 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeed-Forward Gaussian Splatting from Sparse Aerial Views
May 19, 2026Reconstructing large-scale urban scenes from sparse aerial views is a crucial yet challenging task. Due to biased top-down and shallow-oblique camera poses, sparse aerial captures exhibit strong evidence imbalance: roofs and open regions are repeatedly observed, while facades, distant buildings, and occluded structures receive little multi-view support. Existing feed-forward 3D Gaussian Splatting methods directly regress a deterministic representation from sparse inputs, but this often leads to ghosting, melted facades, and stretched textures. Recent pseudo-view and video-based generative reconstruction methods use additional supervision or generative priors. However, they often lack a clear separation between observed geometry and prior-driven content, which can lead to plausible but inconsistent structures. We propose AnyCity, an observation-grounded generative reconstruction framework for sparse aerial urban scenes. AnyCity first predicts an observation-supported geometry latent to anchor reliable structures, and then uses scaffold-conditioned aerial completion tokens to predict a gated residual update for weakly constrained content before Gaussian decoding. During training, dense-to-sparse distillation transfers structural cues from dense-view reconstruction, while an aerial-adapted video diffusion prior provides fine-grained urban appearance cues through gated token conditioning. Observation-preserving objectives keep the refined representation consistent with input-supported geometry. At inference time, AnyCity reconstructs the final 3D Gaussian scene from sparse aerial views in a single feed-forward pass, achieving coherent urban novel-view synthesis with second-level inference. Experiments on synthetic, aerial-domain, UAV-textured, and real-world scenes show consistent improvements over feed-forward baselines.
Holo360D: A Large-Scale Real-World Dataset with Continuous Trajectories for Advancing Panoramic 3D Reconstruction and Beyond
Apr 24, 2026While feed-forward 3D reconstruction models have advanced rapidly, they still exhibit degraded performance on panoramas due to spherical distortions. Moreover, existing panoramic 3D datasets are predominantly collected with 360 cameras fixed at discrete locations, resulting in discontinuous trajectories. These limitations critically hinder the development of panoramic feed-forward 3D reconstruction, especially for the multi-view setting. In this paper, we present Holo360D, a comprehensive dataset containing 109,495 panoramas paired with registered point clouds, meshes, and aligned camera poses. To our knowledge, Holo360D is the first large-scale dataset that provides continuous panoramic sequences with accurately aligned high-completeness depth maps. The raw data are initially collected using a 3D laser scanner coupled with a 360 camera. Subsequently, the raw data are processed with both online and offline SLAM systems. Furthermore, to enhance the 3D data quality, a post-processing pipeline tailored for the 360 dataset is proposed, including geometry denoising, mesh hole filling, and region-specific remeshing. Finally, we establish a new benchmark by fine-tuning 3D reconstruction models on Holo360D, providing key insights into effective fine-tuning strategies. Our results demonstrate that Holo360D delivers superior training signals and provides a comprehensive benchmark for advancing panoramic 3D reconstruction models. Datasets and Code will be made publicly available.
EventVGGT: Exploring Cross-Modal Distillation for Consistent Event-based Depth Estimation
Mar 10, 2026Event cameras offer superior sensitivity to high-speed motion and extreme lighting, making event-based monocular depth estimation a promising approach for robust 3D perception in challenging conditions. However, progress is severely hindered by the scarcity of dense depth annotations. While recent annotation-free approaches mitigate this by distilling knowledge from Vision Foundation Models (VFMs), a critical limitation persists: they process event streams as independent frames. By neglecting the inherent temporal continuity of event data, these methods fail to leverage the rich temporal priors encoded in VFMs, ultimately yielding temporally inconsistent and less accurate depth predictions. To address this, we introduce EventVGGT, a novel framework that explicitly models the event stream as a coherent video sequence. To the best of our knowledge, we are the first to distill spatio-temporal and multi-view geometric priors from the Visual Geometry Grounded Transformer (VGGT) into the event domain. We achieve this via a comprehensive tri-level distillation strategy: (i) Cross-Modal Feature Mixture (CMFM) bridges the modality gap at the output level by fusing RGB and event features to generate auxiliary depth predictions; (ii) Spatio-Temporal Feature Distillation (STFD) distills VGGT's powerful spatio-temporal representations at the feature level; and (iii) Temporal Consistency Distillation (TCD) enforces cross-frame coherence at the temporal level by aligning inter-frame depth changes. Extensive experiments demonstrate that EventVGGT consistently outperforms existing methods -- reducing the absolute mean depth error at 30m by over 53\% on EventScape (from 2.30 to 1.06) -- while exhibiting robust zero-shot generalization on the unseen DENSE and MVSEC datasets.
