 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based Text Simplification and its Effect on User Comprehension and Cognitive Load
May 04, 2025Information on the web, such as scientific publications and Wikipedia, often surpasses users' reading level. To help address this, we used a self-refinement approach to develop a LLM capability for minimally lossy text simplification. To validate our approach, we conducted a randomized study involving 4563 participants and 31 texts spanning 6 broad subject areas: PubMed (biomedical scientific articles), biology, law, finance, literature/philosophy, and aerospace/computer science. Participants were randomized to viewing original or simplified texts in a subject area, and answered multiple-choice questions (MCQs) that tested their comprehension of the text. The participants were also asked to provide qualitative feedback such as task difficulty. Our results indicate that participants who read the simplified text answered more MCQs correctly than their counterparts who read the original text (3.9% absolute increase, p<0.05). This gain was most striking with PubMed (14.6%), while more moderate gains were observed for finance (5.5%), aerospace/computer science (3.8%) domains, and legal (3.5%). Notably, the results were robust to whether participants could refer back to the text while answering MCQs. The absolute accuracy decreased by up to ~9% for both original and simplified setups where participants could not refer back to the text, but the ~4% overall improvement persisted. Finally, participants' self-reported perceived ease based on a simplified NASA Task Load Index was greater for those who read the simplified text (absolute change on a 5-point scale 0.33, p<0.05). This randomized study, involving an order of magnitude more participants than prior works, demonstrates the potential of LLMs to make complex information easier to understand. Our work aims to enable a broader audience to better learn and make use of expert knowledge available on the web, improving information accessibility.
All-in-One Transferring Image Compression from Human Perception to Multi-Machine Perception
Apr 17, 2025Efficiently transferring Learned Image Compression (LIC) model from human perception to machine perception is an emerging challenge in vision-centric representation learning. Existing approaches typically adapt LIC to downstream tasks in a single-task manner, which is inefficient, lacks task interaction, and results in multiple task-specific bitstreams. To address these limitations, we propose an asymmetric adaptor framework that supports multi-task adaptation within a single model. Our method introduces a shared adaptor to learn general semantic features and task-specific adaptors to preserve task-level distinctions. With only lightweight plug-in modules and a frozen base codec, our method achieves strong performance across multiple tasks while maintaining compression efficiency. Experiments on the PASCAL-Context benchmark demonstrate that our method outperforms both Fully Fine-Tuned and other Parameter Efficient Fine-Tuned (PEFT) baselines, and validating the effectiveness of multi-vision transferring.
Tree-NeRV: A Tree-Structured Neural Representation for Efficient Non-Uniform Video Encoding
Apr 17, 2025Implicit Neural Representations for Videos (NeRV) have emerged as a powerful paradigm for video representation, enabling direct mappings from frame indices to video frames. However, existing NeRV-based methods do not fully exploit temporal redundancy, as they rely on uniform sampling along the temporal axis, leading to suboptimal rate-distortion (RD) performance. To address this limitation, we propose Tree-NeRV, a novel tree-structured feature representation for efficient and adaptive video encoding. Unlike conventional approaches, Tree-NeRV organizes feature representations within a Binary Search Tree (BST), enabling non-uniform sampling along the temporal axis. Additionally, we introduce an optimization-driven sampling strategy, dynamically allocating higher sampling density to regions with greater temporal variation. Extensive experiments demonstrate that Tree-NeRV achieves superior compression efficiency and reconstruction quality, outperforming prior uniform sampling-based methods. Code will be released.
