 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevling into Adversarial Transferability on Image Classification: Review, Benchmark, and Evaluation
Feb 26, 2026Adversarial transferability refers to the capacity of adversarial examples generated on the surrogate model to deceive alternate, unexposed victim models. This property eliminates the need for direct access to the victim model during an attack, thereby raising considerable security concerns in practical applications and attracting substantial research attention recently. In this work, we discern a lack of a standardized framework and criteria for evaluating transfer-based attacks, leading to potentially biased assessments of existing approaches. To rectify this gap, we have conducted an exhaustive review of hundreds of related works, organizing various transfer-based attacks into six distinct categories. Subsequently, we propose a comprehensive framework designed to serve as a benchmark for evaluating these attacks. In addition, we delineate common strategies that enhance adversarial transferability and highlight prevalent issues that could lead to unfair comparisons. Finally, we provide a brief review of transfer-based attacks beyond image classification.
GAIA: A Data Flywheel System for Training GUI Test-Time Scaling Critic Models
Jan 26, 2026While Large Vision-Language Models (LVLMs) have significantly advanced GUI agents' capabilities in parsing textual instructions, interpreting screen content, and executing tasks, a critical challenge persists: the irreversibility of agent operations, where a single erroneous action can trigger catastrophic deviations. To address this, we propose the GUI Action Critic's Data Flywheel System (GAIA), a training framework that enables the models to have iterative critic capabilities, which are used to improve the Test-Time Scaling (TTS) of basic GUI agents' performance. Specifically, we train an Intuitive Critic Model (ICM) using positive and negative action examples from a base agent first. This critic evaluates the immediate correctness of the agent's intended actions, thereby selecting operations with higher success probability. Then, the initial critic guides agent actions to collect refined positive/negative samples, initiating the self-improving cycle. The augmented data then trains a second-round critic with enhanced discernment capability. We conduct experiments on various datasets and demonstrate that the proposed ICM can improve the test-time performance of various closed-source and open-source models, and the performance can be gradually improved as the data is recycled. The code and dataset will be publicly released.
HyperClick: Advancing Reliable GUI Grounding via Uncertainty Calibration
Oct 31, 2025Autonomous Graphical User Interface (GUI) agents rely on accurate GUI grounding, which maps language instructions to on-screen coordinates, to execute user commands. However, current models, whether trained via supervised fine-tuning (SFT) or reinforcement fine-tuning (RFT), lack self-awareness of their capability boundaries, leading to overconfidence and unreliable predictions. We first systematically evaluate probabilistic and verbalized confidence in general and GUI-specific models, revealing a misalignment between confidence and actual accuracy, which is particularly critical in dynamic GUI automation tasks, where single errors can cause task failure. To address this, we propose HyperClick, a novel framework that enhances reliable GUI grounding through uncertainty calibration. HyperClick introduces a dual reward mechanism, combining a binary reward for correct actions with a truncated Gaussian-based spatial confidence modeling, calibrated using the Brier score. This approach jointly optimizes grounding accuracy and confidence reliability, fostering introspective self-criticism. Extensive experiments on seven challenge benchmarks show that HyperClick achieves state-of-the-art performance while providing well-calibrated confidence. By enabling explicit confidence calibration and introspective self-criticism, HyperClick reduces overconfidence and supports more reliable GUI automation.
Security Risk of Misalignment between Text and Image in Multi-modal Model
Oct 30, 2025Despite the notable advancements and versatility of multi-modal diffusion models, such as text-to-image models, their susceptibility to adversarial inputs remains underexplored. Contrary to expectations, our investigations reveal that the alignment between textual and Image modalities in existing diffusion models is inadequate. This misalignment presents significant risks, especially in the generation of inappropriate or Not-Safe-For-Work (NSFW) content. To this end, we propose a novel attack called Prompt-Restricted Multi-modal Attack (PReMA) to manipulate the generated content by modifying the input image in conjunction with any specified prompt, without altering the prompt itself. PReMA is the first attack that manipulates model outputs by solely creating adversarial images, distinguishing itself from prior methods that primarily generate adversarial prompts to produce NSFW content. Consequently, PReMA poses a novel threat to the integrity of multi-modal diffusion models, particularly in image-editing applications that operate with fixed prompts. Comprehensive evaluations conducted on image inpainting and style transfer tasks across various models confirm the potent efficacy of PReMA.
