 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll-in-One Transferring Image Compression from Human Perception to Multi-Machine Perception
Apr 17, 2025Efficiently transferring Learned Image Compression (LIC) model from human perception to machine perception is an emerging challenge in vision-centric representation learning. Existing approaches typically adapt LIC to downstream tasks in a single-task manner, which is inefficient, lacks task interaction, and results in multiple task-specific bitstreams. To address these limitations, we propose an asymmetric adaptor framework that supports multi-task adaptation within a single model. Our method introduces a shared adaptor to learn general semantic features and task-specific adaptors to preserve task-level distinctions. With only lightweight plug-in modules and a frozen base codec, our method achieves strong performance across multiple tasks while maintaining compression efficiency. Experiments on the PASCAL-Context benchmark demonstrate that our method outperforms both Fully Fine-Tuned and other Parameter Efficient Fine-Tuned (PEFT) baselines, and validating the effectiveness of multi-vision transferring.
Implicit Neural Image Field for Biological Microscopy Image Compression
May 29, 2024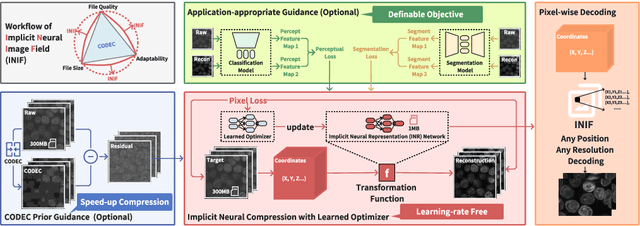


The rapid pace of innovation in biological microscopy imaging has led to large images, putting pressure on data storage and impeding efficient sharing, management, and visualization. This necessitates the development of efficient compression solutions. Traditional CODEC methods struggle to adapt to the diverse bioimaging data and often suffer from sub-optimal compression. In this study, we propose an adaptive compression workflow based on Implicit Neural Representation (INR). This approach permits application-specific compression objectives, capable of compressing images of any shape and arbitrary pixel-wise decompression. We demonstrated on a wide range of microscopy images from real applications that our workflow not only achieved high, controllable compression ratios (e.g., 512x) but also preserved detailed information critical for downstream analysis.
MoEC: Mixture of Experts Implicit Neural Compression
Dec 03, 2023
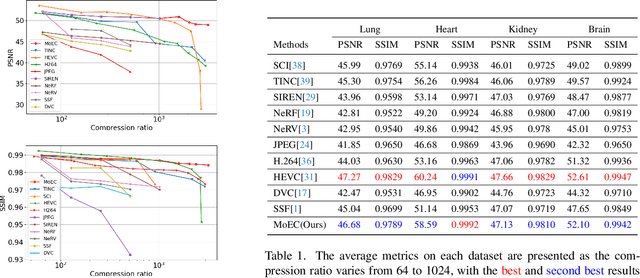
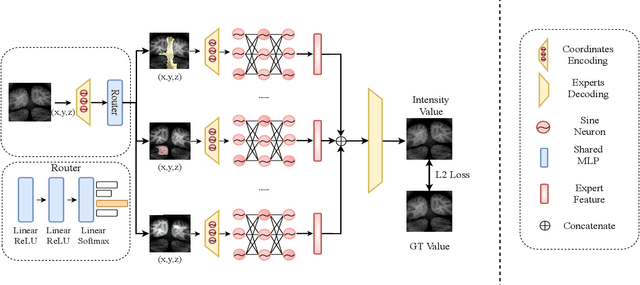
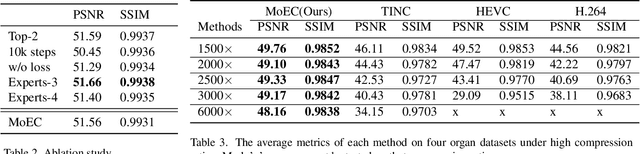
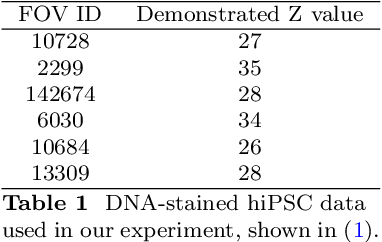
Emerging Implicit Neural Representation (INR) is a promising data compression technique, which represents the data using the parameters of a Deep Neural Network (DNN). Existing methods manually partition a complex scene into local regions and overfit the INRs into those regions. However, manually designing the partition scheme for a complex scene is very challenging and fails to jointly learn the partition and INRs. To solve the problem, we propose MoEC, a novel implicit neural compression method based on the theory of mixture of experts. Specifically, we use a gating network to automatically assign a specific INR to a 3D point in the scene. The gating network is trained jointly with the INRs of different local regions. Compared with block-wise and tree-structured partitions, our learnable partition can adaptively find the optimal partition in an end-to-end manner. We conduct detailed experiments on massive and diverse biomedical data to demonstrate the advantages of MoEC against existing approaches. In most of experiment settings, we have achieved state-of-the-art results. Especially in cases of extreme compression ratios, such as 6000x, we are able to uphold the PSNR of 48.16.
