 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoc-V*:Coarse-to-Fine Interactive Visual Reasoning for Multi-Page Document VQA
Apr 15, 2026Multi-page Document Visual Question Answering requires reasoning over semantics, layouts, and visual elements in long, visually dense documents. Existing OCR-free methods face a trade-off between capacity and precision: end-to-end models scale poorly with document length, while visual retrieval-based pipelines are brittle and passive. We propose Doc-$V^*$, an \textbf{OCR-free agentic} framework that casts multi-page DocVQA as sequential evidence aggregation. Doc-$V^*$ begins with a thumbnail overview, then actively navigates via semantic retrieval and targeted page fetching, and aggregates evidence in a structured working memory for grounded reasoning. Trained by imitation learning from expert trajectories and further optimized with Group Relative Policy Optimization, Doc-$V^*$ balances answer accuracy with evidence-seeking efficiency. Across five benchmarks, Doc-$V^*$ outperforms open-source baselines and approaches proprietary models, improving out-of-domain performance by up to \textbf{47.9\%} over RAG baseline. Other results reveal effective evidence aggregation with selective attention, not increased input pages.
Q-Mask: Query-driven Causal Masks for Text Anchoring in OCR-Oriented Vision-Language Models
Mar 31, 2026Optical Character Recognition (OCR) is increasingly regarded as a foundational capability for modern vision-language models (VLMs), enabling them not only to read text in images but also to support downstream reasoning in real-world visual question answering (VQA). However, practical applications further require reliable text anchors, i.e., accurately grounding queried text to its corresponding spatial region. To systematically evaluate this capability, we introduce TextAnchor-Bench (TABench), a benchmark for fine-grained text-region grounding, which reveals that both general-purpose and OCR-specific VLMs still struggle to establish accurate and stable text anchors. To address this limitation, we propose Q-Mask, a precise OCR framework built upon a causal query-driven mask decoder (CQMD). Inspired by chain-of-thought reasoning, Q-Mask performs causal visual decoding that sequentially generates query-conditioned visual masks before producing the final OCR output. This visual CoT paradigm disentangles where the text is from what the text is, enforcing grounded evidence acquisition prior to recognition and enabling explicit text anchor construction during inference. To train CQMD, we construct TextAnchor-26M, a large-scale dataset of image-text pairs annotated with fine-grained masks corresponding to specific textual elements, encouraging stable text-region correspondences and injecting strong spatial priors into VLM training. Extensive experiments demonstrate that Q-Mask substantially improves text anchoring and understanding across diverse visual scenes.
IMTBench: A Multi-Scenario Cross-Modal Collaborative Evaluation Benchmark for In-Image Machine Translation
Mar 11, 2026End-to-end In-Image Machine Translation (IIMT) aims to convert text embedded within an image into a target language while preserving the original visual context, layout, and rendering style. However, existing IIMT benchmarks are largely synthetic and thus fail to reflect real-world complexity, while current evaluation protocols focus on single-modality metrics and overlook cross-modal faithfulness between rendered text and model outputs. To address these shortcomings, we present In-image Machine Translation Benchmark (IMTBench), a new benchmark of 2,500 image translation samples covering four practical scenarios and nine languages. IMTBench supports multi-aspect evaluation, including translation quality, background preservation, overall image quality, and a cross-modal alignment score that measures consistency between the translated text produced by the model and the text rendered in the translated image. We benchmark strong commercial cascade systems, and both closed- and open-source unified multi-modal models, and observe large performance gaps across scenarios and languages, especially on natural scenes and resource-limited languages, highlighting substantial headroom for end-to-end image text translation. We hope IMTBench establishes a standardized benchmark to accelerate progress in this emerging task.
EMO-R3: Reflective Reinforcement Learning for Emotional Reasoning in Multimodal Large Language Models
Feb 27, 2026Multimodal Large Language Models (MLLMs) have shown remarkable progress in visual reasoning and understanding tasks but still struggle to capture the complexity and subjectivity of human emotions. Existing approaches based on supervised fine-tuning often suffer from limited generalization and poor interpretability, while reinforcement learning methods such as Group Relative Policy Optimization fail to align with the intrinsic characteristics of emotional cognition. To address these challenges, we propose Reflective Reinforcement Learning for Emotional Reasoning (EMO-R3), a framework designed to enhance the emotional reasoning ability of MLLMs. Specifically, we introduce Structured Emotional Thinking to guide the model to perform step-by-step emotional reasoning in a structured and interpretable manner, and design a Reflective Emotional Reward that enables the model to re-evaluate its reasoning based on visual-text consistency and emotional coherence. Extensive experiments demonstrate that EMO-R3 significantly improves both the interpretability and emotional intelligence of MLLMs, achieving superior performance across multiple visual emotional understanding benchmarks.
