 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBundle Adjusted Gaussian Avatars Deblurring
Paper and Code
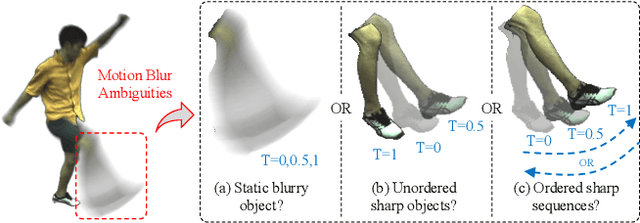
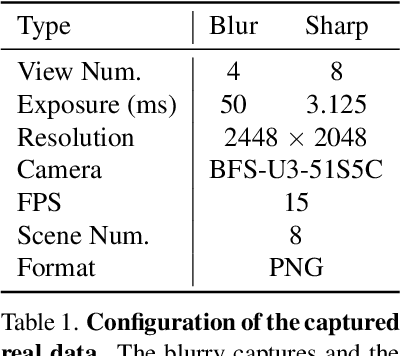
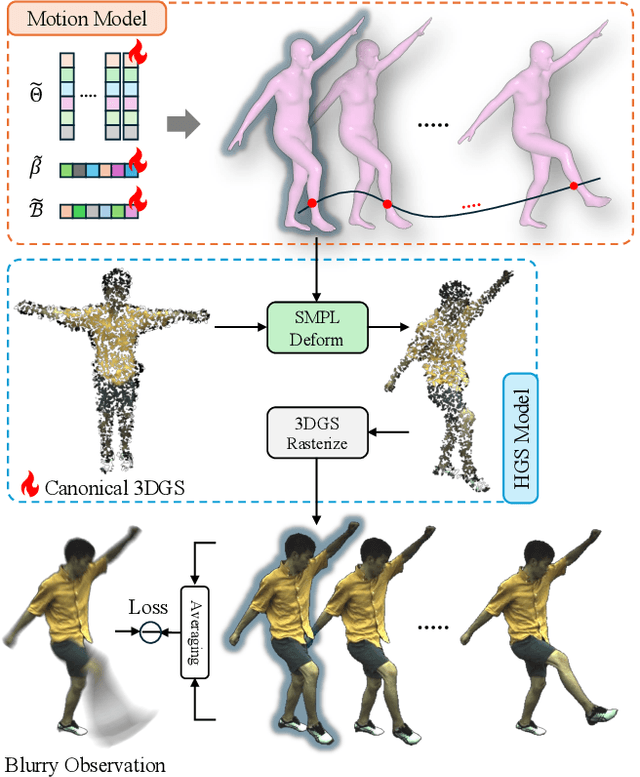
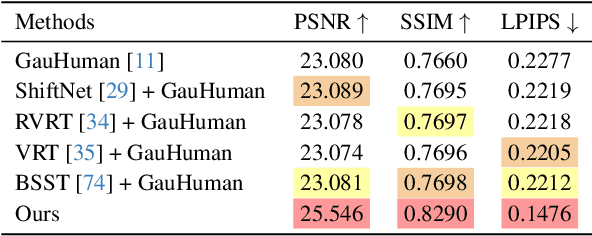
The development of 3D human avatars from multi-view videos represents a significant yet challenging task in the field. Recent advancements, including 3D Gaussian Splattings (3DGS), have markedly progressed this domain. Nonetheless, existing techniques necessitate the use of high-quality sharp images, which are often impractical to obtain in real-world settings due to variations in human motion speed and intensity. In this study, we attempt to explore deriving sharp intrinsic 3D human Gaussian avatars from blurry video footage in an end-to-end manner. Our approach encompasses a 3D-aware, physics-oriented model of blur formation attributable to human movement, coupled with a 3D human motion model to clarify ambiguities found in motion-induced blurry images. This methodology facilitates the concurrent learning of avatar model parameters and the refinement of sub-frame motion parameters from a coarse initialization. We have established benchmarks for this task through a synthetic dataset derived from existing multi-view captures, alongside a real-captured dataset acquired through a 360-degree synchronous hybrid-exposure camera system. Comprehensive evaluations demonstrate that our model surpasses existing baselines.