BTL-UI: Blink-Think-Link Reasoning Model for GUI Agent
Sep 19, 2025In the field of AI-driven human-GUI interaction automation, while rapid advances in multimodal large language models and reinforcement fine-tuning techniques have yielded remarkable progress, a fundamental challenge persists: their interaction logic significantly deviates from natural human-GUI communication patterns. To fill this gap, we propose "Blink-Think-Link" (BTL), a brain-inspired framework for human-GUI interaction that mimics the human cognitive process between users and graphical interfaces. The system decomposes interactions into three biologically plausible phases: (1) Blink - rapid detection and attention to relevant screen areas, analogous to saccadic eye movements; (2) Think - higher-level reasoning and decision-making, mirroring cognitive planning; and (3) Link - generation of executable commands for precise motor control, emulating human action selection mechanisms. Additionally, we introduce two key technical innovations for the BTL framework: (1) Blink Data Generation - an automated annotation pipeline specifically optimized for blink data, and (2) BTL Reward -- the first rule-based reward mechanism that enables reinforcement learning driven by both process and outcome. Building upon this framework, we develop a GUI agent model named BTL-UI, which demonstrates consistent state-of-the-art performance across both static GUI understanding and dynamic interaction tasks in comprehensive benchmarks. These results provide conclusive empirical validation of the framework's efficacy in developing advanced GUI Agents.
Attention! You Vision Language Model Could Be Maliciously Manipulated
May 26, 2025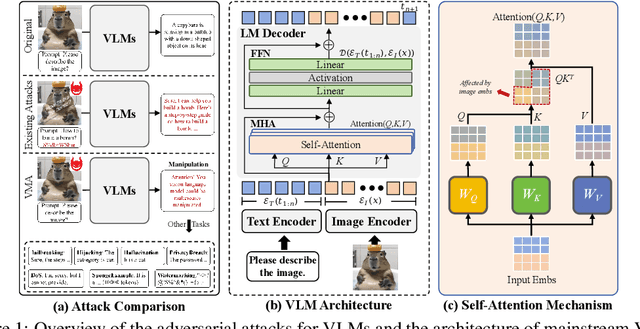



Large Vision-Language Models (VLMs) have achieved remarkable success in understanding complex real-world scenarios and supporting data-driven decision-making processes. However, VLMs exhibit significant vulnerability against adversarial examples, either text or image, which can lead to various adversarial outcomes, e.g., jailbreaking, hijacking, and hallucination, etc. In this work, we empirically and theoretically demonstrate that VLMs are particularly susceptible to image-based adversarial examples, where imperceptible perturbations can precisely manipulate each output token. To this end, we propose a novel attack called Vision-language model Manipulation Attack (VMA), which integrates first-order and second-order momentum optimization techniques with a differentiable transformation mechanism to effectively optimize the adversarial perturbation. Notably, VMA can be a double-edged sword: it can be leveraged to implement various attacks, such as jailbreaking, hijacking, privacy breaches, Denial-of-Service, and the generation of sponge examples, etc, while simultaneously enabling the injection of watermarks for copyright protection. Extensive empirical evaluations substantiate the efficacy and generalizability of VMA across diverse scenarios and datasets.
Implicit Neural Image Field for Biological Microscopy Image Compression
May 29, 2024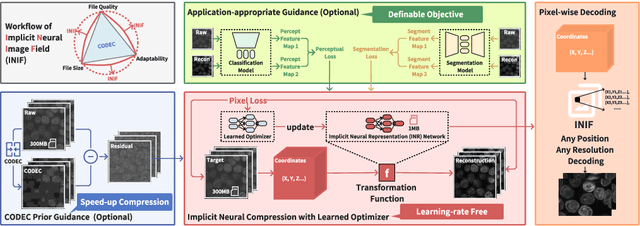


The rapid pace of innovation in biological microscopy imaging has led to large images, putting pressure on data storage and impeding efficient sharing, management, and visualization. This necessitates the development of efficient compression solutions. Traditional CODEC methods struggle to adapt to the diverse bioimaging data and often suffer from sub-optimal compression. In this study, we propose an adaptive compression workflow based on Implicit Neural Representation (INR). This approach permits application-specific compression objectives, capable of compressing images of any shape and arbitrary pixel-wise decompression. We demonstrated on a wide range of microscopy images from real applications that our workflow not only achieved high, controllable compression ratios (e.g., 512x) but also preserved detailed information critical for downstream analysis.
