 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisionary: The World Model Carrier Built on WebGPU-Powered Gaussian Splatting Platform
Dec 09, 2025Neural rendering, particularly 3D Gaussian Splatting (3DGS), has evolved rapidly and become a key component for building world models. However, existing viewer solutions remain fragmented, heavy, or constrained by legacy pipelines, resulting in high deployment friction and limited support for dynamic content and generative models. In this work, we present Visionary, an open, web-native platform for real-time various Gaussian Splatting and meshes rendering. Built on an efficient WebGPU renderer with per-frame ONNX inference, Visionary enables dynamic neural processing while maintaining a lightweight, "click-to-run" browser experience. It introduces a standardized Gaussian Generator contract, which not only supports standard 3DGS rendering but also allows plug-and-play algorithms to generate or update Gaussians each frame. Such inference also enables us to apply feedforward generative post-processing. The platform further offers a plug in three.js library with a concise TypeScript API for seamless integration into existing web applications. Experiments show that, under identical 3DGS assets, Visionary achieves superior rendering efficiency compared to current Web viewers due to GPU-based primitive sorting. It already supports multiple variants, including MLP-based 3DGS, 4DGS, neural avatars, and style transformation or enhancement networks. By unifying inference and rendering directly in the browser, Visionary significantly lowers the barrier to reproduction, comparison, and deployment of 3DGS-family methods, serving as a unified World Model Carrier for both reconstructive and generative paradigms.
AniCrafter: Customizing Realistic Human-Centric Animation via Avatar-Background Conditioning in Video Diffusion Models
May 26, 2025Recent advances in video diffusion models have significantly improved character animation techniques. However, current approaches rely on basic structural conditions such as DWPose or SMPL-X to animate character images, limiting their effectiveness in open-domain scenarios with dynamic backgrounds or challenging human poses. In this paper, we introduce $\textbf{AniCrafter}$, a diffusion-based human-centric animation model that can seamlessly integrate and animate a given character into open-domain dynamic backgrounds while following given human motion sequences. Built on cutting-edge Image-to-Video (I2V) diffusion architectures, our model incorporates an innovative "avatar-background" conditioning mechanism that reframes open-domain human-centric animation as a restoration task, enabling more stable and versatile animation outputs. Experimental results demonstrate the superior performance of our method. Codes will be available at https://github.com/MyNiuuu/AniCrafter.
Tree-NeRV: A Tree-Structured Neural Representation for Efficient Non-Uniform Video Encoding
Apr 17, 2025Implicit Neural Representations for Videos (NeRV) have emerged as a powerful paradigm for video representation, enabling direct mappings from frame indices to video frames. However, existing NeRV-based methods do not fully exploit temporal redundancy, as they rely on uniform sampling along the temporal axis, leading to suboptimal rate-distortion (RD) performance. To address this limitation, we propose Tree-NeRV, a novel tree-structured feature representation for efficient and adaptive video encoding. Unlike conventional approaches, Tree-NeRV organizes feature representations within a Binary Search Tree (BST), enabling non-uniform sampling along the temporal axis. Additionally, we introduce an optimization-driven sampling strategy, dynamically allocating higher sampling density to regions with greater temporal variation. Extensive experiments demonstrate that Tree-NeRV achieves superior compression efficiency and reconstruction quality, outperforming prior uniform sampling-based methods. Code will be released.
All-in-One Transferring Image Compression from Human Perception to Multi-Machine Perception
Apr 17, 2025Efficiently transferring Learned Image Compression (LIC) model from human perception to machine perception is an emerging challenge in vision-centric representation learning. Existing approaches typically adapt LIC to downstream tasks in a single-task manner, which is inefficient, lacks task interaction, and results in multiple task-specific bitstreams. To address these limitations, we propose an asymmetric adaptor framework that supports multi-task adaptation within a single model. Our method introduces a shared adaptor to learn general semantic features and task-specific adaptors to preserve task-level distinctions. With only lightweight plug-in modules and a frozen base codec, our method achieves strong performance across multiple tasks while maintaining compression efficiency. Experiments on the PASCAL-Context benchmark demonstrate that our method outperforms both Fully Fine-Tuned and other Parameter Efficient Fine-Tuned (PEFT) baselines, and validating the effectiveness of multi-vision transferring.