SCOPE-DTI: Semi-Inductive Dataset Construction and Framework Optimization for Practical Usability Enhancement in Deep Learning-Based Drug Target Interaction Prediction
Mar 12, 2025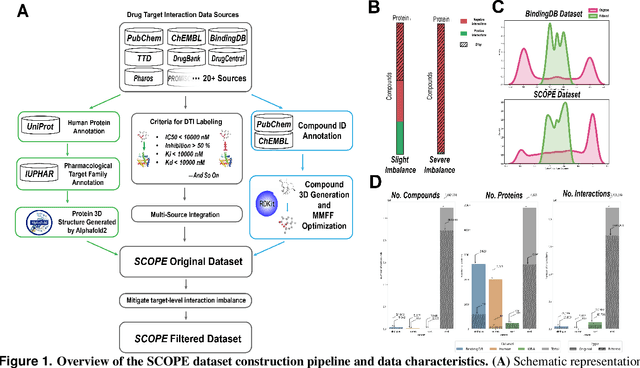
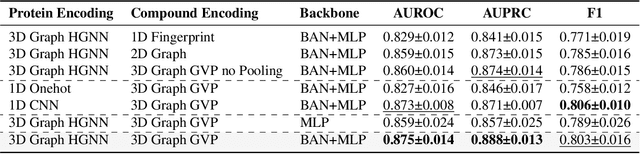
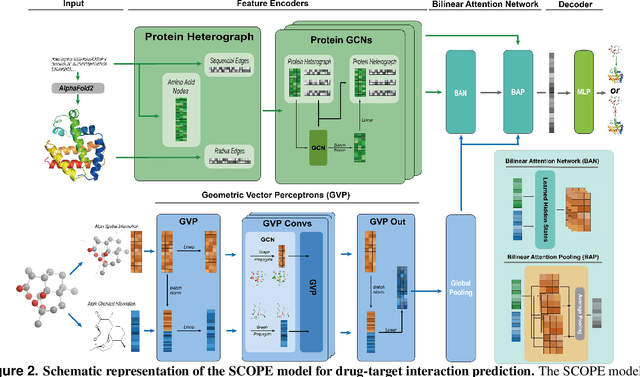
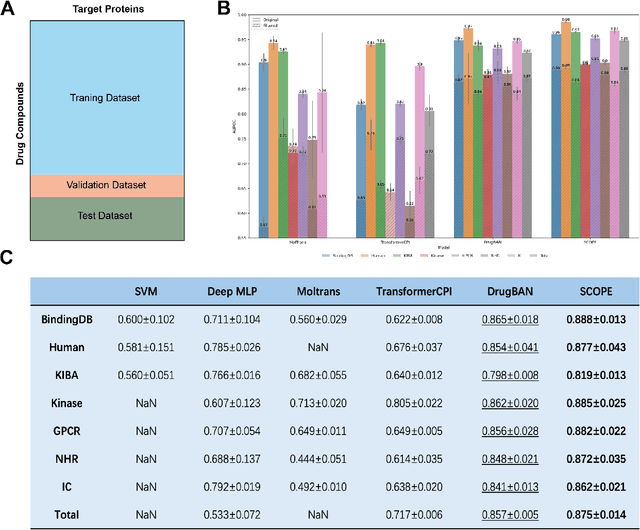
Deep learning-based drug-target interaction (DTI) prediction methods have demonstrated strong performance; however, real-world applicability remains constrained by limited data diversity and modeling complexity. To address these challenges, we propose SCOPE-DTI, a unified framework combining a large-scale, balanced semi-inductive human DTI dataset with advanced deep learning modeling. Constructed from 13 public repositories, the SCOPE dataset expands data volume by up to 100-fold compared to common benchmarks such as the Human dataset. The SCOPE model integrates three-dimensional protein and compound representations, graph neural networks, and bilinear attention mechanisms to effectively capture cross domain interaction patterns, significantly outperforming state-of-the-art methods across various DTI prediction tasks. Additionally, SCOPE-DTI provides a user-friendly interface and database. We further validate its effectiveness by experimentally identifying anticancer targets of Ginsenoside Rh1. By offering comprehensive data, advanced modeling, and accessible tools, SCOPE-DTI accelerates drug discovery research.