PositionOCR: Augmenting Positional Awareness in Multi-Modal Models via Hybrid Specialist Integration
Feb 22, 2026In recent years, Multi-modal Large Language Models (MLLMs) have achieved strong performance in OCR-centric Visual Question Answering (VQA) tasks, illustrating their capability to process heterogeneous data and exhibit adaptability across varied contexts. However, these MLLMs rely on a Large Language Model (LLM) as the decoder, which is primarily designed for linguistic processing, and thus inherently lacks the positional reasoning required for precise visual tasks, such as text spotting and text grounding. Additionally, the extensive parameters of MLLMs necessitate substantial computational resources and large-scale data for effective training. Conversely, text spotting specialists achieve state-of-the-art coordinate predictions but lack semantic reasoning capabilities. This dichotomy motivates our key research question: Can we synergize the efficiency of specialists with the contextual power of LLMs to create a positionally-accurate MLLM? To overcome these challenges, we introduce PositionOCR, a parameter-efficient hybrid architecture that seamlessly integrates a text spotting model's positional strengths with an LLM's contextual reasoning. Comprising 131M trainable parameters, this framework demonstrates outstanding multi-modal processing capabilities, particularly excelling in tasks such as text grounding and text spotting, consistently surpassing traditional MLLMs.
GAIA: A Data Flywheel System for Training GUI Test-Time Scaling Critic Models
Jan 26, 2026While Large Vision-Language Models (LVLMs) have significantly advanced GUI agents' capabilities in parsing textual instructions, interpreting screen content, and executing tasks, a critical challenge persists: the irreversibility of agent operations, where a single erroneous action can trigger catastrophic deviations. To address this, we propose the GUI Action Critic's Data Flywheel System (GAIA), a training framework that enables the models to have iterative critic capabilities, which are used to improve the Test-Time Scaling (TTS) of basic GUI agents' performance. Specifically, we train an Intuitive Critic Model (ICM) using positive and negative action examples from a base agent first. This critic evaluates the immediate correctness of the agent's intended actions, thereby selecting operations with higher success probability. Then, the initial critic guides agent actions to collect refined positive/negative samples, initiating the self-improving cycle. The augmented data then trains a second-round critic with enhanced discernment capability. We conduct experiments on various datasets and demonstrate that the proposed ICM can improve the test-time performance of various closed-source and open-source models, and the performance can be gradually improved as the data is recycled. The code and dataset will be publicly released.
Xiaomi MiMo-VL-Miloco Technical Report
Dec 22, 2025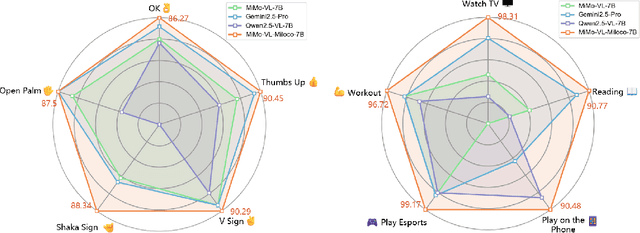
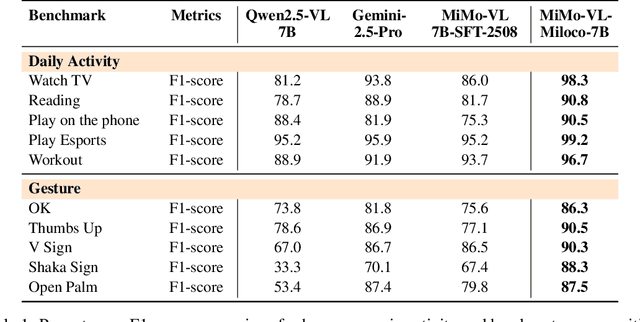

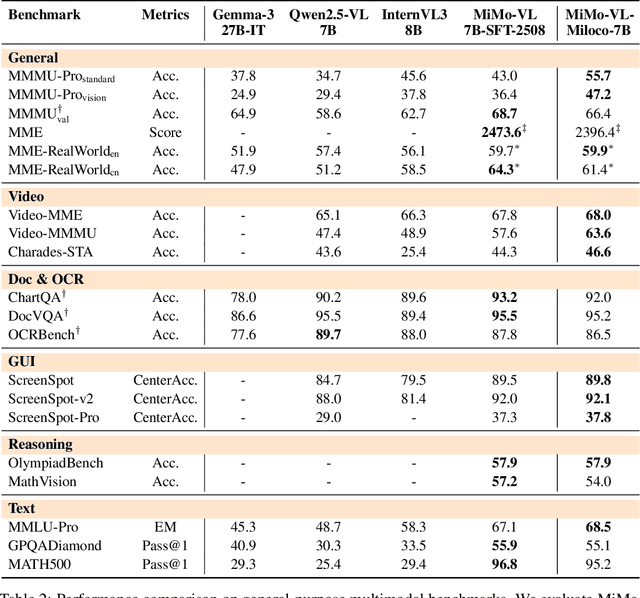
We open-source MiMo-VL-Miloco-7B and its quantized variant MiMo-VL-Miloco-7B-GGUF, a pair of home-centric vision-language models that achieve strong performance on both home-scenario understanding and general multimodal reasoning. Built on the MiMo-VL-7B backbone, MiMo-VL-Miloco-7B is specialized for smart-home environments, attaining leading F1 scores on gesture recognition and common home-scenario understanding, while also delivering consistent gains across video benchmarks such as Video-MME, Video-MMMU, and Charades-STA, as well as language understanding benchmarks including MMMU-Pro and MMLU-Pro. In our experiments, MiMo-VL-Miloco-7B outperforms strong closed-source and open-source baselines on home-scenario understanding and several multimodal reasoning benchmarks. To balance specialization and generality, we