R3-Avatar: Record and Retrieve Temporal Codebook for Reconstructing Photorealistic Human Avatars
Mar 17, 2025
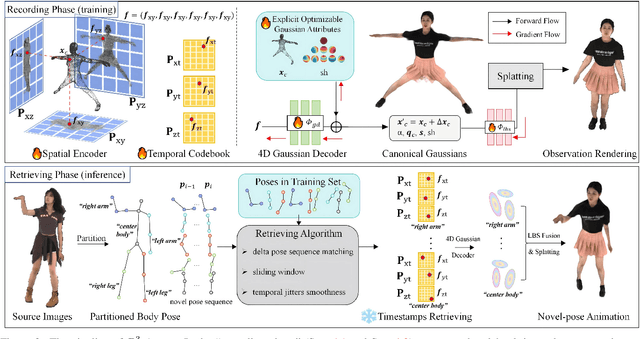
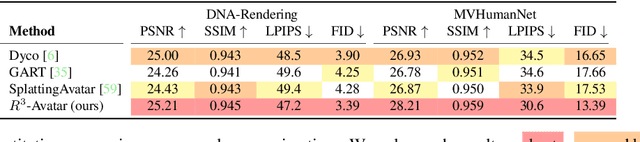

We present R3-Avatar, incorporating a temporal codebook, to overcome the inability of human avatars to be both animatable and of high-fidelity rendering quality. Existing video-based reconstruction of 3D human avatars either focuses solely on rendering, lacking animation support, or learns a pose-appearance mapping for animating, which degrades under limited training poses or complex clothing. In this paper, we adopt a "record-retrieve-reconstruct" strategy that ensures high-quality rendering from novel views while mitigating degradation in novel poses. Specifically, disambiguating timestamps record temporal appearance variations in a codebook, ensuring high-fidelity novel-view rendering, while novel poses retrieve corresponding timestamps by matching the most similar training poses for augmented appearance. Our R3-Avatar outperforms cutting-edge video-based human avatar reconstruction, particularly in overcoming visual quality degradation in extreme scenarios with limited training human poses and complex clothing.
Physics-Based Adversarial Attack on Near-Infrared Human Detector for Nighttime Surveillance Camera Systems
Dec 18, 2024
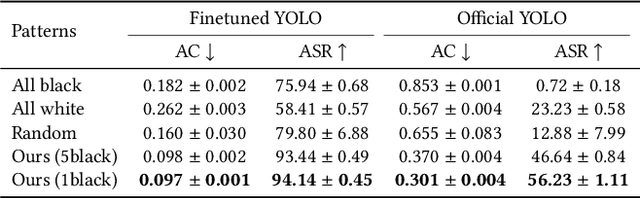


Many surveillance cameras switch between daytime and nighttime modes based on illuminance levels. During the day, the camera records ordinary RGB images through an enabled IR-cut filter. At night, the filter is disabled to capture near-infrared (NIR) light emitted from NIR LEDs typically mounted around the lens. While RGB-based AI algorithm vulnerabilities have been widely reported, the vulnerabilities of NIR-based AI have rarely been investigated. In this paper, we identify fundamental vulnerabilities in NIR-based image understanding caused by color and texture loss due to the intrinsic characteristics of clothes' reflectance and cameras' spectral sensitivity in the NIR range. We further show that the nearly co-located