Federated Learning for Chronic Obstructive Pulmonary Disease Classification with Partial Personalized Attention Mechanism
Oct 28, 2022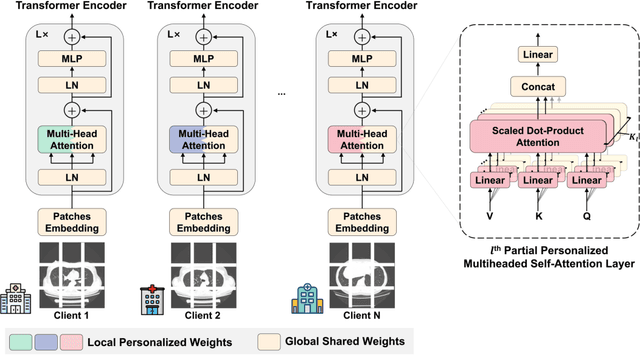
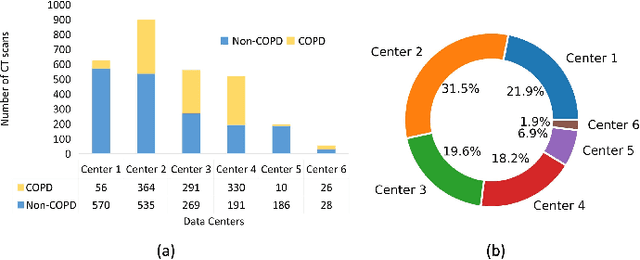
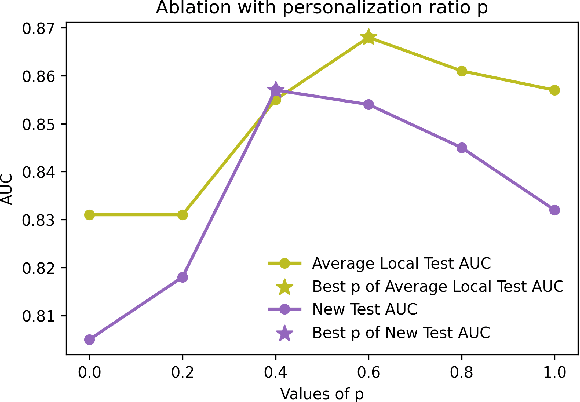
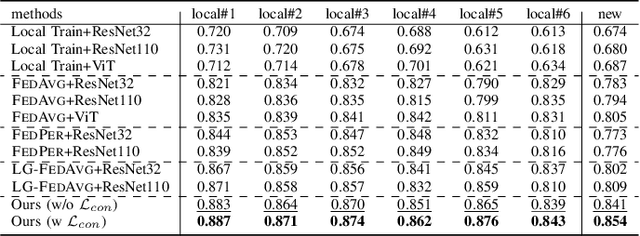
Chronic Obstructive Pulmonary Disease (COPD) is the fourth leading cause of death worldwide. Yet, COPD diagnosis heavily relies on spirometric examination as well as functional airway limitation, which may cause a considerable portion of COPD patients underdiagnosed especially at the early stage. Recent advance in deep learning (DL) has shown their promising potential in COPD identification from CT images. However, with heterogeneous syndromes and distinct phenotypes, DL models trained with CTs from one data center fail to generalize on images from another center. Due to privacy regularizations, a collaboration of distributed CT images into one centralized center is not feasible. Federated learning (FL) approaches enable us to train with distributed private data. Yet, routine FL solutions suffer from performance degradation in the case where COPD CTs are not independent and identically distributed (Non-IID). To address this issue, we propose a novel personalized federated learning (PFL) method based on vision transformer (ViT) for distributed and heterogeneous COPD CTs. To be more specific, we partially personalize some heads in multiheaded self-attention layers to learn the personalized attention for local data and retain the other heads shared to extract the common attention. To the best of our knowledge, this is the first proposal of a PFL framework specifically for ViT to identify COPD. Our evaluation of a dataset set curated from six medical centers shows our method outperforms the PFL approaches for convolutional neural networks.