design a two-stage training pipeline that combines supervised fine-tuning with reinforcement learning based on Group Relative Policy Optimization, leveraging efficient multi-domain data. We further incorporate chain-of-thought supervision and token-budget-aware reasoning, enabling the model to learn knowledge in a data-efficient manner while also performing reasoning efficiently. Our analysis shows that targeted home-scenario training not only enhances activity and gesture understanding, but also improves text-only reasoning with only modest trade-offs on document-centric tasks. Model checkpoints, quantized GGUF weights, and our home-scenario evaluation toolkit are publicly available at https://github.com/XiaoMi/xiaomi-mimo-vl-miloco to support research and deployment in real-world smart-home applications.
HyperClick: Advancing Reliable GUI Grounding via Uncertainty Calibration
Oct 31, 2025Autonomous Graphical User Interface (GUI) agents rely on accurate GUI grounding, which maps language instructions to on-screen coordinates, to execute user commands. However, current models, whether trained via supervised fine-tuning (SFT) or reinforcement fine-tuning (RFT), lack self-awareness of their capability boundaries, leading to overconfidence and unreliable predictions. We first systematically evaluate probabilistic and verbalized confidence in general and GUI-specific models, revealing a misalignment between confidence and actual accuracy, which is particularly critical in dynamic GUI automation tasks, where single errors can cause task failure. To address this, we propose HyperClick, a novel framework that enhances reliable GUI grounding through uncertainty calibration. HyperClick introduces a dual reward mechanism, combining a binary reward for correct actions with a truncated Gaussian-based spatial confidence modeling, calibrated using the Brier score. This approach jointly optimizes grounding accuracy and confidence reliability, fostering introspective self-criticism. Extensive experiments on seven challenge benchmarks show that HyperClick achieves state-of-the-art performance while providing well-calibrated confidence. By enabling explicit confidence calibration and introspective self-criticism, HyperClick reduces overconfidence and supports more reliable GUI automation.
BTL-UI: Blink-Think-Link Reasoning Model for GUI Agent
Sep 19, 2025In the field of AI-driven human-GUI interaction automation, while rapid advances in multimodal large language models and reinforcement fine-tuning techniques have yielded remarkable progress, a fundamental challenge persists: their interaction logic significantly deviates from natural human-GUI communication patterns. To fill this gap, we propose "Blink-Think-Link" (BTL), a brain-inspired framework for human-GUI interaction that mimics the human cognitive process between users and graphical interfaces. The system decomposes interactions into three biologically plausible phases: (1) Blink - rapid detection and attention to relevant screen areas, analogous to saccadic eye movements; (2) Think - higher-level reasoning and decision-making, mirroring cognitive planning; and (3) Link - generation of executable commands for precise motor control, emulating human action selection mechanisms. Additionally, we introduce two key technical innovations for the BTL framework: (1) Blink Data Generation - an automated annotation pipeline specifically optimized for blink data, and (2) BTL Reward -- the first rule-based reward mechanism that enables reinforcement learning driven by both process and outcome. Building upon this framework, we develop a GUI agent model named BTL-UI, which demonstrates consistent state-of-the-art performance across both static GUI understanding and dynamic interaction tasks in comprehensive benchmarks. These results provide conclusive empirical validation of the framework's efficacy in developing advanced GUI Agents.
