 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Transferable Temporal Primitives for Video Reasoning via Synthetic Videos
Mar 18, 2026The transition from image to video understanding requires vision-language models (VLMs) to shift from recognizing static patterns to reasoning over temporal dynamics such as motion trajectories, speed changes, and state transitions. Yet current post-training methods fall short due to two critical limitations: (1) existing datasets often lack temporal-centricity, where answers can be inferred from isolated keyframes rather than requiring holistic temporal integration; and (2) training data generated by proprietary models contains systematic errors in fundamental temporal perception, such as confusing motion directions or misjudging speeds. We introduce SynRL, a post-training framework that teaches models temporal primitives, the fundamental building blocks of temporal understanding including direction, speed, and state tracking. Our key insight is that these abstract primitives, learned from programmatically generated synthetic videos, transfer effectively to real-world scenarios. We decompose temporal understanding into short-term perceptual primitives (speed, direction) and long-term cognitive primitives, constructing 7.7K CoT and 7K RL samples with ground-truth frame-level annotations through code-based video generation. Despite training on simple geometric shapes, SynRL achieves substantial improvements across 15 benchmarks spanning temporal grounding, complex reasoning, and general video understanding. Remarkably, our 7.7K synthetic CoT samples outperform Video-R1 with 165K real-world samples. We attribute this to fundamental temporal skills, such as tracking frame by frame changes and comparing velocity, that transfer effectively from abstract synthetic patterns to complex real-world scenarios. This establishes a new paradigm for video post-training: video temporal learning through carefully designed synthetic data provides a more cost efficient scaling path.
CodePercept: Code-Grounded Visual STEM Perception for MLLMs
Mar 11, 2026When MLLMs fail at Science, Technology, Engineering, and Mathematics (STEM) visual reasoning, a fundamental question arises: is it due to perceptual deficiencies or reasoning limitations? Through systematic scaling analysis that independently scales perception and reasoning components, we uncover a critical insight: scaling perception consistently outperforms scaling reasoning. This reveals perception as the true lever limiting current STEM visual reasoning. Motivated by this insight, our work focuses on systematically enhancing the perception capabilities of MLLMs by establishing code as a powerful perceptual medium--executable code provides precise semantics that naturally align with the structured nature of STEM visuals. Specifically, we construct ICC-1M, a large-scale dataset comprising 1M Image-Caption-Code triplets that materializes this code-as-perception paradigm through two complementary approaches: (1) Code-Grounded Caption Generation treats executable code as ground truth for image captions, eliminating the hallucinations inherent in existing knowledge distillation methods; (2) STEM Image-to-Code Translation prompts models to generate reconstruction code, mitigating the ambiguity of natural language for perception enhancement. To validate this paradigm, we further introduce STEM2Code-Eval, a novel benchmark that directly evaluates visual perception in STEM domains. Unlike existing work relying on problem-solving accuracy as a proxy that only measures problem-relevant understanding, our benchmark requires comprehensive visual comprehension through executable code generation for image reconstruction, providing deterministic and verifiable assessment. Code is available at https://github.com/TongkunGuan/Qwen-CodePercept.
From Narrow to Panoramic Vision: Attention-Guided Cold-Start Reshapes Multimodal Reasoning
Mar 04, 2026The cold-start initialization stage plays a pivotal role in training Multimodal Large Reasoning Models (MLRMs), yet its mechanisms remain insufficiently understood. To analyze this stage, we introduce the Visual Attention Score (VAS), an attention-based metric that quantifies how much a model attends to visual tokens. We find that reasoning performance is strongly correlated with VAS (r=0.9616): models with higher VAS achieve substantially stronger multimodal reasoning. Surprisingly, multimodal cold-start fails to elevate VAS, resulting in attention distributions close to the base model, whereas text-only cold-start leads to a clear increase. We term this counter-intuitive phenomenon Lazy Attention Localization. To validate its causal role, we design training-free interventions that directly modulate attention allocation during inference, performance gains of 1$-$2% without any retraining. Building on these insights, we further propose Attention-Guided Visual Anchoring and Reflection (AVAR), a comprehensive cold-start framework that integrates visual-anchored data synthesis, attention-guided objectives, and visual-anchored reward shaping. Applied to Qwen2.5-VL-7B, AVAR achieves an average gain of 7.0% across 7 multimodal reasoning benchmarks. Ablation studies further confirm that each component of AVAR contributes step-wise to the overall gains. The code, data, and models are available at https://github.com/lrlbbzl/Qwen-AVAR.
