 26, 2025Reinforcement learning with outcome-based feedback faces a fundamental challenge: when rewards are only observed at trajectory endpoints, how do we assign credit to the right actions? This paper provides the first comprehensive analysis of this problem in online RL with general function approximation. We develop a provably sample-efficient algorithm achieving $\widetilde{O}({C_{\rm cov} H^3}/{\epsilon^2})$ sample complexity, where $C_{\rm cov}$ is the coverability coefficient of the underlying MDP. By leveraging general function approximation, our approach works effectively in large or infinite state spaces where tabular methods fail, requiring only that value functions and reward functions can be represented by appropriate function classes. Our results also characterize when outcome-based feedback is statistically separated from per-step rewards, revealing an unavoidable exponential separation for certain MDPs. For deterministic MDPs, we show how to eliminate the completeness assumption, dramatically simplifying the algorithm. We further extend our approach to preference-based feedback settings, proving that equivalent statistical efficiency can be achieved even under more limited information. Together, these results constitute a theoretical foundation for understanding the statistical properties of outcome-based reinforcement learning.
Trajectory Bellman Residual Minimization: A Simple Value-Based Method for LLM Reasoning
May 21, 2025



Policy-based methods currently dominate reinforcement learning (RL) pipelines for large language model (LLM) reasoning, leaving value-based approaches largely unexplored. We revisit the classical paradigm of Bellman Residual Minimization and introduce Trajectory Bellman Residual Minimization (TBRM), an algorithm that naturally adapts this idea to LLMs, yielding a simple yet effective off-policy algorithm that optimizes a single trajectory-level Bellman objective using the model's own logits as $Q$-values. TBRM removes the need for critics, importance-sampling ratios, or clipping, and operates with only one rollout per prompt. We prove convergence to the near-optimal KL-regularized policy from arbitrary off-policy data via an improved change-of-trajectory-measure analysis. Experiments on standard mathematical-reasoning benchmarks show that TBRM consistently outperforms policy-based baselines, like PPO and GRPO, with comparable or lower computational and memory overhead. Our results indicate that value-based RL might be a principled and efficient alternative for enhancing reasoning capabilities in LLMs.
Correcting the Mythos of KL-Regularization: Direct Alignment without Overparameterization via Chi-squared Preference Optimization
Jul 18, 2024