4D-CAAL: 4D Radar-Camera Calibration and Auto-Labeling for Autonomous Driving
Jan 29, 20264D radar has emerged as a critical sensor for autonomous driving, primarily due to its enhanced capabilities in elevation measurement and higher resolution compared to traditional 3D radar. Effective integration of 4D radar with cameras requires accurate extrinsic calibration, and the development of radar-based perception algorithms demands large-scale annotated datasets. However, existing calibration methods often employ separate targets optimized for either visual or radar modalities, complicating correspondence establishment. Furthermore, manually labeling sparse radar data is labor-intensive and unreliable. To address these challenges, we propose 4D-CAAL, a unified framework for 4D radar-camera calibration and auto-labeling. Our approach introduces a novel dual-purpose calibration target design, integrating a checkerboard pattern on the front surface for camera detection and a corner reflector at the center of the back surface for radar detection. We develop a robust correspondence matching algorithm that aligns the checkerboard center with the strongest radar reflection point, enabling accurate extrinsic calibration. Subsequently, we present an auto-labeling pipeline that leverages the calibrated sensor relationship to transfer annotations from camera-based segmentations to radar point clouds through geometric projection and multi-feature optimization. Extensive experiments demonstrate that our method achieves high calibration accuracy while significantly reducing manual annotation effort, thereby accelerating the development of robust multi-modal perception systems for autonomous driving.
Beyond a Single Light: A Large-Scale Aerial Dataset for Urban Scene Reconstruction Under Varying Illumination
Dec 16, 2025Recent advances in Neural Radiance Fields and 3D Gaussian Splatting have demonstrated strong potential for large-scale UAV-based 3D reconstruction tasks by fitting the appearance of images. However, real-world large-scale captures are often based on multi-temporal data capture, where illumination inconsistencies across different times of day can significantly lead to color artifacts, geometric inaccuracies, and inconsistent appearance. Due to the lack of UAV datasets that systematically capture the same areas under varying illumination conditions, this challenge remains largely underexplored. To fill this gap, we introduceSkyLume, a large-scale, real-world UAV dataset specifically designed for studying illumination robust 3D reconstruction in urban scene modeling: (1) We collect data from 10 urban regions data comprising more than 100k high resolution UAV images (four oblique views and nadir), where each region is captured at three periods of the day to systematically isolate illumination changes. (2) To support precise evaluation of geometry and appearance, we provide per-scene LiDAR scans and accurate 3D ground-truth for assessing depth, surface normals, and reconstruction quality under varying illumination. (3) For the inverse rendering task, we introduce the Temporal Consistency Coefficient (TCC), a metric that measuress cross-time albedo stability and directly evaluates the robustness of the disentanglement of light and material. We aim for this resource to serve as a foundation that advances research and real-world evaluation in large-scale inverse rendering, geometry reconstruction, and novel view synthesis.
ArchMap: Arch-Flattening and Knowledge-Guided Vision Language Model for Tooth Counting and Structured Dental Understanding
Nov 18, 2025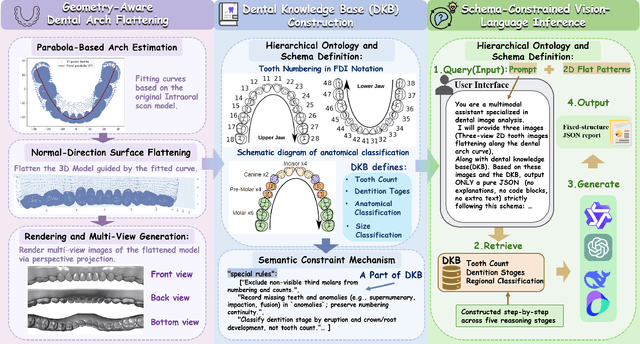
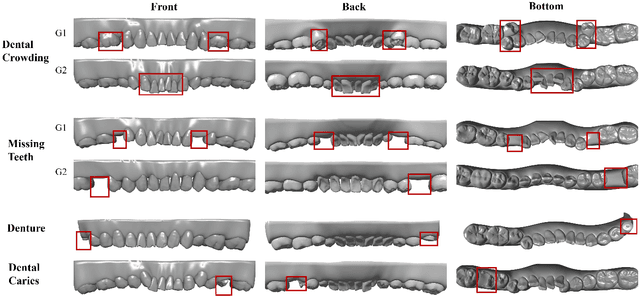
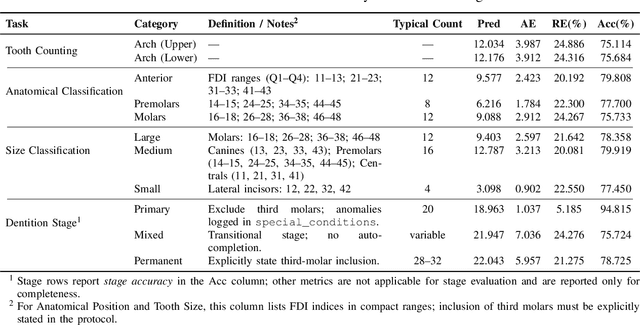