Marten: Visual Question Answering with Mask Generation for Multi-modal Document Understanding
Mar 18, 2025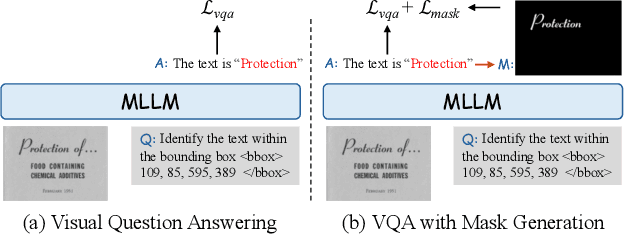
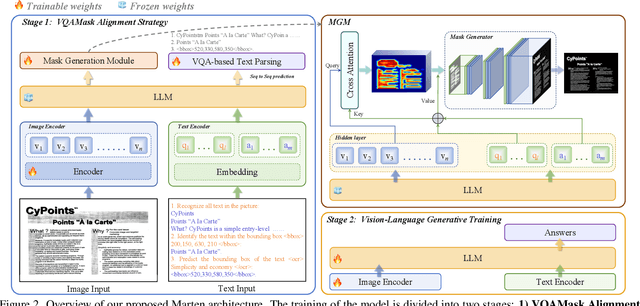
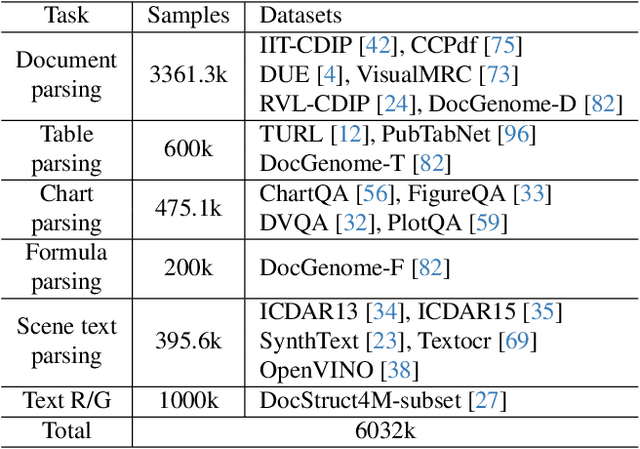
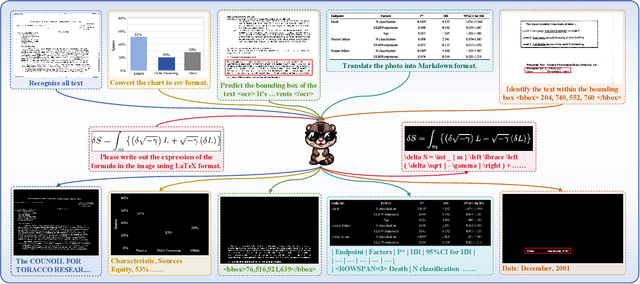
Multi-modal Large Language Models (MLLMs) have introduced a novel dimension to document understanding, i.e., they endow large language models with visual comprehension capabilities; however, how to design a suitable image-text pre-training task for bridging the visual and language modality in document-level MLLMs remains underexplored. In this study, we introduce a novel visual-language alignment method that casts the key issue as a Visual Question Answering with Mask generation (VQAMask) task, optimizing two tasks simultaneously: VQA-based text parsing and mask generation. The former allows the model to implicitly align images and text at the semantic level. The latter introduces an additional mask generator (discarded during inference) to explicitly ensure alignment between visual texts within images and their corresponding image regions at a spatially-aware level. Together, they can prevent model hallucinations when parsing visual text and effectively promote spatially-aware feature representation learning. To support the proposed VQAMask task, we construct a comprehensive image-mask generation pipeline and provide a large-scale dataset with 6M data (MTMask6M). Subsequently, we demonstrate that introducing the proposed mask generation task yields competitive document-level understanding performance. Leveraging the proposed VQAMask, we introduce Marten, a training-efficient MLLM tailored for document-level understanding. Extensive experiments show that our Marten consistently achieves significant improvements among 8B-MLLMs in document-centric tasks. Code and datasets are available at https://github.com/PriNing/Marten.