configuration of illuminants and cameras in existing surveillance systems facilitates concealing and fully passive attacks in the physical world. Specifically, we demonstrate how retro-reflective and insulation plastic tapes can manipulate the intensity distribution of NIR images. We showcase an attack on the YOLO-based human detector using binary patterns designed in the digital space (via black-box query and searching) and then physically realized using tapes pasted onto clothes. Our attack highlights significant reliability concerns for nighttime surveillance systems, which are intended to enhance security. Codes Available: https://github.com/MyNiuuu/AdvNIR
Bundle Adjusted Gaussian Avatars Deblurring
Nov 24, 2024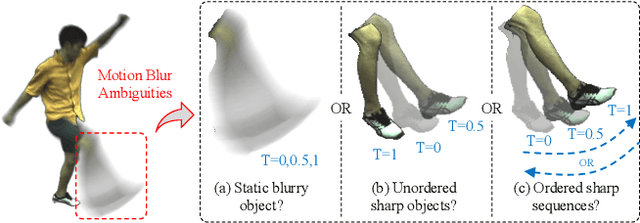
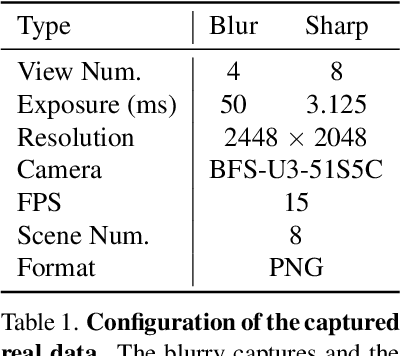
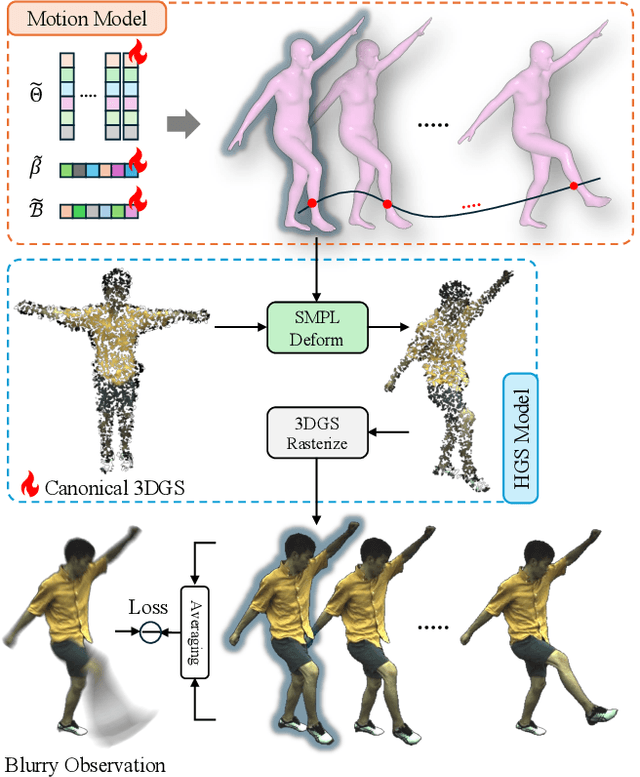
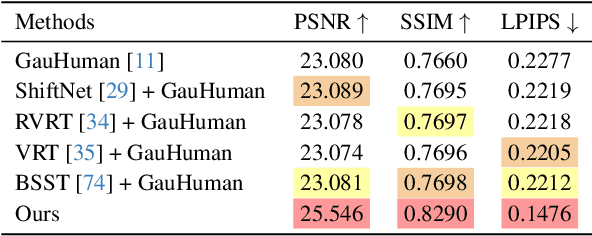
The development of 3D human avatars from multi-view videos represents a significant yet challenging task in the field. Recent advancements, including 3D Gaussian Splattings (3DGS), have markedly progressed this domain. Nonetheless, existing techniques necessitate the use of high-quality sharp images, which are often impractical to obtain in real-world settings due to variations in human motion speed and intensity. In this study, we attempt to explore deriving sharp intrinsic 3D human Gaussian avatars from blurry video footage in an end-to-end manner. Our approach encompasses a 3D-aware, physics-oriented model of blur formation attributable to human movement, coupled with a 3D human motion model to clarify ambiguities found in motion-induced blurry images. This methodology facilitates the concurrent learning of avatar model parameters and the refinement of sub-frame motion parameters from a coarse initialization. We have established benchmarks for this task through a synthetic dataset derived from existing multi-view captures, alongside a real-captured dataset acquired through a 360-degree synchronous hybrid-exposure camera system. Comprehensive evaluations demonstrate that our model surpasses existing baselines.