A structured understanding of intraoral 3D scans is essential for digital orthodontics. However, existing deep-learning approaches rely heavily on modality-specific training, large annotated datasets, and controlled scanning conditions, which limit generalization across devices and hinder deployment in real clinical workflows. Moreover, raw intraoral meshes exhibit substantial variation in arch pose, incomplete geometry caused by occlusion or tooth contact, and a lack of texture cues, making unified semantic interpretation highly challenging. To address these limitations, we propose ArchMap, a training-free and knowledge-guided framework for robust structured dental understanding. ArchMap first introduces a geometry-aware arch-flattening module that standardizes raw 3D meshes into spatially aligned, continuity-preserving multi-view projections. We then construct a Dental Knowledge Base (DKB) encoding hierarchical tooth ontology, dentition-stage policies, and clinical semantics to constrain the symbolic reasoning space. We validate ArchMap on 1060 pre-/post-orthodontic cases, demonstrating robust performance in tooth counting, anatomical partitioning, dentition-stage classification, and the identification of clinical conditions such as crowding, missing teeth, prosthetics, and caries. Compared with supervised pipelines and prompted VLM baselines, ArchMap achieves higher accuracy, reduced semantic drift, and superior stability under sparse or artifact-prone conditions. As a fully training-free system, ArchMap demonstrates that combining geometric normalization with ontology-guided multimodal reasoning offers a practical and scalable solution for the structured analysis of 3D intraoral scans in modern digital orthodontics.
EndoWave: Rational-Wavelet 4D Gaussian Splatting for Endoscopic Reconstruction
Oct 27, 2025In robot-assisted minimally invasive surgery, accurate 3D reconstruction from endoscopic video is vital for downstream tasks and improved outcomes. However, endoscopic scenarios present unique challenges, including photometric inconsistencies, non-rigid tissue motion, and view-dependent highlights. Most 3DGS-based methods that rely solely on appearance constraints for optimizing 3DGS are often insufficient in this context, as these dynamic visual artifacts can mislead the optimization process and lead to inaccurate reconstructions. To address these limitations, we present EndoWave, a unified spatio-temporal Gaussian Splatting framework by incorporating an optical flow-based geometric constraint and a multi-resolution rational wavelet supervision. First, we adopt a unified spatio-temporal Gaussian representation that directly optimizes primitives in a 4D domain. Second, we propose a geometric constraint derived from optical flow to enhance temporal coherence and effectively constrain the 3D structure of the scene. Third, we propose a multi-resolution rational orthogonal wavelet as a constraint, which can effectively separate the details of the endoscope and enhance the rendering performance. Extensive evaluations on two real surgical datasets, EndoNeRF and StereoMIS, demonstrate that our method EndoWave achieves state-of-the-art reconstruction quality and visual accuracy compared to the baseline method.
EndoFlow-SLAM: Real-Time Endoscopic SLAM with Flow-Constrained Gaussian Splatting
Jun 26, 2025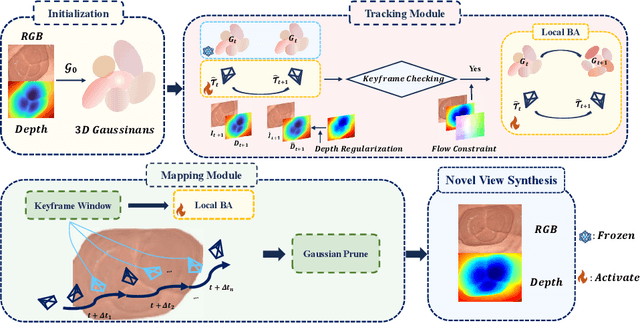
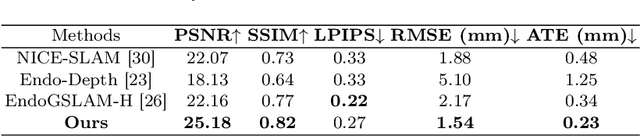
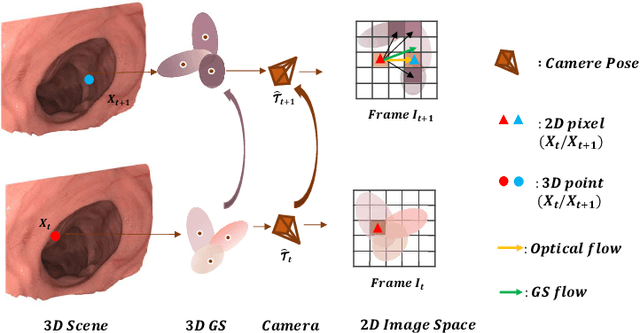
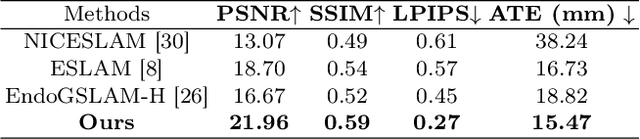
