 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Clearly by Layer Two: Enhancing Attention Heads to Alleviate Hallucination in LVLMs
Nov 15, 2024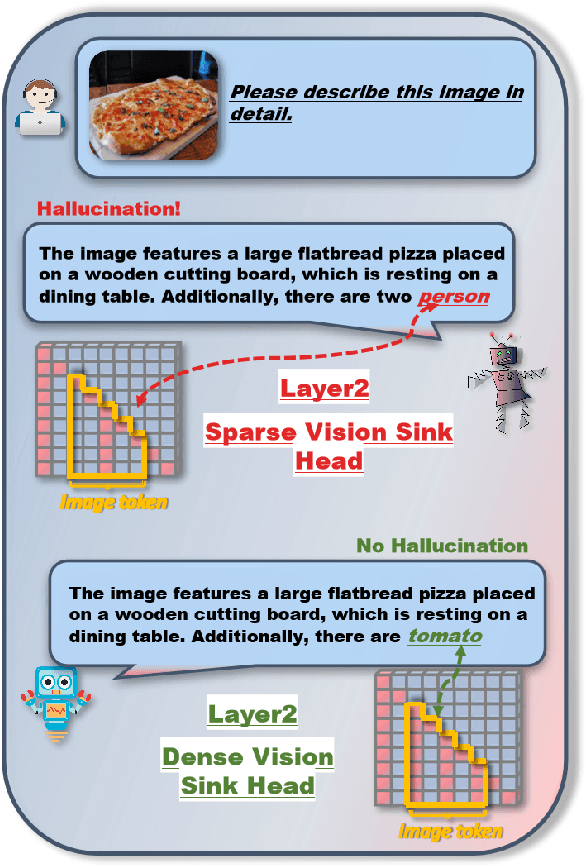
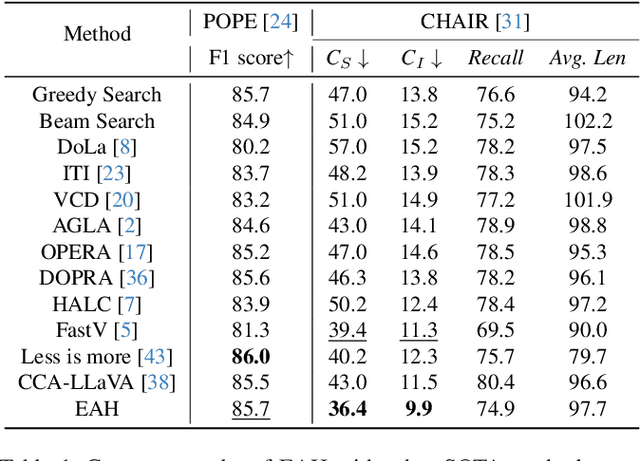
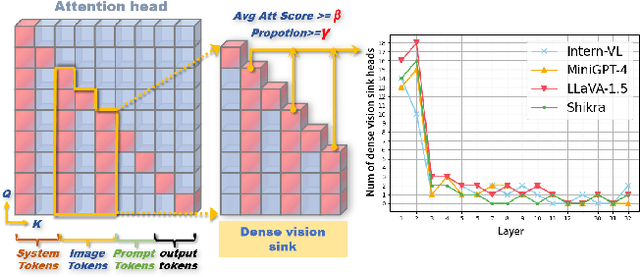
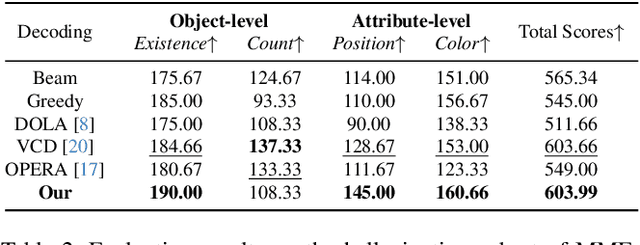
The hallucination problem in multimodal large language models (MLLMs) remains a common issue. Although image tokens occupy a majority of the input sequence of MLLMs, there is limited research to explore the relationship between image tokens and hallucinations. In this paper, we analyze the distribution of attention scores for image tokens across each layer and head of the model, revealing an intriguing and common phenomenon: most hallucinations are closely linked to the pattern of attention sinks in the self-attention matrix of image tokens, where shallow layers exhibit dense attention sinks and deeper layers show sparse attention sinks. We further analyze the attention heads of different layers and find that heads with high-density attention sink in the image part play a positive role in alleviating hallucinations. In this paper, we propose a training-free method named \textcolor{red}{\textbf{E}}nhancing \textcolor{red}{\textbf{A}}ttention \textcolor{red}{\textbf{H}}eads (EAH), an approach designed to enhance the convergence of image tokens attention sinks in the shallow layers. EAH identifies the attention head that shows the vision sink in a shallow layer and extracts its attention matrix. This attention map is then broadcast to other heads in the layer, thereby strengthening the layer to pay more attention to the image itself. With extensive experiments, EAH shows significant hallucination-mitigating performance on different MLLMs and metrics, proving its effectiveness and generality.
Industrial Scene Text Detection with Refined Feature-attentive Network
Oct 25, 2021
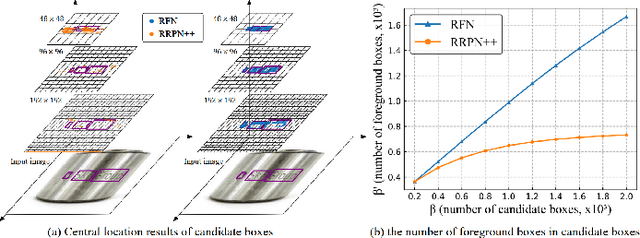


Detecting the marking characters of industrial metal parts remains challenging due to low visual contrast, uneven illumination, corroded character structures, and cluttered background of metal part images. Affected by these factors, bounding boxes generated by most existing methods locate low-contrast text areas inaccurately. In this paper, we propose a refined feature-attentive network (RFN) to solve the inaccurate localization problem. Specifically, we design a parallel feature integration mechanism to construct an adaptive feature representation from multi-resolution features, which enhances the perception of multi-scale texts at each scale-specific level to generate a high-quality attention map. Then, an attentive refinement network is developed by the attention map to rectify the location deviation of candidate boxes. In addition, a re-scoring mechanism is designed to select text boxes with the best rectified location. Moreover, we construct two industrial scene text datasets, including a total of 102156 images and 1948809 text instances with various character structures and metal parts. Extensive experiments on our dataset and four public datasets demonstrate that our proposed method achieves the state-of-the-art performance.