 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAniCrafter: Customizing Realistic Human-Centric Animation via Avatar-Background Conditioning in Video Diffusion Models
May 26, 2025Recent advances in video diffusion models have significantly improved character animation techniques. However, current approaches rely on basic structural conditions such as DWPose or SMPL-X to animate character images, limiting their effectiveness in open-domain scenarios with dynamic backgrounds or challenging human poses. In this paper, we introduce $\textbf{AniCrafter}$, a diffusion-based human-centric animation model that can seamlessly integrate and animate a given character into open-domain dynamic backgrounds while following given human motion sequences. Built on cutting-edge Image-to-Video (I2V) diffusion architectures, our model incorporates an innovative "avatar-background" conditioning mechanism that reframes open-domain human-centric animation as a restoration task, enabling more stable and versatile animation outputs. Experimental results demonstrate the superior performance of our method. Codes will be available at https://github.com/MyNiuuu/AniCrafter.
All-in-One Transferring Image Compression from Human Perception to Multi-Machine Perception
Apr 17, 2025Efficiently transferring Learned Image Compression (LIC) model from human perception to machine perception is an emerging challenge in vision-centric representation learning. Existing approaches typically adapt LIC to downstream tasks in a single-task manner, which is inefficient, lacks task interaction, and results in multiple task-specific bitstreams. To address these limitations, we propose an asymmetric adaptor framework that supports multi-task adaptation within a single model. Our method introduces a shared adaptor to learn general semantic features and task-specific adaptors to preserve task-level distinctions. With only lightweight plug-in modules and a frozen base codec, our method achieves strong performance across multiple tasks while maintaining compression efficiency. Experiments on the PASCAL-Context benchmark demonstrate that our method outperforms both Fully Fine-Tuned and other Parameter Efficient Fine-Tuned (PEFT) baselines, and validating the effectiveness of multi-vision transferring.
Tree-NeRV: A Tree-Structured Neural Representation for Efficient Non-Uniform Video Encoding
Apr 17, 2025Implicit Neural Representations for Videos (NeRV) have emerged as a powerful paradigm for video representation, enabling direct mappings from frame indices to video frames. However, existing NeRV-based methods do not fully exploit temporal redundancy, as they rely on uniform sampling along the temporal axis, leading to suboptimal rate-distortion (RD) performance. To address this limitation, we propose Tree-NeRV, a novel tree-structured feature representation for efficient and adaptive video encoding. Unlike conventional approaches, Tree-NeRV organizes feature representations within a Binary Search Tree (BST), enabling non-uniform sampling along the temporal axis. Additionally, we introduce an optimization-driven sampling strategy, dynamically allocating higher sampling density to regions with greater temporal variation. Extensive experiments demonstrate that Tree-NeRV achieves superior compression efficiency and reconstruction quality, outperforming prior uniform sampling-based methods. Code will be released.
R3-Avatar: Record and Retrieve Temporal Codebook for Reconstructing Photorealistic Human Avatars
Mar 17, 2025
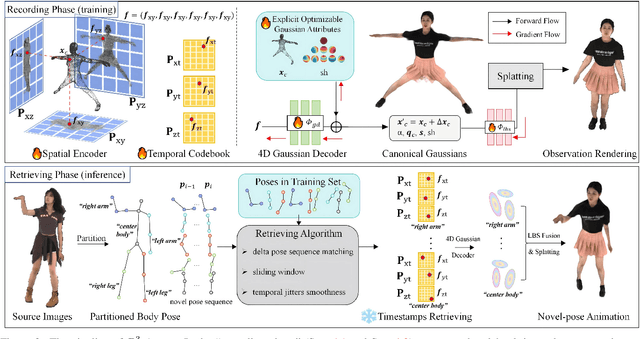
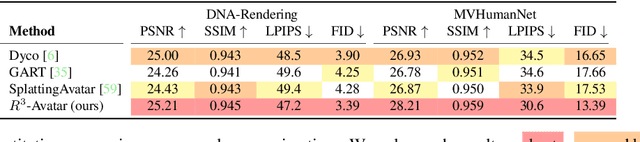