MATH-Perturb: Benchmarking LLMs' Math Reasoning Abilities against Hard Perturbations
Feb 10, 2025



Large language models have demonstrated impressive performance on challenging mathematical reasoning tasks, which has triggered the discussion of whether the performance is achieved by true reasoning capability or memorization. To investigate this question, prior work has constructed mathematical benchmarks when questions undergo simple perturbations -- modifications that still preserve the underlying reasoning patterns of the solutions. However, no work has explored hard perturbations, which fundamentally change the nature of the problem so that the original solution steps do not apply. To bridge the gap, we construct MATH-P-Simple and MATH-P-Hard via simple perturbation and hard perturbation, respectively. Each consists of 279 perturbed math problems derived from level-5 (hardest) problems in the MATH dataset (Hendrycksmath et. al., 2021). We observe significant performance drops on MATH-P-Hard across various models, including o1-mini (-16.49%) and gemini-2.0-flash-thinking (-12.9%). We also raise concerns about a novel form of memorization where models blindly apply learned problem-solving skills without assessing their applicability to modified contexts. This issue is amplified when using original problems for in-context learning. We call for research efforts to address this challenge, which is critical for developing more robust and reliable reasoning models.
Improving Vision-Language-Action Model with Online Reinforcement Learning
Jan 28, 2025
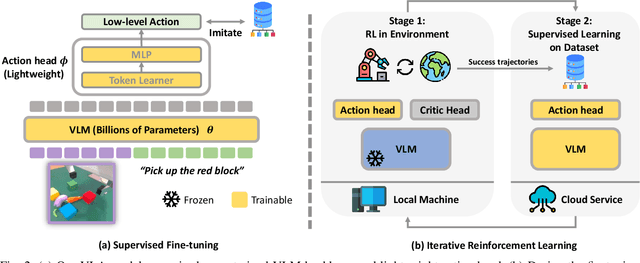

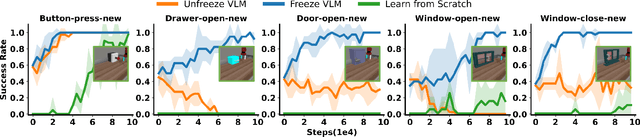
Recent studies have successfully integrated large vision-language models (VLMs) into low-level robotic control by supervised fine-tuning (SFT) with expert robotic datasets, resulting in what we term vision-language-action (VLA) models. Although the VLA models are powerful, how to improve these large models during interaction with environments remains an open question. In this paper, we explore how to further improve these VLA models via Reinforcement Learning (RL), a commonly used fine-tuning technique for large models. However, we find that directly applying online RL to large VLA models presents significant challenges, including training instability that severely impacts the performance of large models, and computing burdens that exceed the capabilities of most local machines. To address these challenges, we propose iRe-VLA framework, which iterates between Reinforcement Learning and Supervised Learning to effectively improve VLA models, leveraging the exploratory benefits of RL while maintaining the stability of supervised learning. Experiments in two simulated benchmarks and a real-world manipulation suite validate the effectiveness of our method.
RS-NeRF: Neural Radiance Fields from Rolling Shutter Images
Jul 14, 2024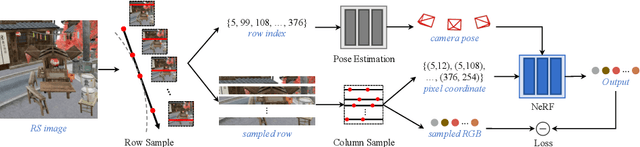

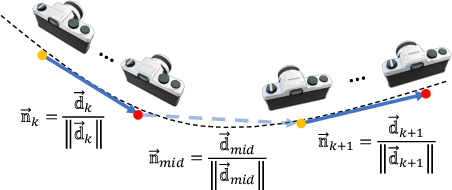
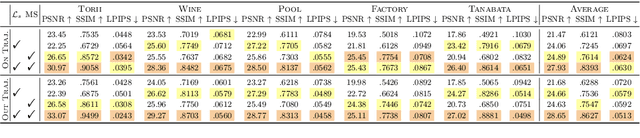
Neural Radiance Fields (NeRFs) have become increasingly popular because of their impressive ability for novel view synthesis. However, their effectiveness is hindered by the Rolling Shutter (RS) effects commonly found in most camera systems. To solve this, we present RS-NeRF, a method designed to synthesize normal images from novel views using input with RS distortions. This involves a physical model that replicates the image formation process under RS conditions and jointly optimizes NeRF parameters and camera extrinsic for each image row. We further address the inherent shortcomings of the basic RS-NeRF model by delving into the RS characteristics and developing algorithms to enhance its functionality. First, we impose a smoothness regularization to better estimate trajectories and improve the synthesis quality, in line with the camera movement prior. We also identify and address a fundamental flaw in the vanilla RS model by introducing a multi-sampling algorithm. This new approach improves the model's performance by comprehensively exploiting the RGB data across different rows for each intermediate camera pose. Through rigorous experimentation, we demonstrate that RS-NeRF surpasses previous methods in both synthetic and real-world scenarios, proving its ability to correct RS-related distortions effectively. Codes and data available: https://github.com/MyNiuuu/RS-NeRF
