 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Glyph-driven Topology Enhancement Network for Scene Text Recognition
Mar 07, 2022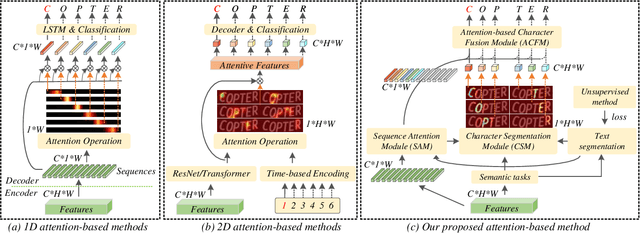
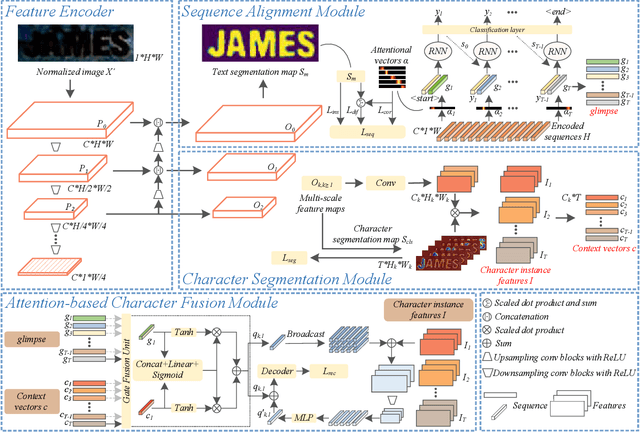
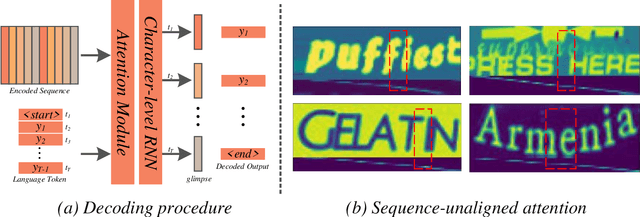

Attention-based methods by establishing one-dimensional (1D) and two-dimensional (2D) mechanisms with an encoder-decoder framework have dominated scene text recognition (STR) tasks due to their capabilities of building implicit language representations. However, 1D attention-based mechanisms suffer from alignment drift on latter characters. 2D attention-based mechanisms only roughly focus on the spatial regions of characters without excavating detailed topological structures, which reduces the visual performance. To mitigate the above issues, we propose a novel Glyph-driven Topology Enhancement Network (GTEN) to improve topological features representations in visual models for STR. Specifically, an unsupervised method is first employed to exploit 1D sequence-aligned attention weights. Second, we construct a supervised segmentation module to capture 2D ordered and pixel-wise topological information of glyphs without extra character-level annotations. Third, these resulting outputs fuse enhanced topological features to enrich semantic feature representations for STR. Experiments demonstrate that GTEN achieves competitive performance on IIIT5K-Words, Street View Text, ICDAR-series, SVT Perspective, and CUTE80 datasets.
Industrial Scene Text Detection with Refined Feature-attentive Network
Oct 25, 2021
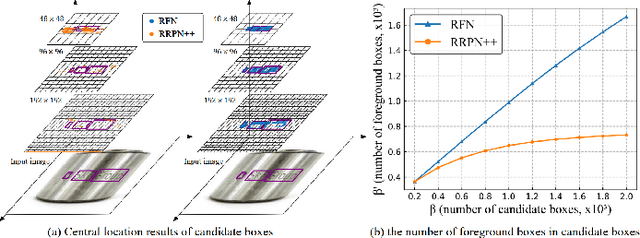


Detecting the marking characters of industrial metal parts remains challenging due to low visual contrast, uneven illumination, corroded character structures, and cluttered background of metal part images. Affected by these factors, bounding boxes generated by most existing methods locate low-contrast text areas inaccurately. In this paper, we propose a refined feature-attentive network (RFN) to solve the inaccurate localization problem. Specifically, we design a parallel feature integration mechanism to construct an adaptive feature representation from multi-resolution features, which enhances the perception of multi-scale texts at each scale-specific level to generate a high-quality attention map. Then, an attentive refinement network is developed by the attention map to rectify the location deviation of candidate boxes. In addition, a re-scoring mechanism is designed to select text boxes with the best rectified location. Moreover, we construct two industrial scene text datasets, including a total of 102156 images and 1948809 text instances with various character structures and metal parts. Extensive experiments on our dataset and four public datasets demonstrate that our proposed method achieves the state-of-the-art performance.
CANS: Communication Limited Camera Network Self-Configuration for Intelligent Industrial Surveillance
Sep 13, 2021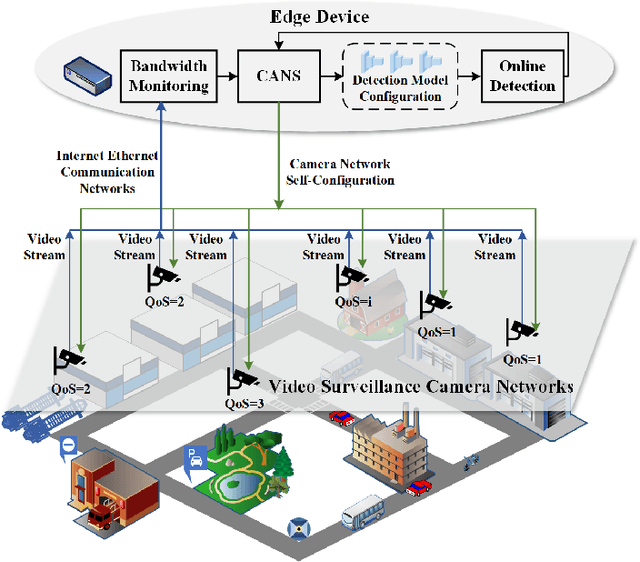
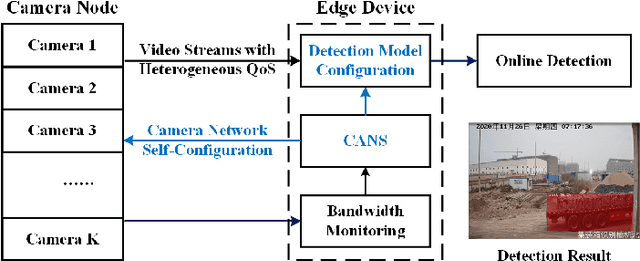