We present R3-Avatar, incorporating a temporal codebook, to overcome the inability of human avatars to be both animatable and of high-fidelity rendering quality. Existing video-based reconstruction of 3D human avatars either focuses solely on rendering, lacking animation support, or learns a pose-appearance mapping for animating, which degrades under limited training poses or complex clothing. In this paper, we adopt a "record-retrieve-reconstruct" strategy that ensures high-quality rendering from novel views while mitigating degradation in novel poses. Specifically, disambiguating timestamps record temporal appearance variations in a codebook, ensuring high-fidelity novel-view rendering, while novel poses retrieve corresponding timestamps by matching the most similar training poses for augmented appearance. Our R3-Avatar outperforms cutting-edge video-based human avatar reconstruction, particularly in overcoming visual quality degradation in extreme scenarios with limited training human poses and complex clothing.
Robustifying Fourier Features Embeddings for Implicit Neural Representations
Feb 08, 2025Implicit Neural Representations (INRs) employ neural networks to represent continuous functions by mapping coordinates to the corresponding values of the target function, with applications e.g., inverse graphics. However, INRs face a challenge known as spectral bias when dealing with scenes containing varying frequencies. To overcome spectral bias, the most common approach is the Fourier features-based methods such as positional encoding. However, Fourier features-based methods will introduce noise to output, which degrades their performances when applied to downstream tasks. In response, this paper initially hypothesizes that combining multi-layer perceptrons (MLPs) with Fourier feature embeddings mutually enhances their strengths, yet simultaneously introduces limitations inherent in Fourier feature embeddings. By presenting a simple theorem, we validate our hypothesis, which serves as a foundation for the design of our solution. Leveraging these insights, we propose the use of multi-layer perceptrons (MLPs) without additive
Dynamic Portfolio Optimization via Augmented DDPG with Quantum Price Levels-Based Trading Strategy
Jan 15, 2025



With the development of deep learning, Dynamic Portfolio Optimization (DPO) problem has received a lot of attention in recent years, not only in the field of finance but also in the field of deep learning. Some advanced research in recent years has proposed the application of Deep Reinforcement Learning (DRL) to the DPO problem, which demonstrated to be more advantageous than supervised learning in solving the DPO problem. However, there are still certain unsolved issues: 1) DRL algorithms usually have the problems of slow learning speed and high sample complexity, which is especially problematic when dealing with complex financial data. 2) researchers use DRL simply for the purpose of obtaining high returns, but pay little attention to the problem of risk control and trading strategy, which will affect the stability of model returns. In order to address these issues, in this study we revamped the intrinsic structure of the model based on the Deep Deterministic Policy Gradient (DDPG) and proposed the Augmented DDPG model. Besides, we also proposed an innovative risk control strategy based on Quantum Price Levels (QPLs) derived from Quantum Finance Theory (QFT). Our experimental results revealed that our model has better profitability as well as risk control ability with less sample complexity in the DPO problem compared to the baseline models.
* 8 pages
ToMiE: Towards Modular Growth in Enhanced SMPL Skeleton for 3D Human with Animatable Garments
Oct 10, 2024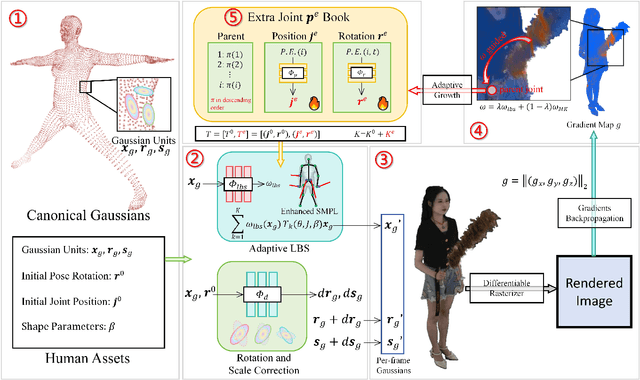
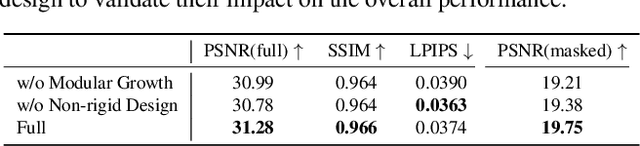
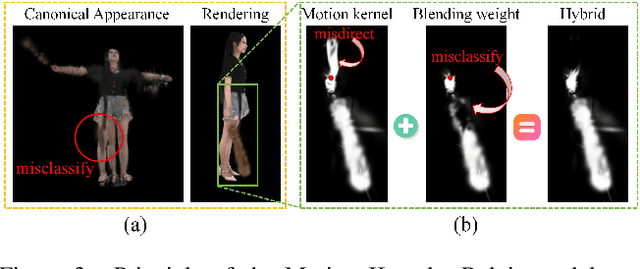

In this paper, we highlight a critical yet often overlooked factor in most 3D human tasks, namely modeling humans with complex garments. It is known that the parameterized formulation of SMPL is able to fit human skin; while complex garments, e.g., hand-held objects and loose-fitting garments, are difficult to get modeled within the unified framework, since their movements are usually decoupled with the human body. To enhance the capability of SMPL skeleton in response to this situation, we propose a modular growth strategy that enables the joint tree of the skeleton to expand adaptively. Specifically, our method, called ToMiE, consists of parent joints localization and external joints optimization. For parent joints localization, we employ a gradient-based approach guided by both LBS blending weights and motion kernels. Once the external joints are obtained, we proceed to optimize their transformations in SE(3) across different frames, enabling rendering and explicit animation. ToMiE manages to outperform other methods across various cases with garments, not only in rendering quality but also by offering free animation of grown joints, thereby enhancing the expressive ability of SMPL skeleton for a broader range of applications.