Self-Play with Adversarial Critic: Provable and Scalable Offline Alignment for Language Models
Jun 06, 2024
This work studies the challenge of aligning large language models (LLMs) with offline preference data. We focus on alignment by Reinforcement Learning from Human Feedback (RLHF) in particular. While popular preference optimization methods exhibit good empirical performance in practice, they are not theoretically guaranteed to converge to the optimal policy and can provably fail when the data coverage is sparse by classical offline reinforcement learning (RL) results. On the other hand, a recent line of work has focused on theoretically motivated preference optimization methods with provable guarantees, but these are not computationally efficient for large-scale applications like LLM alignment. To bridge this gap, we propose SPAC, a new offline preference optimization method with self-play, inspired by the on-average pessimism technique from the offline RL literature, to be the first provable and scalable approach to LLM alignment. We both provide theoretical analysis for its convergence under single-policy concentrability for the general function approximation setting and demonstrate its competitive empirical performance for LLM alignment on a 7B Mistral model with Open LLM Leaderboard evaluations.
Motion Blur Decomposition with Cross-shutter Guidance
Apr 01, 2024



Motion blur is a frequently observed image artifact, especially under insufficient illumination where exposure time has to be prolonged so as to collect more photons for a bright enough image. Rather than simply removing such blurring effects, recent researches have aimed at decomposing a blurry image into multiple sharp images with spatial and temporal coherence. Since motion blur decomposition itself is highly ambiguous, priors from neighbouring frames or human annotation are usually needed for motion disambiguation. In this paper, inspired by the complementary exposure characteristics of a global shutter (GS) camera and a rolling shutter (RS) camera, we propose to utilize the ordered scanline-wise delay in a rolling shutter image to robustify motion decomposition of a single blurry image. To evaluate this novel dual imaging setting, we construct a triaxial system to collect realistic data, as well as a deep network architecture that explicitly addresses temporal and contextual information through reciprocal branches for cross-shutter motion blur decomposition. Experiment results have verified the effectiveness of our proposed algorithm, as well as the validity of our dual imaging setting.
Sample Complexity of Preference-Based Nonparametric Off-Policy Evaluation with Deep Networks
Oct 16, 2023
A recently popular approach to solving reinforcement learning is with data from human preferences. In fact, human preference data are now used with classic reinforcement learning algorithms such as actor-critic methods, which involve evaluating an intermediate policy over a reward learned from human preference data with distribution shift, known as off-policy evaluation (OPE). Such algorithm includes (i) learning reward function from human preference dataset, and (ii) learning expected cumulative reward of a target policy. Despite the huge empirical success, existing OPE methods with preference data often lack theoretical understanding and rely heavily on heuristics. In this paper, we study the sample efficiency of OPE with human preference and establish a statistical guarantee for it. Specifically, we approach OPE by learning the value function by fitted-Q-evaluation with a deep neural network. By appropriately selecting the size of a ReLU network, we show that one can leverage any low-dimensional manifold structure in the Markov decision process and obtain a sample-efficient estimator without suffering from the curse of high data ambient dimensionality. Under the assumption of high reward smoothness, our results \textit{almost align with the classical OPE results with observable reward data}. To the best of our knowledge, this is the first result that establishes a \textit{provably efficient} guarantee for off-policy evaluation with RLHF.