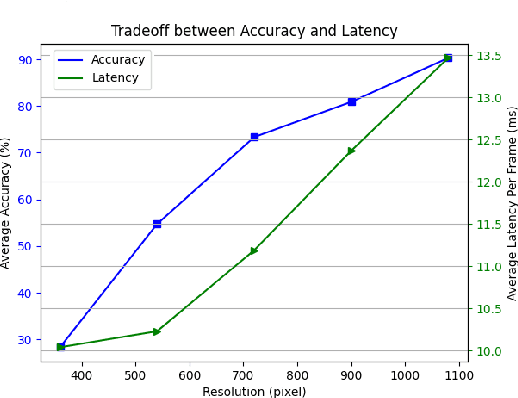
Realtime and intelligent video surveillance via camera networks involve computation-intensive vision detection tasks with massive video data, which is crucial for safety in the edge-enabled industrial Internet of Things (IIoT). Multiple video streams compete for limited communication resources on the link between edge devices and camera networks, resulting in considerable communication congestion. It postpones the completion time and degrades the accuracy of vision detection tasks. Thus, achieving high accuracy of vision detection tasks under the communication constraints and vision task deadline constraints is challenging. Previous works focus on single camera configuration to balance the tradeoff between accuracy and processing time of detection tasks by setting video quality parameters. In this paper, an adaptive camera network self-configuration method (CANS) of video surveillance is proposed to cope with multiple video streams of heterogeneous quality of service (QoS) demands for edge-enabled IIoT. Moreover, it adapts to video content and network dynamics. Specifically, the tradeoff between two key performance metrics, \emph{i.e.,} accuracy and latency, is formulated as an NP-hard optimization problem with latency constraints. Simulation on real-world surveillance datasets demonstrates that the proposed CANS method achieves low end-to-end latency (13 ms on average) with high accuracy (92\% on average) with network dynamics. The results validate the effectiveness of the CANS.
Attention-Aware Answers of the Crowd
Jan 07, 2020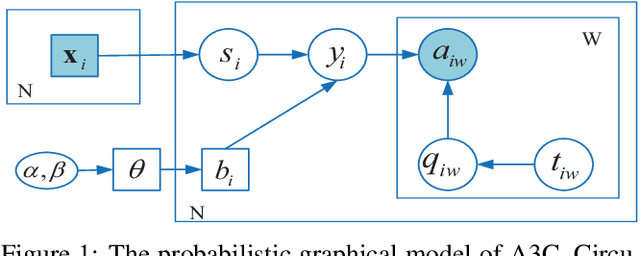

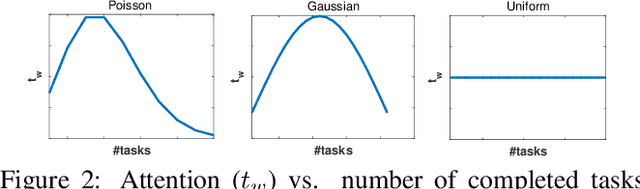

Crowdsourcing is a relatively economic and efficient solution to collect annotations from the crowd through online platforms. Answers collected from workers with different expertise may be noisy and unreliable, and the quality of annotated data needs to be further maintained. Various solutions have been attempted to obtain high-quality annotations. However, they all assume that workers' label quality is stable over time (always at the same level whenever they conduct the tasks). In practice, workers' attention level changes over time, and the ignorance of which can affect the reliability of the annotations. In this paper, we focus on a novel and realistic crowdsourcing scenario involving attention-aware annotations. We propose a new probabilistic model that takes into account workers' attention to estimate the label quality. Expectation propagation is adopted for efficient Bayesian inference of our model, and a generalized Expectation Maximization algorithm is derived to estimate both the ground truth of all tasks and the label-quality of each individual crowd worker with attention. In addition, the number of tasks best suited for a worker is estimated according to changes in attention. Experiments against related methods on three real-world and one semi-simulated datasets demonstrate that our method quantifies the relationship between workers' attention and label-quality on the given tasks, and improves the aggregated labels.