Efficient three-dimensional reconstruction and real-time visualization are critical in surgical scenarios such as endoscopy. In recent years, 3D Gaussian Splatting (3DGS) has demonstrated remarkable performance in efficient 3D reconstruction and rendering. Most 3DGS-based Simultaneous Localization and Mapping (SLAM) methods only rely on the appearance constraints for optimizing both 3DGS and camera poses. However, in endoscopic scenarios, the challenges include photometric inconsistencies caused by non-Lambertian surfaces and dynamic motion from breathing affects the performance of SLAM systems. To address these issues, we additionally introduce optical flow loss as a geometric constraint, which effectively constrains both the 3D structure of the scene and the camera motion. Furthermore, we propose a depth regularisation strategy to mitigate the problem of photometric inconsistencies and ensure the validity of 3DGS depth rendering in endoscopic scenes. In addition, to improve scene representation in the SLAM system, we improve the 3DGS refinement strategy by focusing on viewpoints corresponding to Keyframes with suboptimal rendering quality frames, achieving better rendering results. Extensive experiments on the C3VD static dataset and the StereoMIS dynamic dataset demonstrate that our method outperforms existing state-of-the-art methods in novel view synthesis and pose estimation, exhibiting high performance in both static and dynamic surgical scenes. The source code will be publicly available upon paper acceptance.
All-in-One Transferring Image Compression from Human Perception to Multi-Machine Perception
Apr 17, 2025Efficiently transferring Learned Image Compression (LIC) model from human perception to machine perception is an emerging challenge in vision-centric representation learning. Existing approaches typically adapt LIC to downstream tasks in a single-task manner, which is inefficient, lacks task interaction, and results in multiple task-specific bitstreams. To address these limitations, we propose an asymmetric adaptor framework that supports multi-task adaptation within a single model. Our method introduces a shared adaptor to learn general semantic features and task-specific adaptors to preserve task-level distinctions. With only lightweight plug-in modules and a frozen base codec, our method achieves strong performance across multiple tasks while maintaining compression efficiency. Experiments on the PASCAL-Context benchmark demonstrate that our method outperforms both Fully Fine-Tuned and other Parameter Efficient Fine-Tuned (PEFT) baselines, and validating the effectiveness of multi-vision transferring.
Physics-Based Adversarial Attack on Near-Infrared Human Detector for Nighttime Surveillance Camera Systems
Dec 18, 2024
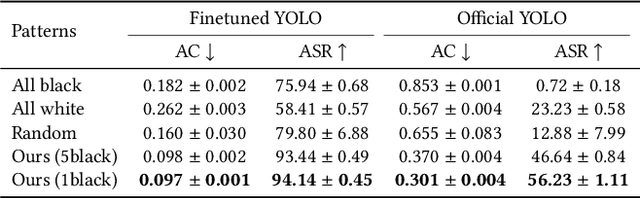


Many surveillance cameras switch between daytime and nighttime modes based on illuminance levels. During the day, the camera records ordinary RGB images through an enabled IR-cut filter. At night, the filter is disabled to capture near-infrared (NIR) light emitted from NIR LEDs typically mounted around the lens. While RGB-based AI algorithm vulnerabilities have been widely reported, the vulnerabilities of NIR-based AI have rarely been investigated. In this paper, we identify fundamental vulnerabilities in NIR-based image understanding caused by color and texture loss due to the intrinsic characteristics of clothes' reflectance and cameras' spectral sensitivity in the NIR range. We further show that the nearly co-located configuration of illuminants and cameras in existing surveillance systems facilitates concealing and fully passive attacks in the physical world. Specifically, we demonstrate how retro-reflective and insulation plastic tapes can manipulate the intensity distribution of NIR images. We showcase an attack on the YOLO-based human detector using binary patterns designed in the digital space (via black-box query and searching) and then physically realized using tapes pasted onto clothes. Our attack highlights significant reliability concerns for nighttime surveillance systems, which are intended to enhance security. Codes Available: https://github.com/MyNiuuu/AdvNIR