ToMiE: Towards Modular Growth in Enhanced SMPL Skeleton for 3D Human with Animatable Garments
Oct 10, 2024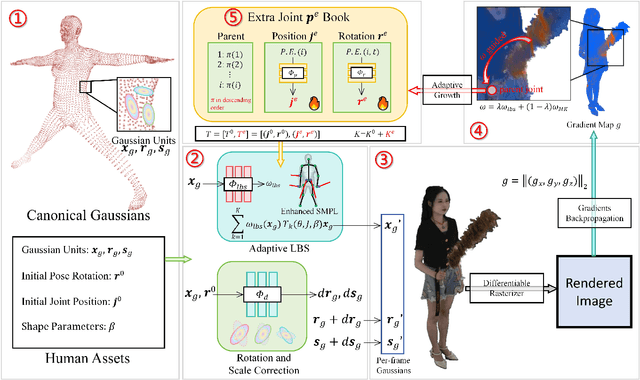
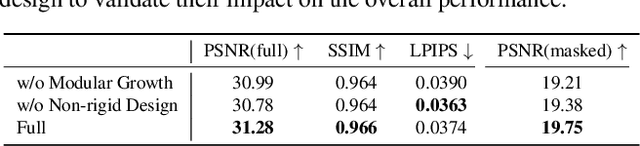
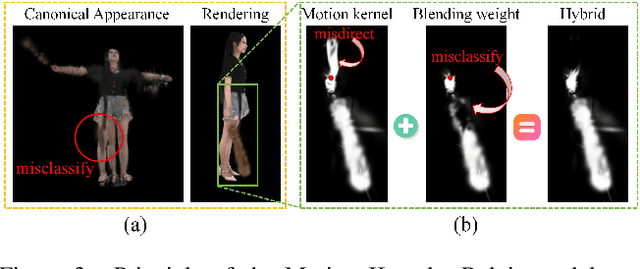

In this paper, we highlight a critical yet often overlooked factor in most 3D human tasks, namely modeling humans with complex garments. It is known that the parameterized formulation of SMPL is able to fit human skin; while complex garments, e.g., hand-held objects and loose-fitting garments, are difficult to get modeled within the unified framework, since their movements are usually decoupled with the human body. To enhance the capability of SMPL skeleton in response to this situation, we propose a modular growth strategy that enables the joint tree of the skeleton to expand adaptively. Specifically, our method, called ToMiE, consists of parent joints localization and external joints optimization. For parent joints localization, we employ a gradient-based approach guided by both LBS blending weights and motion kernels. Once the external joints are obtained, we proceed to optimize their transformations in SE(3) across different frames, enabling rendering and explicit animation. ToMiE manages to outperform other methods across various cases with garments, not only in rendering quality but also by offering free animation of grown joints, thereby enhancing the expressive ability of SMPL skeleton for a broader range of applications.
StereoCrafter: Diffusion-based Generation of Long and High-fidelity Stereoscopic 3D from Monocular Videos
Sep 11, 2024



This paper presents a novel framework for converting 2D videos to immersive stereoscopic 3D, addressing the growing demand for 3D content in immersive experience. Leveraging foundation models as priors, our approach overcomes the limitations of traditional methods and boosts the performance to ensure the high-fidelity generation required by the display devices. The proposed system consists of two main steps: depth-based video splatting for warping and extracting occlusion mask, and stereo video inpainting. We utilize pre-trained stable video diffusion as the backbone and introduce a fine-tuning protocol for the stereo video inpainting task. To handle input video with varying lengths and resolutions, we explore auto-regressive strategies and tiled processing. Finally, a sophisticated data processing pipeline has been developed to reconstruct a large-scale and high-quality dataset to support our training. Our framework demonstrates significant improvements in 2D-to-3D video conversion, offering a practical solution for creating immersive content for 3D devices like Apple Vision Pro and 3D displays. In summary, this work contributes to the field by presenting an effective method for generating high-quality stereoscopic videos from monocular input, potentially transforming how we experience digital media.
KFD-NeRF: Rethinking Dynamic NeRF with Kalman Filter
Jul 18, 2024
We introduce KFD-NeRF, a novel dynamic neural radiance field integrated with an efficient and high-quality motion reconstruction framework based on Kalman filtering. Our key idea is to model the dynamic radiance field as a dynamic system whose temporally varying states are estimated based on two sources of knowledge: observations and predictions. We introduce a novel plug-in Kalman filter guided deformation field that enables accurate deformation estimation from scene observations and predictions. We use a shallow Multi-Layer Perceptron (MLP) for observations and model the motion as locally linear to calculate predictions with motion equations. To further enhance the performance of the observation MLP, we introduce regularization in the canonical space to facilitate the network's ability to learn warping for different frames. Additionally, we employ an efficient tri-plane representation for encoding the canonical space, which has been experimentally demonstrated to converge quickly with high quality. This enables us to use a shallower observation MLP, consisting of just two layers in our implementation. We conduct experiments on synthetic and real data and compare with past dynamic NeRF methods. Our KFD-NeRF demonstrates similar or even superior rendering performance within comparable computational time and achieves state-of-the-art view synthesis performance with thorough training.