A Token-level Text Image Foundation Model for Document Understanding
Mar 04, 2025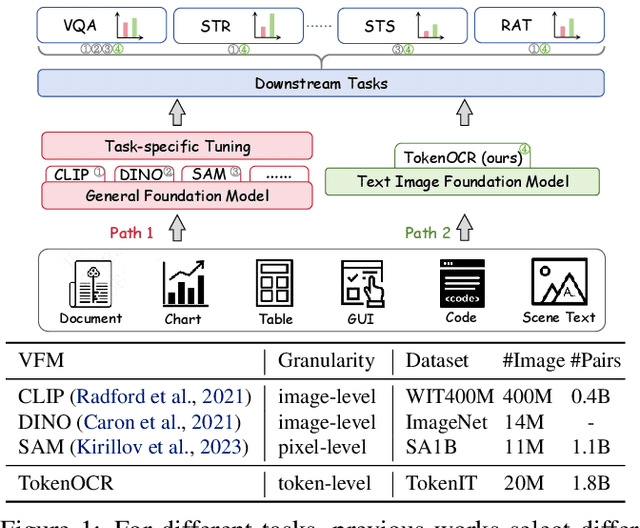
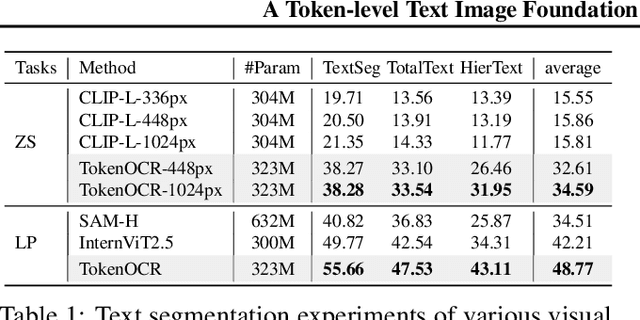
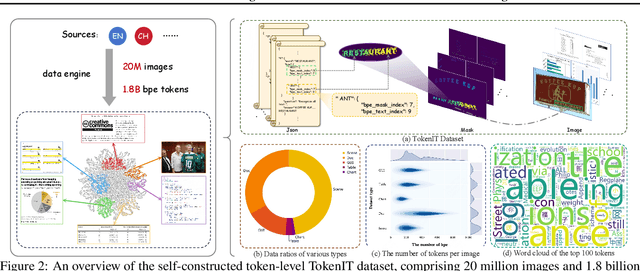
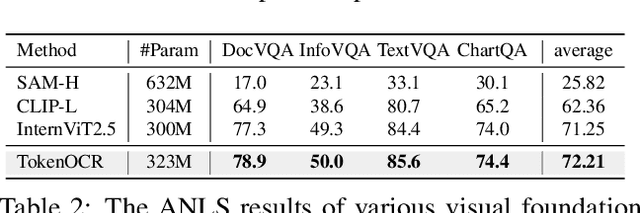
In recent years, general visual foundation models (VFMs) have witnessed increasing adoption, particularly as image encoders for popular multi-modal large language models (MLLMs). However, without semantically fine-grained supervision, these models still encounter fundamental prediction errors in the context of downstream text-image-related tasks, i.e., perception, understanding and reasoning with images containing small and dense texts. To bridge this gap, we develop TokenOCR, the first token-level visual foundation model specifically tailored for text-image-related tasks, designed to support a variety of traditional downstream applications. To facilitate the pretraining of TokenOCR, we also devise a high-quality data production pipeline that constructs the first token-level image text dataset, TokenIT, comprising 20 million images and 1.8 billion token-mask pairs. Furthermore, leveraging this foundation with exceptional image-as-text capability, we seamlessly replace previous VFMs with TokenOCR to construct a document-level MLLM, TokenVL, for VQA-based document understanding tasks. Finally, extensive experiments demonstrate the effectiveness of TokenOCR and TokenVL. Code, datasets, and weights will be available at https://token-family.github.io/TokenOCR_project.
Multimodal Large Language Models for Text-rich Image Understanding: A Comprehensive Review
Feb 23, 2025



The recent emergence of Multi-modal Large Language Models (MLLMs) has introduced a new dimension to the Text-rich Image Understanding (TIU) field, with models demonstrating impressive and inspiring performance. However, their rapid evolution and widespread adoption have made it increasingly challenging to keep up with the latest advancements. To address this, we present a systematic and comprehensive survey to facilitate further research on TIU MLLMs. Initially, we outline the timeline, architecture, and pipeline of nearly all TIU MLLMs. Then, we review the performance of selected models on mainstream benchmarks. Finally, we explore promising directions, challenges, and limitations within the field.