Marten: Visual Question Answering with Mask Generation for Multi-modal Document Understanding
Mar 18, 2025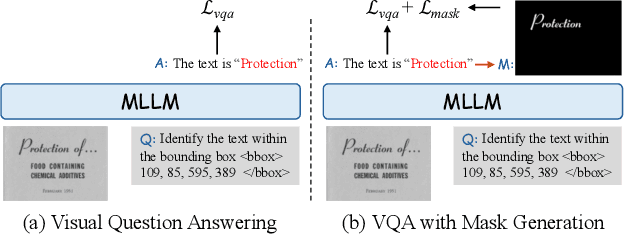
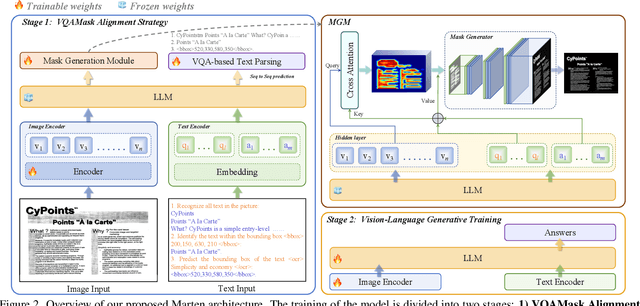
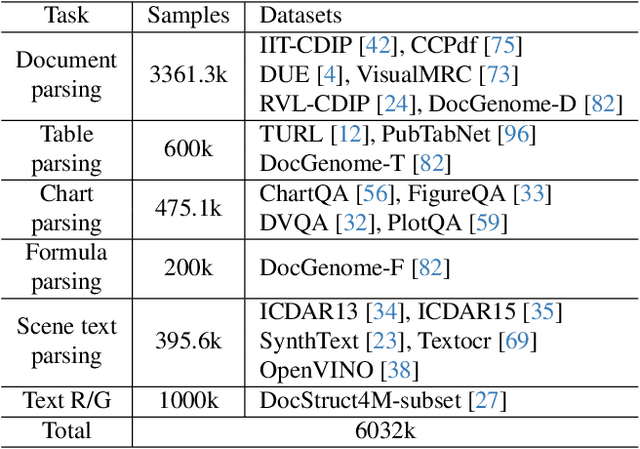
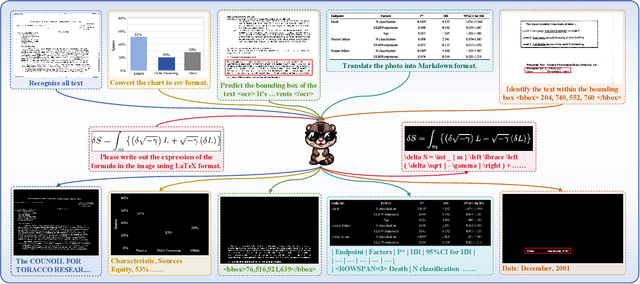
Multi-modal Large Language Models (MLLMs) have introduced a novel dimension to document understanding, i.e., they endow large language models with visual comprehension capabilities; however, how to design a suitable image-text pre-training task for bridging the visual and language modality in document-level MLLMs remains underexplored. In this study, we introduce a novel visual-language alignment method that casts the key issue as a Visual Question Answering with Mask generation (VQAMask) task, optimizing two tasks simultaneously: VQA-based text parsing and mask generation. The former allows the model to implicitly align images and text at the semantic level. The latter introduces an additional mask generator (discarded during inference) to explicitly ensure alignment between visual texts within images and their corresponding image regions at a spatially-aware level. Together, they can prevent model hallucinations when parsing visual text and effectively promote spatially-aware feature representation learning. To support the proposed VQAMask task, we construct a comprehensive image-mask generation pipeline and provide a large-scale dataset with 6M data (MTMask6M). Subsequently, we demonstrate that introducing the proposed mask generation task yields competitive document-level understanding performance. Leveraging the proposed VQAMask, we introduce Marten, a training-efficient MLLM tailored for document-level understanding. Extensive experiments show that our Marten consistently achieves significant improvements among 8B-MLLMs in document-centric tasks. Code and datasets are available at https://github.com/PriNing/Marten.