QD-BEV : Quantization-aware View-guided Distillation for Multi-view 3D Object Detection
Aug 21, 2023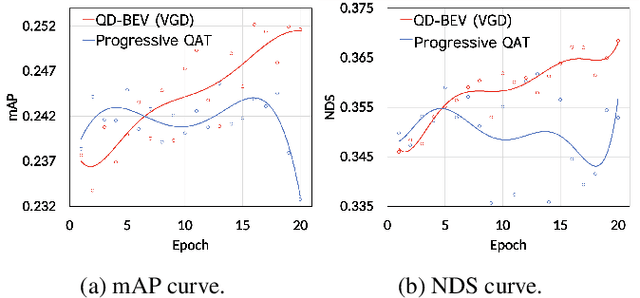
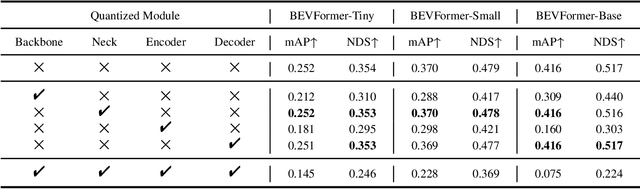
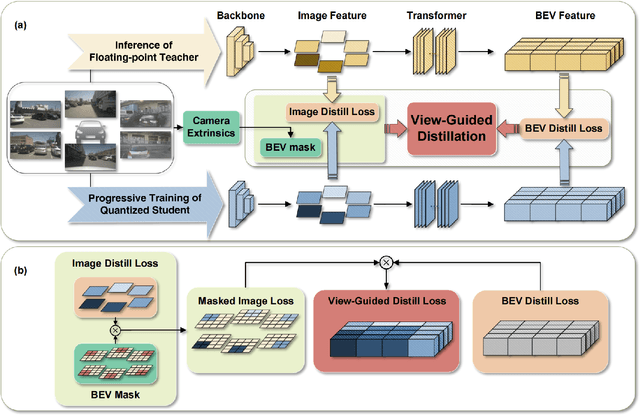
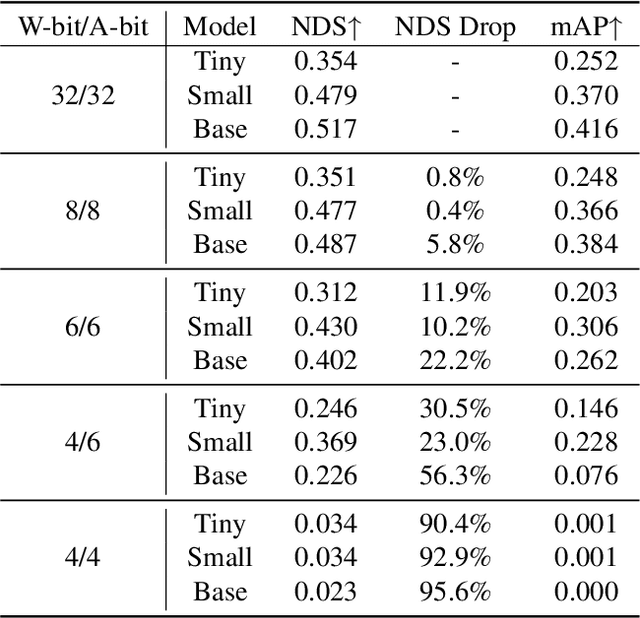
Multi-view 3D detection based on BEV (bird-eye-view) has recently achieved significant improvements. However, the huge memory consumption of state-of-the-art models makes it hard to deploy them on vehicles, and the non-trivial latency will affect the real-time perception of streaming applications. Despite the wide application of quantization to lighten models, we show in our paper that directly applying quantization in BEV tasks will 1) make the training unstable, and 2) lead to intolerable performance degradation. To solve these issues, our method QD-BEV enables a novel view-guided distillation (VGD) objective, which can stabilize the quantization-aware training (QAT) while enhancing the model performance by leveraging both image features and BEV features. Our experiments show that QD-BEV achieves similar or even better accuracy than previous methods with significant efficiency gains. On the nuScenes datasets, the 4-bit weight and 6-bit activation quantized QD-BEV-Tiny model achieves 37.2% NDS with only 15.8 MB model size, outperforming BevFormer-Tiny by 1.8% with an 8x model compression. On the Small and Base variants, QD-BEV models also perform superbly and achieve 47.9% NDS (28.2 MB) and 50.9% NDS (32.9 MB), respectively.