PosFormer: Recognizing Complex Handwritten Mathematical Expression with Position Forest Transformer
Jul 10, 2024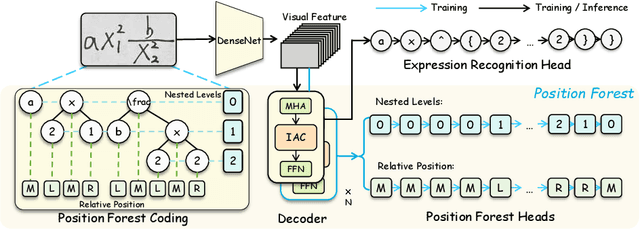
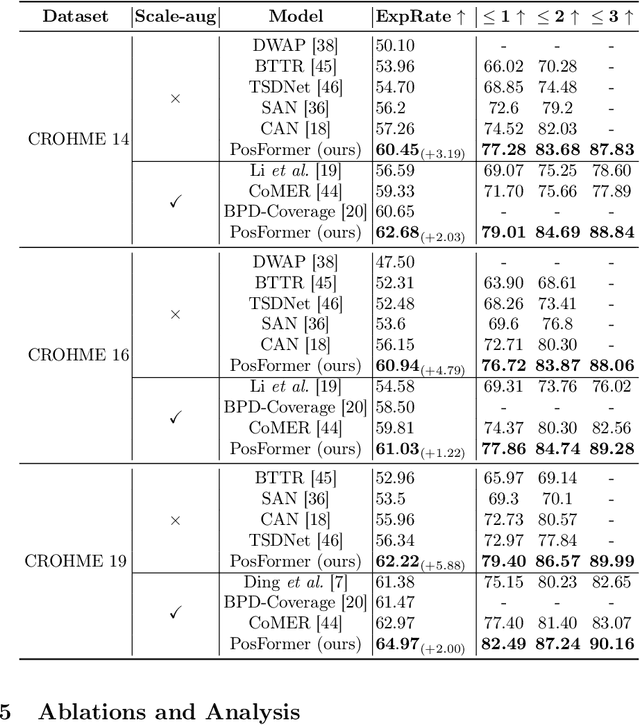
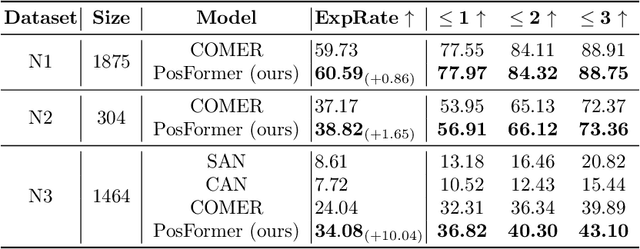

Handwritten Mathematical Expression Recognition (HMER) has wide applications in human-machine interaction scenarios, such as digitized education and automated offices. Recently, sequence-based models with encoder-decoder architectures have been commonly adopted to address this task by directly predicting LaTeX sequences of expression images. However, these methods only implicitly learn the syntax rules provided by LaTeX, which may fail to describe the position and hierarchical relationship between symbols due to complex structural relations and diverse handwriting styles. To overcome this challenge, we propose a position forest transformer (PosFormer) for HMER, which jointly optimizes two tasks: expression recognition and position recognition, to explicitly enable position-aware symbol feature representation learning. Specifically, we first design a position forest that models the mathematical expression as a forest structure and parses the relative position relationships between symbols. Without requiring extra annotations, each symbol is assigned a position identifier in the forest to denote its relative spatial position. Second, we propose an implicit attention correction module to accurately capture attention for HMER in the sequence-based decoder architecture. Extensive experiments validate the superiority of PosFormer, which consistently outperforms the state-of-the-art methods 2.03%/1.22%/2.00%, 1.83%, and 4.62% gains on the single-line CROHME 2014/2016/2019, multi-line M2E, and complex MNE datasets, respectively, with no additional latency or computational cost. Code is available at https://github.com/SJTU-DeepVisionLab/PosFormer.
Bridging Synthetic and Real Worlds for Pre-training Scene Text Detectors
Dec 08, 2023



Existing scene text detection methods typically rely on extensive real data for training. Due to the lack of annotated real images, recent works have attempted to exploit large-scale labeled synthetic data (LSD) for pre-training text detectors. However, a synth-to-real domain gap emerges, further limiting the performance of text detectors. Differently, in this work, we propose \textbf{FreeReal}, a real-domain-aligned pre-training paradigm that enables the complementary strengths of both LSD and unlabeled real data (URD). Specifically, to bridge real and synthetic worlds for pre-training, a novel glyph-based mixing mechanism (GlyphMix) is tailored for text images. GlyphMix delineates the character structures of synthetic images and embeds them as graffiti-like units onto real images. Without introducing real domain drift, GlyphMix freely yields real-world images with annotations derived from synthetic labels. Furthermore, when given free fine-grained synthetic labels, GlyphMix can effectively bridge the linguistic domain gap stemming from English-dominated LSD to URD in various languages. Without bells and whistles, FreeReal achieves average gains of 4.56\%, 3.85\%, 3.90\%, and 1.97\% in improving the performance of DBNet, PANet, PSENet, and FCENet methods, respectively, consistently outperforming previous pre-training methods by a substantial margin across four public datasets. Code will be released soon.