Language model alignment methods, such as reinforcement learning from human feedback (RLHF), have led to impressive advances in language model capabilities, but existing techniques are limited by a widely observed phenomenon known as overoptimization, where the quality of the language model plateaus or degrades over the course of the alignment process. Overoptimization is often attributed to overfitting to an inaccurate reward model, and while it can be mitigated through online data collection, this is infeasible in many settings. This raises a fundamental question: Do existing offline alignment algorithms make the most of the data they have, or can their sample-efficiency be improved further? We address this question with a new algorithm for offline alignment, $\chi^2$-Preference Optimization ($\chi$PO). $\chi$PO is a one-line change to Direct Preference Optimization (DPO; Rafailov et al., 2023), which only involves modifying the logarithmic link function in the DPO objective. Despite this minimal change, $\chi$PO implicitly implements the principle of pessimism in the face of uncertainty via regularization with the $\chi^2$-divergence -- which quantifies uncertainty more effectively than KL-regularization -- and provably alleviates overoptimization, achieving sample-complexity guarantees based on single-policy concentrability -- the gold standard in offline reinforcement learning. $\chi$PO's simplicity and strong guarantees make it the first practical and general-purpose offline alignment algorithm that is provably robust to overoptimization.
Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts
Jun 18, 2024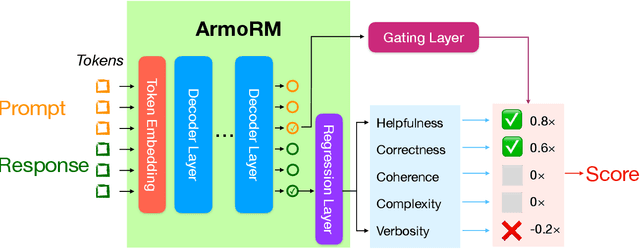
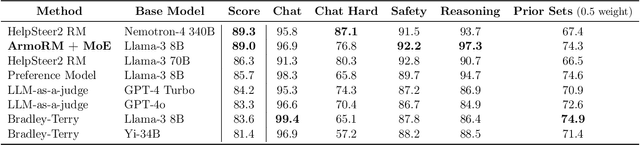
Reinforcement learning from human feedback (RLHF) has emerged as the primary method for aligning large language models (LLMs) with human preferences. The RLHF process typically starts by training a reward model (RM) using human preference data. Conventional RMs are trained on pairwise responses to the same user request, with relative ratings indicating which response humans prefer. The trained RM serves as a proxy for human preferences. However, due to the black-box nature of RMs, their outputs lack interpretability, as humans cannot intuitively understand why an RM thinks a response is good or not. As RMs act as human preference proxies, we believe they should be human-interpretable to ensure that their internal decision processes are consistent with human preferences and to prevent reward hacking in LLM alignment. To build RMs with interpretable preferences, we propose a two-stage approach: i) train an Absolute-Rating Multi-Objective Reward Model (ArmoRM) with multi-dimensional absolute-rating data, each dimension corresponding to a human-interpretable objective (e.g., honesty, verbosity, safety); ii) employ a Mixture-of-Experts (MoE) strategy with a gating network that automatically selects the most suitable reward objectives based on the context. We efficiently trained an ArmoRM with Llama-3 8B and a gating network consisting of a shallow MLP on top of the ArmoRM. Our trained model, ArmoRM-Llama3-8B, obtains state-of-the-art performance on RewardBench, a benchmark evaluating RMs for language modeling. Notably, the performance of our model surpasses the LLM-as-a-judge method with GPT-4 judges by a margin, and approaches the performance of the much larger Nemotron-4 340B reward model.
Self-Play with Adversarial Critic: Provable and Scalable Offline Alignment for Language Models
Jun 06, 2024
This work studies the challenge of aligning large language models (LLMs) with offline preference data. We focus on alignment by Reinforcement Learning from Human Feedback (RLHF) in particular. While popular preference optimization methods exhibit good empirical performance in practice, they are not theoretically guaranteed to converge to the optimal policy and can provably fail when the data coverage is sparse by classical offline reinforcement learning (RL) results. On the other hand, a recent line of work has focused on theoretically motivated preference optimization methods with provable guarantees, but these are not computationally efficient for large-scale applications like LLM alignment. To bridge this gap, we propose SPAC, a new offline preference optimization method with self-play, inspired by the on-average pessimism technique from the offline RL literature, to be the first provable and scalable approach to LLM alignment. We both provide theoretical analysis for its convergence under single-policy concentrability for the general function approximation setting and demonstrate its competitive empirical performance for LLM alignment on a 7B Mistral model with Open LLM Leaderboard evaluations.
Exploratory Preference Optimization: Harnessing Implicit Q*-Approximation for Sample-Efficient RLHF
May 31, 2024

Reinforcement learning from human feedback (RLHF) has emerged as a central tool for language model alignment. We consider online exploration in RLHF, which exploits interactive access to human or AI feedback by deliberately encouraging the model to produce diverse, maximally informative responses. By allowing RLHF to confidently stray from the pre-trained model, online exploration offers the possibility of novel, potentially super-human capabilities, but its full potential as a paradigm for language model training has yet to be realized, owing to computational and statistical bottlenecks in directly adapting existing reinforcement learning techniques. We propose a new algorithm for online exploration in RLHF, Exploratory Preference Optimization (XPO), which is simple and practical -- a one-line change to (online) Direct Preference Optimization (DPO; Rafailov et al., 2023) -- yet enjoys the strongest known provable guarantees and promising empirical performance. XPO augments the DPO objective with a novel and principled exploration bonus, empowering the algorithm to explore outside the support of the initial model and human feedback data. In theory, we show that XPO is provably sample-efficient and converges to a near-optimal language model policy under natural exploration conditions, irrespective of whether the initial model has good coverage. Our analysis, which builds on the observation that DPO implicitly performs a form of $Q^{\star}$-approximation (or, Bellman error minimization), combines previously disparate techniques from language modeling and theoretical reinforcement learning in a serendipitous fashion through the perspective of KL-regularized Markov decision processes. Empirically, we find that XPO is more sample-efficient than non-exploratory DPO variants in a preliminary evaluation.