Self-supervised Character-to-Character Distillation
Nov 01, 2022Handling complicated text images (e.g., irregular structures, low resolution, heavy occlusion, and even illumination), existing supervised text recognition methods are data-hungry. Although these methods employ large-scale synthetic text images to reduce the dependence on annotated real images, the domain gap limits the recognition performance. Therefore, exploring the robust text feature representation on unlabeled real images by self-supervised learning is a good solution. However, existing self-supervised text recognition methods only execute sequence-to-sequence representation learning by roughly splitting the visual features along the horizontal axis, which will damage the character structures. Besides, these sequential-level self-learning methods limit the availability of geometric-based data augmentation, as large-scale geometry augmentation leads to sequence-to-sequence inconsistency. To address the above-mentioned issues, we proposed a novel self-supervised character-to-character distillation method, CCD. Specifically, we delineate the character structures of unlabeled real images by designing a self-supervised character segmentation module, and further apply the segmentation results to build character-level representation learning. CCD differs from prior works in that we propose a character-level pretext task to learn more fine-grained feature representations. Besides, compared with the inflexible augmentations of sequence-to-sequence models, our work satisfies character-to-character representation consistency, across various transformations (e.g., geometry and colour), to generate robust text features in the representative space. Experiments demonstrate that CCD achieves state-of-the-art performance on publicly available text recognition benchmarks.
A Glyph-driven Topology Enhancement Network for Scene Text Recognition
Mar 07, 2022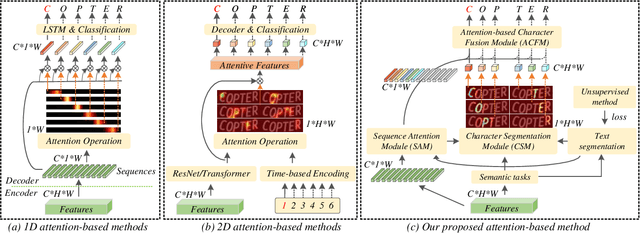
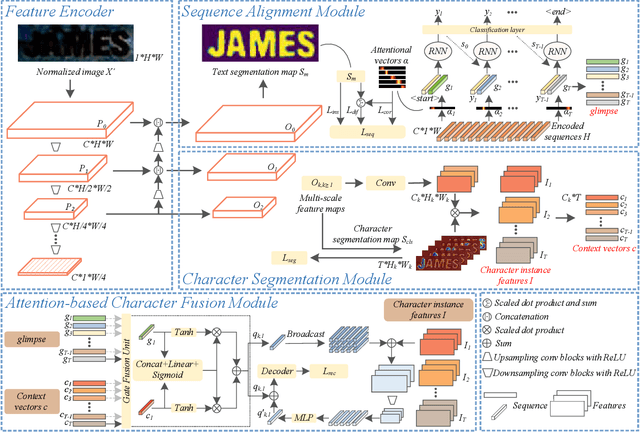
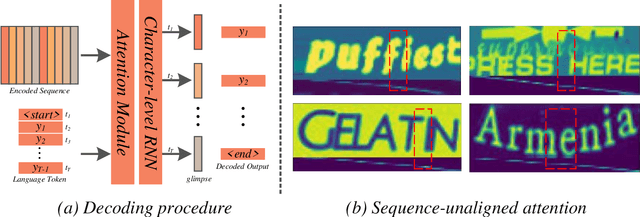

Attention-based methods by establishing one-dimensional (1D) and two-dimensional (2D) mechanisms with an encoder-decoder framework have dominated scene text recognition (STR) tasks due to their capabilities of building implicit language representations. However, 1D attention-based mechanisms suffer from alignment drift on latter characters. 2D attention-based mechanisms only roughly focus on the spatial regions of characters without excavating detailed topological structures, which reduces the visual performance. To mitigate the above issues, we propose a novel Glyph-driven Topology Enhancement Network (GTEN) to improve topological features representations in visual models for STR. Specifically, an unsupervised method is first employed to exploit 1D sequence-aligned attention weights. Second, we construct a supervised segmentation module to capture 2D ordered and pixel-wise topological information of glyphs without extra character-level annotations. Third, these resulting outputs fuse enhanced topological features to enrich semantic feature representations for STR. Experiments demonstrate that GTEN achieves competitive performance on IIIT5K-Words, Street View Text, ICDAR-series, SVT Perspective, and CUTE80 datasets.